Jak již víte, webové formuláře je potřeba stylovat opatrně, protože
už jejich nativní podoba bývá často tím nejlepším, čeho lze
dosáhnout.
Někdy má ale i výchozí podoba své mouchy. V komentářích
k předchozímu článku se jako problematické ukázalo
zarovnání checkboxů s popisky ve Firefoxu. Skutečně hrubá chyba se však
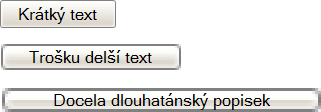
týká tlačítek v Internet Exploreru (včetně verze 7) pod Windows XP. Je-li
popisek na tlačítku dlouhý, vyčaruje prohlížeč takový zlý,
nepěkná věc:
S druhou chybou asi nic udělat nepůjde. To je prostě chyba ve
vykreslovacím jádře prohlížeče a lze ji leda reportovat vývojářům a
doufat, že třeba někdy…
Zajímavé je, že čím je tlačítko širší, tím ošklivěji se
vykreslí. Takže vyřešením první chyby, tj. donucením Exploreru, aby
tlačítka zúžil na odpovídající šířku, by se měl zmírnit či dokonce
odstranit i efekt zubatého vykreslení. Uvidíme.
Zužujeme tlačítko
Pokusy nastavit různé hodnoty pro width nebo
padding k ničemu nevedly. V takové chvíli se webdesigner
uchýlí ke střelbě naslepo v podobě experimentování s CSS vlastnostmi
jako display, overflow, position atd. Ukázalo se, že nápravu
sjedná overflow: visible. Pak ale tlačítko těsně obepíná
popisek, takže je záhodno ještě doplnit padding.
A vidíte? Zúžení tlačítek zcela eliminovalo vykreslovací vadu
u druhého z nich, v případě třetího ji alespoň zmírnilo.
Pocit vítězství nad digitálním nepřítelem jsem si vychutnával
přesně do chvíle, než jsem formulář s dlouhým tlačítkem naformátoval
do tabulky a ejhle:
Ačkoliv se tlačítka vykreslují se správnou šířkou, v tabulce
zabírají své původní místo. Problém vyřeší width:0.
Jenže lepší prohlížeče (Opera, Firefox) nulovou šířku skutečně
respektují, je tedy nutné použit IE-only hack. A to už je známá pohádka.
Buď dát za vděk vylepšenému „podtržítkovému hacku“, tedy
=width:0 (pro IE7 je nutné podtržítko zaměnit například za
rovnítko), nebo oddělit styl pro IE pomocí podmíněných komentářů.
Zabrousil jsem na Google a pokusil se najít jiná řešení. Stejný zápas
absolvoval jistý Jehiah Czebotar a po třech kolech s pomocí čtenářů
došel k velmi podobnému
výsledku, ale s jednou elegantní fintou navíc!
Zde je řešení:
/* chyba roztazenych tlacitek v IE pod WinXP */
input.button {
padding: 0 .25em;
width: 0; /* pouze pro IE */
overflow: visible;
}
input.button[class] { /* IE ignoruje [class] */
width: auto;
}
Finta spočívá v odlišení lepších prohlížečů od IE7
validní cestou. Díky tomu není potřeba „rovnítkový hack“ ani extra
soubor se stylem. Kód tedy můžete použít pro všechny
prohlížeče. Enjoy!
Před nějakou dobou jsem naznačoval, jak dokonale nastylovat webový formulář.
Pointou bylo, že formuláře je nejlépe nestylovat vůbec. Nechat je vykreslit
prohlížečem v přirozené podobě.
Nijak jsem tehdy své tvrzení nepodložil. A to dnes napravím.
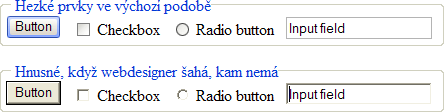
Je důležité si uvědomit, jak je ona výchozí podoba ve skutečnosti
křehká. Třeba takové tlačítko. Ve výchozí podobě ve Windows XP vypadá
pro každého uživatele maximálně srozumitelně, esteticky je na úrovni a
hezky reaguje na události myšky:
Nicméně stačí jen velmi drobný zásah do stylu a celé kouzlo se
rozpadne jako domeček z karet. Například nastavíme barvu pozadí
(v podstatě na výchozí
hodnotu).
input { background: ButtonFace }
A výsledkem je tento skok do grafického pravěku:
Co z toho plyne? Barvu pozadí nenastavovat. Ale pozor, pokud explicitně
neurčíme barvu pozadí, tak o ní nic nevíme – může být šedá, bílá
nebo třeba černá. Z toho důvodu nemůžeme nastavit ani barvu písma. Jen
ta výchozí bude správná.
Stejné dílo zkázy způsobí i hrátky s border, nebo celou
řadou dalších vlastností. Ale pozor. Netýká se to jen tlačítek, nýbrž
všech prvků formuláře!
Margin a jeho přítel padding
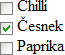
Zdaleka nejde pouze o barvičky. Takto hezky vypadají obyčejné
nestylované zaškrtávací políčka ve Firefoxu pod Windows XP:
No uznejte, co jim chybí? Stačí však drobný zásah do jejich křehké
symbiózy, například zkur nastavení vlastnosti margin…
input { margin: 0 }
…a to dokonalé horizontální zarovnání ovládacích prvků s popisky
je minulostí:
A není cesty zpět. Ztracenou rovnováhu už žádným CSS nezachráníte.
Srovnáte účaří v jednom prohlížeči, rozbité bude v jiném. Můžete
nad tím spekulovat celé hodiny. Já vám radím – užijte ten čas nějak
lépe a prostě formuláře nestylujte.
Resetování CSS
S tímto velmi úzce souvisí takzvané hvězdičkové resetování
kaskádových stylů. Jde o kód, který se přidá na začátek
každého stylu…
* {
margin: 0;
padding: 0;
border: none;
}
…čímž se formuláře domrví nejen snadno a rychle, ale také
nenávratně. Chytří už vědí. Chytří neresetují 🙂
Vytvořit dokonalý vzorový CSS styl pro formulářové
prvky, to je výzva.
Co se od něj očekává? Tak především, že formuláře učiní co
nejhezčí. Zejména v majoritních prohlížečích a operačních systémem.
Ale zároveň plně použitelné i v těch minoritních. Nebo při zobrazení
bez CSS stylů.
Přehledné, přístupné, kontrastní, čitelné, ať už uživatel
používá jakýkoliv vizuální styl, jakékoliv systémové barvy.
Napsat takový mustr není žádná legrace. Ale myslím, že se mi to
nakonec, po dlouhých hodinách ladění, podařilo.
Stáhněte si jej
Vzor můžete používat zcela volně a dále jej upravovat. Nicméně
doporučuji zasahovat pouze do CSS vlastnosti font-size a
font-family. Jinou modifikací pravděpodobně znehodnotíte
křehkou funkčnost stylu.
Odborníci na webdesign nejsou schopni elementární logické úvahy. A to
jaksi celosvětově.
Martin Snížek píše o optimalizaci pro rozlišení
1024×768. Že podle průzkumů přestává mít smysl brát ohled na
rozlišení 800×600. Takové průzkumy jsou dobré leda do výročních zpráv
výrobců monitorů. S webdesignem nesouvisí.
Webdesignéra absolutně nezajímá rozlišení monitoru. Hlavní
panel dole, proměnlivá velikost okna prohlížeče, tloušťka jeho rámečku,
záhlaví, menu, další pomocné lišty, posuvníky, případně záložky –
to všechno zabírá na monitoru místo. Ale ze statistiky rozlišení nevíme
jaké. Webdesignéra proto zajímají rozměry plochy, která zbývá pro
webovou stránku (tzv. viewport). Nic jiného.
Zdá se vám to samozřejmé? Mně taky. Proč se ale neustále vyvozují
závěry ze statistik rozlišení monitorů, namísto viewportů? Že by za tím
byla touha si potvrdit, že lze weby dělat širší? I když to není
pravda?
Měření vše prozradí
Při návrhu webů se držím rozměrů 770×420 pixelů. Jak jsem k těmto
číslům přišel? Je to čistě odhad. Rád bych vycházel z odborných
studií, jenže ony neexistují.
Kdysi viewport měřil
Yuhů. Jeho výsledky prozrazují, že cca 30% uživatelů
s rozlišením monitoru 1024×768 má viewport užší než 991px. Tedy nemá
maximalizované okno, nebo používá nějakou postranní lištu.
Ale pozor, čísla se mohou výrazně lišit dle zaměření webu. Odhaduji,
že u technických blogů bude viewport ještě menší, protože je lidé
často čtou přes RSS čtečky. Naopak u netechnických blogů bych čtečky
tolik nepředpokládal, nicméně situace se může změnit s masovým
nástupem Internet Explorer 7.
Jak viewport změřit? Google Analytics vám nepomůže, jeho tvůrci holt
nejsou schopni té zmíněné elementární logické úvahy. Umí to ve svém
placeném tarifu Navrcholu.cz, ale výsledky promítá do intervalů
s nepříjemně velkým rozpětím. Proto doporučuji vytvořit si vlastní
měřící bod, nebo upravit kód pro Analytics.
Pro někoho věci samozřejmé, pro mě především tahák.
Extrémně dlouhá čísla, tedy ty, co mají více než jednu cifru, si prostě
nepamatuji.
Přesměrování se v PHP realizuje tímto kódem:
$code = 301; // kód v rozsahu 300..307
$url = 'http://example.com';
header('Location: ' . $url, true, $code);
die('Pro pokračování prosím <a href="' . htmlSpecialChars($url) . '">klikněte sem</a>.');
Všimněte si, že po volání příkazu header() je nutné
skript explicitně ukončit. Není na škodu kvůli agentům, kteří
automaticky nepřesměrují, nabídnout textovou zprávu a odkaz.
Existuje několik URL, kam lze přesměrovat (stránky se liší například
jazykem). Uživateli nabídněte jejich seznam. Preferovaný cíl je možné
uvést v hlavičce Location; ne každý prohlížeč automaticky
přesměruje. Používá se zřídka.
301 Moved Permanently –
trvale přesunuto
Používejte v případech, kdy na požadovaném URL dříve existoval
zdroj, který se nyní (trvale) nachází na nové adrese. Tu uveďte
v hlavičce Location. Pokud však byl zrušen, oznamte to kódem
410 Gone.
302 Found – nalezeno
Problematický kód. Oznamuje, že zdroj byl dočasně přesunut jinam a
prohlížeč by měl na nové URL přistupovat stejnou metodou (GET, POST, HEAD,
…), jako na původní. Navíc u jiných metod než GET a HEAD by měl
přesměrování potvrdit uživatel. Většina prohlížečů toto však
nerespektuje, metodu změní na GET a potvrzení pak nevyžaduje.
Kód bývá chybně používán místo kódu 303.
303 See Other – pro PRG
Technika Post/Redirect/Get
zabraňuje dvojímu odeslání formuláře při reloadu stránky nebo kliknutí
na tlačítko zpět. Po odeslání formuláře metodou POST se provede
přesměrování metodou GET na další stránku. A k tomu slouží právě
kód 303. Tedy konvertuje POST na GET.
304 Not Modified – nezměněno
Pro potřeby kešování. Odpovídá na hlavičku If-Modified-Since,
že zdroj se od předchozí návštěvy nezměnil. Odpověď nesmí obsahovat
tělo, pouze hlavičky.
307 Temporary
Redirect – dočasné přesměrování
Jak jsem zmínil, kód 302 se stal problematickým kvůli nerespektování
normy ze strany webdesignérů i tvůrců prohlížečů. Kód 307 je jeho
reinkarnace, která už funguje většinou správně. Pomocí něj lze
například provést přesměrování metodou POST s přenesením
odeslaných dat.
Nakonec mít stránky validní je dobrá obrana proti bláznům, kteří
projíždějí validátorem všechny stránky a rozzuří se pokaždé, když
narazí na nějakou nevalidní konstrukci a mají tendenci to sdělit autorovi
webu 😉.
A já si říkám, jestli třeba už nenastala ta doba, kdy bych sem mohl
pustit sérii článků o tom, proč není XHTML žádná výhra, kde všude
udělali autoři XML chybu a podobně. Jestli bych nebyl ukamenován. Nebo
zaživa sněden. Bez chleba!
Tento článkem je vlastně odpovědí na e-mail Honzy Biena, který se ptal na čachry,
které jsem tuhle
prováděl s podmíněnými komentáři. Totiž, obecně panuje představa,
že jeden druh komentářů (downlevel-hidden) je validní a druhý
(downlevel-revealed) nikoliv. A já se právě pokusil ty nevalidní upravit
tak, aby validní byly. ;)
Máme tu tzv. „downlevel-hidden“ nebo chcete-li „skrývající“
komentář:
<!--[if IE 5]>
Tohle vidí jen IE verze 5
<![endif]-->
A také „downlevel-revealed“ aneb „odhalující“ komentář:
<![if !IE 5]>
Tohle vidí všichni kromě IE verze 5
<![endif]>
Nenechte se zmást tím, co se nachází mezi hranatýma závorkama, a
zobecněme, že pro otevření komentáře existují dva oficiální zápisy
<!--[if ???]> a <![if ???]>, a dále pro
uzavření opět dva <![endif]--> a
<![endif]>. To je důležitý výchozí bod.
Tedy ten podmíněný komentář s negací lze bezpochyby zapsat
i takto:
<!--[if !IE]>
Tohle vidí všichni kromě IE
<![endif]-->
Perfektní službu nám nyní prokazuje zvýrazňovač syntaxe FSHL, díky kterému jasně vidíme
zádrhel zmíněného zápisu. Totiž větu „Tohle vidí všichni kromě
IE“ sice ostatní prohlížeče vidí, ale bohužel jako součást
velkého komentáře. Což je nám vcelku houby platné, že?
Dobře, proč tedy ten načatý komentář nepřerušit?
<!--[if !IE]>
komentář --> tohle už ne <!-- opět komentář
<![endif]-->
Odsud už je jen krůček k optimalizaci:
<!--[if !IE]> -->
Tohle vidí všichni kromě IE
<!-- <![endif]-->
Jak prozrazuje FSHL, syntaxi jsme učinili za dost a výsledkem je plně
validní a funkční podmíněný komentář, kterým lze vložit kód, jenž IE
nevidí, ať se snaží sebevíc.
Ač je Flash nejrozšířenějším aktivním prvkem webových
stránek, mnoho webdesignérů neví, jak jej správně do stránky vložit.
Výchozí způsob, které propaguje Macromedia, je totiž naprosto
nepoužitelný.
Atributy elementu <object> jsou podřízeny potřebám
Internet Exploreru a v jiných prohlížečích Flash nezobrazí. Což
zachraňuje element <embed>, který však není součástí
HTML ani XHTML. Kód je tedy nevalidní, plný proprietárních obezliček.
V čem vidím největší problém, tak že nelze vytvořit alternativní
obsah, jenž bude zobrazen uživatelům, kteří Flash nemají (cca
10 %).
Díky úniku informací z Microsoftu se můžete už
nyní podívat na druhou beta-verzi Windows Internet Explorer 7.
A pohled je to vskutku zajímavý.
Vzhled
Vizuální podoba je oproti předchozí betě celistvější a
propracovanější. Klasické menu zmizelo úplně, je však možné ho
zapnout.
IE7 kromě obvyklé pětistupňové změny velikosti písma nyní nabízí i zoom celého dokumentu, jak to známe
z Opery. Nutno říci, že oproti ní je zmenšená stránka zcela nečitelná.
Zajímavou novinkou je zmenšený náhled všech otevřených záložek.
Pokroky v CSS
Věc, která vzbuzuje nejvíce očekávání a diskuzí. Zlepší se podpora
CSS v novém Exploreru? A jak se bude stavět ke starým postupům? Minulá
beta přinesla obrovské zklamání, vývojáři však slíbili nápravu
v betě druhé. Tak se jí podívejme na zoubek.
K testování jsem použil skvělý Derův web IE Brouci a zkusil zobrazit několik
testovacích stránek, kde Internet Explorer dříve chyboval. A světe div se,
Peek-a-boo, dvojitý okraj, 3px mezera a další jsou pryč!
Geniální udělátko o kterém se u nás kupodivu moc neví. Některým
webdesignérům prý natolik usnadnilo život, že začali fetovat a krást, aby
zase nějaké problémy měli. Takže opatrně s tím!
Už to budou dva roky, co Dean Edwards začal psát záplatu pro Internet Explorer,
která umožní webdesignerům používat pokročilé CSS vlastnosti. A nejen
je. Nazval ji vyloženě nešťastně IE7, nejspíš nevěřil ve vznik
další verze Microsoftího prohlížeče.