Pracovat s webovým formulářem na straně JavaScriptu se poměrně snadno
může stát očistcem. Nebo jak se nazývá ta věc na čištění záchodové
mísy. Přitom za všechno může jedno nešťastné rozhodnutí.
Mějme jednoduchý formulář
<form id=myform>
<input type=text name=query>
<input type=submit value="Vyhledat">
</form>
K jeho jednotlivým prvkům přistoupíme přes vlastnost
elements:
var form = document.getElementById('myform');
var query = form.elements.query.value;
// pochopitelně také form.elements['query'].value
A iterovat nad prvky lze cyklem for:
for (var i = 0; i < form.elements.length; i++) {
alert(form.elements[i].value);
}
Z historických důvodů lze vlastnost elements v příkladech
vynechat, neboť jednotlivé prvky se mapují přímo do objektu
form. Takže by fungovalo i form.query.value,
form.length nebo form[i].value. Což se záhy ukáže
jako nemilé. Formulářové prvky totiž přepisují nativní
metody a proměnné objektu form. Například metoda submit(),
která je klíčová pro AJAXové odeslání formuláře, se stane nedostupnou,
pokud formulář obsahuje prvek nazvaný submit. A uznejte, že to
je zrovinka název pro odesílací tlačítko jako dělaný. Pokud by tedy
formulář vypadal takto
<form id=myform>
<input type=text name=query>
<input type=submit name=submit value="Vyhledat">
</form>
nebude jej možné příkazem form.submit() odeslat, místo toho
JavaScript zařve „form.submit is not a function“ a má pravdu,
form.submit není funkce ale objekt HtmlInputElement. Dobrá, dáme
si pozor a nebudeme formulářové prvky nazývat submit.
(prozradím trik, jak by formulář šlo odeslat i v tomto případě:
document.createElement('form').submit.call(form))
Jenže název submit není tím jediným, kterému se musíme
vyhnout. Prvek pojmenovaný elements způsobí, že
form.elements nebude očekávaná kolekce a výše uvedené
příklady skončí chybou. Název length zase znemožní nad
kolekcí iterovat. A tak by se dalo pokračovat, nativních prvků třeba DOM
Firefoxu definuje hodně přes stovku. Pro zajímavost uvádím seznam jen těch
jednoslovných (tj. vynechávám nodeName nebo
innerHTML):
action, attributes, blur, children, dir, draggable, elements, encoding,
enctype, focus, id, lang, length, method, name, normalize, prefix, reset,
spellcheck, style, submit, target, title
Bylo by skvělé, kdyby se HTML5 dokázalo s tímto nešvarem vypořádat.
Zatím jsem ve specifikaci nic takového nenašel.
Podobně mi chybí možnost, jak v obsluze události onsubmit
zjistit, kterým tlačítkem byl formulář odeslán. Triviální a užitečná
věc a jak složitě se musí řešit.
<form id=myform onsubmit="kterým tlačítkem byl odeslán?">
<input type=hidden name=id value="123">
<input type=submit name=save value="Uložit">
<input type=submit name=delete value="Smazat">
</form>
Řeším to tak, že odchytávám událost click jednotlivých
tlačítek a název prvku ukládám do vlastní proměnné formuláře. O něco
jednodušší je využít bublání a odchytávat click přímo na
formuláři. Nicméně v HTML5 tohle už nebude fungovat spolehlivě, protože
prvek může být umístěn i mimo strom formuláře a přiřazen k němu
atributem form. Bylo by tedy fajn, kdyby HTML5 zavedlo vlastnost
například form.submitter, který by vracela název
odesílajícího tlačítka.
p. s. Nette Framework s těmito
situacemi počítá a snaží se je v rámci možností řešit za
programátora
Poslyšte příběh: klient si přál učinit svůj web hezčím a tak
jsem mu doporučil jednoho z těch mála dobrých tuzemských grafiků. Před
pár dny jsme měli schůzku a on se svěřil, že už dostal od grafika návrh
a není z něj gór šťastný. Že písmo je moc malé a celé je to jakési
kostrbaté. Nějak se mi to nezdálo, poprosil jsem ho, aby návrh otevřel, že
se na to podíváme. Dohledal email, odkliknul obrázek a naběhl mu výchozí
prohlížeč obrázků ve Windows. A protože obrázek měl větší rozměry,
zobrazil se (mírně) zmenšený. A hned bylo jasné, kde je
zakopaný pes.
Pokud klient není expert, nemá šanci zjistit, že se dívá na obrázek
zdeformovaný zmenšením. Prohlížeč obrázků ve Windows XP nebo Vista na to
nijak neupozorní. Ba co víc – i kdyby to zaregistroval, nejspíš se mu
nepodaří obrázek zvětšit na plnou velikost. Alespoň kolečkem myši nebo
klávesami + - to nejde. Ty obrázek
zvětšují/zmenšují o 20 % a hranici 100 % bez zastavení přeskočí.
Zobrazit jej v měřítku 1:1 vyžaduje fištróna.
Z příběhu vyplývá velmi cenná a nejspíš překvapivá zkušenost:
neposílejte klientům náhledy webů jako obrázek.
Jak tedy náhledy posílat? Nejvhodnější je klientovi poslat URL. Design
tak uvidí v kontextu webového prohlížeče a bude mít daleko ucelenější
dojem. Ale pozor, pokud byste poslali přímo URL obrázku, prohlížeč by jej
opět zmenšil. Je nad ním potřeba vytvořit HTML obálku. Nahrejte proto na
web kromě obrázku ještě soubor nahled.php:
<title>Náhled webu</title>
<body style="margin:0; text-align:center">
<img src="<?php echo htmlSpecialChars($_SERVER['QUERY_STRING']) ?>">
</body>
Potom např. obrázek pala.png bude dostupný pod URL
http://example.com/nahled.php?pala.png. Tu pošlete klientovi a
učiníte přítrž možným nedorozuměním.
Na závěr ještě tři tipy:
- udělejte obrázek dostatečně široký a výsoký, nebo vhodně nastavte
pozadí, aby nebylo vidět bílé pozadí prohlížeče
- náhled ukládejte zásadně jako 24bitový PNG
- ponechte v kódu element
img, zobrazením pomocí CSS stylu
background zkomplikujete klientovi tisk
Na posledním školení jsme
narazili na zajímavost HTML, která mě (v tu chvíli nepříjemně)
překvapila.
Podívejte se na následující kus kódu. Vyskočí okénko se zprávou
Barnes & Noble nebo Barnes & Noble?
<body>
<h1>Barnes & Noble test</h1>
<script>
alert('Barnes & Noble');
</script>
</body>
Máte tip? Tak si ho ověřte. Zajímavé
přitom je, že pokud bychom entitu nepoužili, bude výsledek nevalidní.
Nedávno jsem se zúčastnil diskuse, která mi (opět)
připomněla, jak silně jsou u nás zakořeněné mýty týkající se
rozdílů mezi HTML a XHTML. Kampaň za formáty s písmenem X doprovázely
velké emoce a ty obvykle nechodí ruku v ruce s čistou hlavou. Sice
nadšení dávno opadlo, ale značná část odborné veřejnosti i autorit
dosud věří celé řadě bludů.
Pokusím se tímto článkem ty největší z nich pohřbít. A to
následujícím způsobem. Tento článek bude obsahovat pouze a jen
fakta. Své názory i vaše komentáře si nechám až na
článek druhý.
V následujícím textu pod termínem HTML rozumím verzi HTML 4.01, pod XHTML verzi XHTML 1.0 Second Edition. Pro úplnost
dodávám, že HTML je aplikací jazyka SGML,
zatímco XHTML je aplikací jazyka XML.
Mýtus: v HTML je
povolené křížení značek
Nikoliv. Křížení značek je zakázáno přímo v SGML, důsledkem
čehož i v HTML. Tento fakt je zmíněn například v doporučení W3C:
„…overlapping is illegal in SGML…“. Všechny tyto značkovací
jazyky chápou dokument jakožto stromovou strukturu, a právě proto není
možné značky křížit.
Zároveň tak reaguji i na reformulaci mýtu: „Výhodou XHTML je zákaz
křížení značek“. Není tomu tak, značky nelze křížit v žádné
existující verzi HTML nebo XHTML.
Mýtus:
XHTML zakázalo prezentační elementy a zavedlo CSS
Nikoliv. XHTML obsahuje tutéž sortu elementů, jako má HTML 4.01. Je to
zmíněno hned v prvním
odstavci XHTML specifikace: „Význam elementů a jejich atributů je
definován v doporučení W3C pro HTML 4“. Z tohoto pohledu mezi XHTML
a HTML žádný rozdíl neexistuje.
Některé elementy a atributy byly zapovězené (deprecated) již v HTML 4.01.
Prezentační elementy se tu zapovídají právě ve prospěch CSS, což je
také odpověď na druhou část mýtu: příchod kaskádových stylů s XHTML
nesouvisí, odehrál se již dříve.
Mýtus: HTML parser
musí tipovat konce značek
Nikoliv. V HTML je možné u definované skupiny
elementů volitelně neuvádět koncovou nebo počáteční značku. Jde
o elementy, u kterých vypuštění značky nemůže způsobit
nejasnost. Jako příklad si můžeme vzít koncovou značku u elementu
p. Jelikož norma říká, že se odstavec nemůže nacházet
uvnitř jiného odstavce, je v případě zápisu…
<p>....
<p>....
…jednoznačně dáno, že otevřením druhého odstavce se musí uzavřít
ten první. Uvedení koncové značky je tedy redundantní. Naopak třeba
element div může být zanořený sám v sobě, proto u něj je
počáteční i koncová značka povinná.
Mýtus: zápis
atributů v HTML je nejednoznačný
Nikoliv. XHTML vždy vyžaduje uzavírat hodnoty atributů do uvozovek nebo
apostrofů. HTML to vyžaduje
také, s výjimkou, pokud hodnotu tvoří alfanumerický řetězec. Pro
úplnost dodám, že i v těchto případech specifikace doporučuje
uvozovky užít.
Tedy v HTML je přípustné zapsat
<textarea cols=20 rows=30>, což je formálně stejně
jednoznačné, jako <textarea cols="20" rows="30">. Pokud by
hodnota obsahovala více slov, HTML trvá na užití uvozovek.
Mýtus: HTML dokument je
nejednoznačný
Nikoliv. Jako důvod nejednoznačnosti se uvádí buď možnost křížení
značek, nejednoznačnost zápisu atributů bez uvozovek, což jsou již
vyvrácené mýty, nebo také možnost některé značky vynechávat. Tady
zopakuji, že skupina elementů, u kterých je možné značky vynechávat, je
zvolena tak, aby se vynechala pouze redundantní informace.
HTML dokument je tedy vždy jednoznačně určen.
Mýtus: až v XHTML se
píše znak & entitou &
Nikoliv – musí se tak psát i v HTML. Pro oba jazyky mají znaky
< a & specifický význam. První otevírá
značku a druhý entitu. Aby nebyly chápány v jejich meta-významu, musí se
zapsat entitou. Tedy i v HTML, jak uvádí specifikace.
Mýtus:
HTML dovoluje ‚prasárny‘, které Vám v XHTML neprojdou
Nikoliv. Tento názor má kořeny v řadě mýtů, které už jsem vyvrátil
výše. Ještě jsem nezmínil, že XHTML u jmen elementů a atributů na
rozdíl od HTML rozlišuje velikost písmen (je „case sensitive“). Nicméně
jde o zcela legitimní vlastnost jazyka. Takto se liší například Visual
Basic od C# a nelze objektivně říci, že jeden nebo druhý přístup by byl
horší. HTML kód je možné znepřehlednit tím, že budeme nevhodně
střídat velká a malá písmena (<tAbLe>), XHTML kód
zase třeba používáním řetězců abc, AbC,
aBC pro odlišné třídy XML kód zase třeba používáním
řetězců id, ID, Id pro odlišné
atributy.
Čistota zápisu v žádném případě nesouvisí s volbou jednoho nebo
druhého jazyka.
Mýtus: Parsování XHTML je
mnohem snazší
Nikoliv. Srovnání na miskách vah by bylo subjektivní, a tedy nemá
v tomto článku místo, objektivně však lze prohlásit, že není žádný
důvod, proč by jeden z parserů měl mít výrazně jednodušší život.
Každý z nich má na krku jiný balvan.
Parsování HTML je podmíněno faktem, že parser musí znát definici typu
dokumentu. Prvním důvodem je existence volitelných značek. Ačkoliv je
jejich doplňování jednoznačné (viz výše) a algoritmicky snadno
řešitelné, tak parser musí příslušnou definici znát. Druhým důvodem
jsou prázdné elementy. Že je element prázdný ví parser pouze
z definice.
Parsování XHTML je zase ztíženo tím, že dokument může (na rozdíl od
HTML) obsahovat interní podsadu DTD s definicí vlastních entit (viz příklad). Raději
dodávám, že „entita“ nemusí představovat jeden znak, ale libovolně
dlouhý úsek XHTML kódu (obsahující případně další entity). Bez
zpracování DTD a ověření jeho správnosti vůbec nelze o parsování XHTML
hovořit. Věc navíc zkomplikuje to, že syntakticky je DTD v podstatě
protipólem jazyka XML.
Shrnuto: jak HTML tak XHTML parser musí znát definici typu dokumentu. XHTML
parser ji navíc musí umět číst v DTD jazyce.
Mýtus: Parsování XHTML
je mnohem rychlejší
Z hlediska syntaktické podobnosti obou jazyků je rychlost parsování
dána pouze šikovností programátorů jednotlivých parserů. Čas potřebný
pro strojové zpracování běžné webové stránky (ať už HTML nebo XHTML)
na běžném počítači je lidským vnímáním nepostřehnutelný.
Mýtus: HTML parser si musí
vždy poradit
Nikoliv. Specifikace HTML nenařizuje,
jak se má aplikace zachovat v případě zpracování chybného dokumentu.
Z důvodu konkurenceschopnosti v reálném prostředí došlo k tomu, že
prohlížeče se staly zcela tolerantní k vadným HTML dokumentům.
Jinak je tomu v případě XHTML. Specifikace odvoláním na XML nařizuje,
že parser v případě chyby nesmí pokračovat v dalším zpracování
logické struktury dokumentu. Opět z důvodu konkurenceschopnosti v reálném
světě došlo k tomu, že RSS čtečky se staly tolerantní k vadným XML
dokumentům (RSS je aplikací XML, stejně jako XHTML).
Pokud bychom chtěli z tolerantnosti webových prohlížečů něco
negativního usuzovat o HTML, pak nutně musíme z tolerantnosti RSS čteček
něco negativního usuzovat o XML. Objektivně lze shrnout, že drakonický přístup XML
k chybám v dokumentech je utopistický.
Závěr?
Pokud už nemáte mysl zatíženou žádným z výše uvedených mýtů,
můžete mnohem lépe vnímat rozdíl mezi HTML a XHTML. Lépe řečeno můžete
lépe vnímat, že tam žádný rozdíl není. Skutečný rozdíl se odehrává
až o patro výše: je jím opuštění SGML a přechod k novému XML.
Bohužel nelze říci, že XML pouze řeší problémy SGML a žádné nové
nepřidává. Jen v tomto článku jsem na dva narazil. Jedním z nich je
drakonické zpracování chyb v XML, které není v souladu s praxí, a tím
druhým je existence odlišného jazyka DTD uvnitř XML, které komplikuje
parsování i srozumitelnost XML dokumentů. Navíc vyjadřovací schopnost
tohoto jazyka je tak malá, že nedokáže formálně postihnout ani samotné
XHTML, takže některé vlastnosti je nutné dodefinovat zvlášť.
U jazyka, který není svázán historickými okovy, je to smutné a
zarážející zjištění. Kritika XML je však téma na samostatný
článek.
(Pokud narazím na další mýty, budu článek postupně doplňovat.
Budete-li chtít na ně odkazovat, můžete využít toho, že jednotlivé
titulky mají vlastní ID)
Jak účinně zamaskovat e-maily před zraky spamových
robotů? To měl zjistit půlroční experiment. Jenže výsledky jsou docela
překvapivé.
Trocha teorie
Důležitým zdrojem, kde spammeři získávají e-mailové adresy, jsou
webové stránky. Těmi procházejí roboti a adresy hromadně extrahují. Proto
se doporučuje zapisovat e-maily ve formě pochopitelné člověku, avšak
nepochopitelné stroji. Například ve tvaru
franta (at) example.cz. Jenže i tento zápis může některým
lidem připadat matoucí, naopak robot se mu může přizpůsobit. Proto se
vymýšlejí stále sofistikovanější způsoby, jak adresu zakamuflovat
(klíčové slovo: obfuscate email).
V této souvislosti se pochlubím s nápadem, jak neviditelně zastřít
e-mail pomocí HTML komentáře.
Použil jsem ho v Texy2 a nahradil jím méně přístupné (at) zavináče z Texy 1.
Jenže je otázka, jak chytří spamoví roboti skutečně jsou? Který
způsob maskování je dostatečný? Proč to nevyzkoušet.
Roboti pod lupou
Jako pokusného králíka jsem použil tento blog. GTPR 6 a cca
350 stránek obsahu by mělo škodnou přilákat.
Protože jsem od robotů žádné zázraky nečekal, nejprve jsem ověřil,
jestli vůbec převádějí HTML entity na znaky
(v řeči PHP: zavolají html_entity_decode). Pokud by je
totiž zmátlo primitivní používání entit, nemusel bych
experimentovat dál.
Na všechny stránky La Trine jsem na půl roku umístil skryté
pastičky:
// 1) nechráněná e-mailová adresa v textu stránky
<a href="mailto:foo">test@example.com</a>
// 2) nechráněná e-mailová adresa jako odkaz
<a href="mailto:test@example.com">foo</a>
// 3) "mailto:" chráněné HTML entitami
<a href="mailto:test@example.com">foo</a>
// 4) zavináč chráněný HTML entitou
<a href="mailto:test@example.com">foo</a>
// 5) kombinace bodů 3) a 4)
<a href="mailto:test@example.com">foo</a>
Test ukázal, že náhrada zavináče HTML entitou je zcela dostačující
ochranou. Po půl roce dorazily jen tři spamy! A to ještě mohl mít na
svědomí slovníkový útok.
Tím bych mohl článek ukončit. Nejlepší prevence se jmenuje
@. Jenže…
Skutečné zdroje e-mailových
adres
Jak jsem zmínil, do pastiček č. 4 a 5 spadly jen tři spamy. Návnady
č. 2 a 3 přilákaly 85 kousků a
prim pochopitelně drží zcela nechráněný e-mail se 126 zářezy.
Jenže, 126 spamíků za půl roku je nějak podezřele málo. Do mé
schránky jich víc dorazí za jediný den! Jak je to možné?
Po pravdě, netuším. Nejspíš se webové stránky staly zcela okrajovým
zdrojem e-mailových adres. Spameři už loví jinde. Možná se zaměřují na
malware, který šíří do
cizích počítačů. Záškodnický program pak sám rozesílá spam a
e-mailové adresy čerpá z poštovních klientů (adresář + doručená
pošta). Nebo je to úplně jinak…
Související:
Všechno je jinak. Ti, co měli pravdu, nám lhali, zatímco
kacíři to s námi mysleli dobře.
Prolog
Začátkem letošního roku napsal Chamurappi na Lupu poměrně neaktuální
článek Soumrak nad
moderním X. Má smysl ještě dnes vyvracet dávno vyvrácené mýty
o XHTML? Ptal jsem se sám sebe. K mému překvapení se pod článkem
rozhořela plamenná diskuse plná emotivních výkřiků, které mě vrátily
do dob nejtvrdší evangelizace. Pochopil jsem, že za ty roky mýty spíš
zakořenily.
Laikům budiž odpuštěno. Jenže v oné diskusi dostala také řada
osobností domácího webdesignu příležitost se historicky znemožnit. Dostala a využila. Přiznám se,
že jsem to dlouho nemohl rozdýchat. S odstupem času to vnímám jako
důležitou životní zkušenost.
Dějství první
Jak se blížilo desetileté výročí vývojového patu XHTML & CSS,
přemýšlel jsem, jak k němu vůbec mohlo dojít. Jak je možné, že
v době neomezené celosvětové komunikace není lidstvo schopno
řešit technické záležitosti? Vlastně celkem banální. Co je HTML markup
proti sestavení vesmírné rakety? Neschopnost řešit humanitní problémy je
pochopitelná, ale i technické?
 Získal jsem pocit, že
hlavní mozky W3C trpí syndromem mrtvého
koně. Cválají dál na oři jménem XHTML a nechtějí si připustit, že
už je napůl v salámu. Že drakonickým pravidlům XML specifikace nelze
v reálném světě dostát. Že DTD má příliš slabé vyjadřovací
schopnosti, přičemž umí spoustu věcí značně zkomplikovat. Ale hlavně,
že autorům webových stránek slavné XHTML vůbec nic nedalo. Ačkoliv
touží po tolika nových vlastnostech, počínaje lepšími formuláři, konče
třeba elementem pro video.
Získal jsem pocit, že
hlavní mozky W3C trpí syndromem mrtvého
koně. Cválají dál na oři jménem XHTML a nechtějí si připustit, že
už je napůl v salámu. Že drakonickým pravidlům XML specifikace nelze
v reálném světě dostát. Že DTD má příliš slabé vyjadřovací
schopnosti, přičemž umí spoustu věcí značně zkomplikovat. Ale hlavně,
že autorům webových stránek slavné XHTML vůbec nic nedalo. Ačkoliv
touží po tolika nových vlastnostech, počínaje lepšími formuláři, konče
třeba elementem pro video.
Pak jsem si uvědomil, že onou neschopností netrpí jen W3C. Dnes a denně
jsme obětí jiné neschopnosti – neschopnosti vylepšit e-mailový protokol
a zbavit se tak tun spamu. A podobných příkladů lze najít celou řadu.
Začalo mi docházet, že problémem ve stáji W3C nebude zesnulý hřebec. Oči
mi otevřela zmíněná diskuse na Lupě. Problémem je komunikace. Tedy
příliš mnoho komunikace. Komunikující komunita. Největší význam pro
rozvoj civilizace má jedinec. Komunita je mor.
První verzi HTML vymyslel jeden chytrej chlap. Jakmile se dalo dohromady
hodně chytrejch chlapů, dopadlo to prachbídně.
Poznámka: jak začnete úvahy rozvíjet dál, zpochybníte si
i principy demokracie. Dnes je mi hodně blízký Aristoteles a sympatizuji
s jeho třemi
právními formami státu.
Dějství druhé
Kupodivu i v oboru webdesignu se našel jednotlivec s ambicemi spasit
HTML. Ian Hixie Hickson se pro mě stal jiskřičkou na konci tunelu, a
to i přesto, že s mnoha jeho názory se neztotožňuji. Jenže, je chytrej,
má obrovské zkušenosti a hlavně – je to jednotlivec  Holt komunitám
nevěřím. Teď, v době Webu 2.0
Holt komunitám
nevěřím. Teď, v době Webu 2.0
A pak se to stalo! Pak to bouchlo! V květnu W3C
adoptovalo HTML 5, vypiplané dítě Iana Hicksona. Mezi řádky lze číst,
že tím vlastně odpískalo projekt XHTML. Nikdo to nahlas neřekne.
Ještě před pár lety se na HTML vs. XHTML vypisovaly kurzy přesně
opačné. Neuvěřitelné se stalo skutečností.
(pro srandu králíkům, srovnejte úroveň diskusí pod oběma
odkazovanými články na Lupě)
Epilog
 Chamurappi může
prožívat obrovskou satisfakci. Dlouhé roky upozorňoval na vady
X-specifikací a byl za to nelichotivě častován. A najednou mu historie,
jindy tak nespravedlivá, dala za pravdu. Vlastně se divím, že na Webylonu
letošní převrat vůbec nereflektoval. Mohl napsat: „já vám to celou tu
dobu říkal, vy pitomci.“ Měl by na to právo.
Chamurappi může
prožívat obrovskou satisfakci. Dlouhé roky upozorňoval na vady
X-specifikací a byl za to nelichotivě častován. A najednou mu historie,
jindy tak nespravedlivá, dala za pravdu. Vlastně se divím, že na Webylonu
letošní převrat vůbec nereflektoval. Mohl napsat: „já vám to celou tu
dobu říkal, vy pitomci.“ Měl by na to právo.
Je docela zvláštní, že o novém svěžím větru informuje
pouze Martin Hassman. Nu což, dělá
to výborně. Také mám v plánu o HTML 5 občas psát. Z toho téma sálá
nadšení a pocit naděje.
Jo, a co na to Daniel Dočekal? Inu, jako
vždy
As you might know, web forms have to by styled with care, since
their native look often is the best you can achieve.
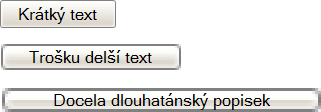
That said, sometimes even default look has its bugs. A truly flagrant
mistake concerns buttons in Internet Explorer (including version 7) in Windows
XP. If the button's caption is too long, the browser produces such a
nasty thing:
…pokračování
Jak již víte, webové formuláře je potřeba stylovat opatrně, protože
už jejich nativní podoba bývá často tím nejlepším, čeho lze
dosáhnout.
Někdy má ale i výchozí podoba své mouchy. V komentářích
k předchozímu článku se jako problematické ukázalo
zarovnání checkboxů s popisky ve Firefoxu. Skutečně hrubá chyba se však
týká tlačítek v Internet Exploreru (včetně verze 7) pod Windows XP. Je-li
popisek na tlačítku dlouhý, vyčaruje prohlížeč takový zlý,
nepěkná věc:
(vyzkoušejte
si)
Jde o kombinaci hned dvou chyb:
- tlačítka jsou zbytečně moc široká
- velká tlačítka se vykreslí zubatě a divně
S druhou chybou asi nic udělat nepůjde. To je prostě chyba ve
vykreslovacím jádře prohlížeče a lze ji leda reportovat vývojářům a
doufat, že třeba někdy…
Zajímavé je, že čím je tlačítko širší, tím ošklivěji se
vykreslí. Takže vyřešením první chyby, tj. donucením Exploreru, aby
tlačítka zúžil na odpovídající šířku, by se měl zmírnit či dokonce
odstranit i efekt zubatého vykreslení. Uvidíme.
Zužujeme tlačítko
Pokusy nastavit různé hodnoty pro width nebo
padding k ničemu nevedly. V takové chvíli se webdesigner
uchýlí ke střelbě naslepo v podobě experimentování s CSS vlastnostmi
jako display, overflow, position atd. Ukázalo se, že nápravu
sjedná overflow: visible. Pak ale tlačítko těsně obepíná
popisek, takže je záhodno ještě doplnit padding.
input.button {
padding: 0 .3em;
overflow: visible;
}
A vidíte? Zúžení tlačítek zcela eliminovalo vykreslovací vadu
u druhého z nich, v případě třetího ji alespoň zmírnilo.
Pocit vítězství nad digitálním nepřítelem jsem si vychutnával
přesně do chvíle, než jsem formulář s dlouhým tlačítkem naformátoval
do tabulky a ejhle:
Ačkoliv se tlačítka vykreslují se správnou šířkou, v tabulce
zabírají své původní místo. Problém vyřeší width:0.
Jenže lepší prohlížeče (Opera, Firefox) nulovou šířku skutečně
respektují, je tedy nutné použit IE-only hack. A to už je známá pohádka.
Buď dát za vděk vylepšenému „podtržítkovému hacku“, tedy
=width:0 (pro IE7 je nutné podtržítko zaměnit například za
rovnítko), nebo oddělit styl pro IE pomocí podmíněných komentářů.
Zabrousil jsem na Google a pokusil se najít jiná řešení. Stejný zápas
absolvoval jistý Jehiah Czebotar a po třech kolech s pomocí čtenářů
došel k velmi podobnému
výsledku, ale s jednou elegantní fintou navíc!
Zde je řešení:
/* chyba roztazenych tlacitek v IE pod WinXP */
input.button {
padding: 0 .25em;
width: 0; /* pouze pro IE */
overflow: visible;
}
input.button[class] { /* IE ignoruje [class] */
width: auto;
}
Finta spočívá v odlišení lepších prohlížečů od IE7
validní cestou. Díky tomu není potřeba „rovnítkový hack“ ani extra
soubor se stylem. Kód tedy můžete použít pro všechny
prohlížeče. Enjoy!
Související:
Před nějakou dobou jsem naznačoval, jak dokonale nastylovat
webový formulář. Pointou bylo, že formuláře je nejlépe nestylovat
vůbec. Nechat je vykreslit prohlížečem v přirozené podobě.
Nijak jsem tehdy své tvrzení nepodložil. A to dnes napravím.
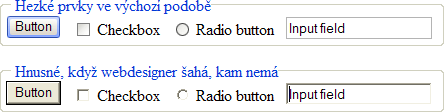
Je důležité si uvědomit, jak je ona výchozí podoba ve skutečnosti
křehká. Třeba takové tlačítko. Ve výchozí podobě ve Windows XP vypadá
pro každého uživatele maximálně srozumitelně, esteticky je na úrovni a
hezky reaguje na události myšky:
Nicméně stačí jen velmi drobný zásah do stylu a celé kouzlo se
rozpadne jako domeček z karet. Například nastavíme barvu pozadí
(v podstatě na výchozí
hodnotu).
input { background: ButtonFace }
A výsledkem je tento skok do grafického pravěku:
Co z toho plyne? Barvu pozadí nenastavovat. Ale pozor, pokud explicitně
neurčíme barvu pozadí, tak o ní nic nevíme – může být šedá, bílá
nebo třeba černá. Z toho důvodu nemůžeme nastavit ani barvu písma. Jen
ta výchozí bude správná.
Stejné dílo zkázy způsobí i hrátky s border, nebo celou
řadou dalších vlastností. Ale pozor. Netýká se to jen tlačítek, nýbrž
všech prvků formuláře!
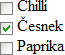
Margin a jeho přítel padding
Zdaleka nejde pouze o barvičky. Takto hezky vypadají obyčejné
nestylované zaškrtávací políčka ve Firefoxu pod Windows XP:
No uznejte, co jim chybí? Stačí však drobný zásah do jejich křehké
symbiózy, například zkur nastavení vlastnosti margin…
input { margin: 0 }
…a to dokonalé horizontální zarovnání ovládacích prvků s popisky
je minulostí:
A není cesty zpět. Ztracenou rovnováhu už žádným CSS nezachráníte.
Srovnáte účaří v jednom prohlížeči, rozbité bude v jiném. Můžete
nad tím spekulovat celé hodiny. Já vám radím – užijte ten čas nějak
lépe a prostě formuláře nestylujte.
Resetování CSS
S tímto velmi úzce souvisí takzvané hvězdičkové resetování
kaskádových stylů. Jde o kód, který se přidá na začátek
každého stylu…
* {
margin: 0;
padding: 0;
border: none;
}
…čímž se formuláře domrví nejen snadno a rychle, ale také
nenávratně. Chytří už vědí. Chytří neresetují
Související:
Vytvořit dokonalý vzorový CSS styl pro formulářové
prvky, to je výzva.
Co se od něj očekává? Tak především, že formuláře učiní co
nejhezčí. Zejména v majoritních prohlížečích a operačních systémem.
Ale zároveň plně použitelné i v těch minoritních. Nebo při zobrazení
bez CSS stylů.
Přehledné, přístupné, kontrastní, čitelné, ať už uživatel
používá jakýkoliv vizuální styl, jakékoliv systémové barvy.
Napsat takový mustr není žádná legrace. Ale myslím, že se mi to
nakonec, po dlouhých hodinách ladění, podařilo.
Stáhněte si jej
Vzor můžete používat zcela volně a dále jej upravovat. Nicméně
doporučuji zasahovat pouze do CSS vlastnosti font-size a
font-family. Jinou modifikací pravděpodobně znehodnotíte
křehkou funkčnost stylu.
Stáhněte si: CSS vzor pro
formulářové prvky
A vyzkoušejte si, jak jej váš prohlížeč zobrazí na jednoduchém
příkladu.
Související:






{kind=link}