Let's once and for all crack this eternal question that
divides the programming community. I decided to dive into the dark waters of
regular expressions to bring an answer (spoiler: yes, it's possible).
So, what exactly does an HTML document contain? It's a mix of text,
entities, tags, comments, and the special doctype tag. Let's first explore each
ingredient separately.
Entities
The foundation of an HTML page is text, which consists of ordinary characters
and special sequences called HTML entities. These can be either named, like
for a non-breaking space, or numerical, either in
decimal   or hexadecimal   format.
A regular expression capturing an HTML entity would look like this:
(?<entity>
&
(
[a-z][a-z0-9]+ # named entity
|
\#\d+ # decimal number
|
\#x[0-9a-f]+ # hexadecimal number
)
;
)
All regular expressions are written in extended mode, ignore case, and a
dot represents any character. That is, the modifier six.
These iconic elements make HTML what it is. A tag starts with
<, followed by the tag name, possibly a set of attributes, and
closes with > or />. Attributes can optionally
have a value, which can be enclosed in double, single, or no quotes. A regular
expression capturing an attribute would look like this:
(?<attribute>
\s+ # at least one white space before the attribute
[^\s"'<>=`/]+ # attribute name
(
\s* = \s* # equals sign before the value
(
" # value enclosed in double quotes
(
[^"] # any character except double quote
|
(?&entity) # or HTML entity
)*
"
|
' # value enclosed in single quotes
(
[^'] # any character except single quote
|
(?&entity) # or HTML entity
)*
'
|
[^\s"'<>=`]+ # value without quotes
)
)? # value is optional
)
Notice that I am referring to the previously defined
entity group.
Elements
An element can represent either a standalone tag (so-called void element) or
paired tags. There is a fixed list of void element names by which they are
recognized. A regular expression for capturing them would look like this:
(?<void_element>
< # start of the tag
( # element name
img|hr|br|input|meta|area|embed|keygen|source|base|col
|link|param|basefont|frame|isindex|wbr|command|track
)
(?&attribute)* # optional attributes
\s*
/? # optional /
> # end of the tag
)
Other tags are thus paired and captured by this regular expression (I use a
reference to the content group, which we will define later):
(?<element>
< # starting tag
(?<element_name>
[a-z][^\s/>]* # element name
)
(?&attribute)* # optional attributes
\s*
> # end of the starting tag
(?&content)*
</ # ending tag
(?P=element_name) # repeat element name
\s*
> # end of the ending tag
)
A special case is elements like <script>, whose content
must be processed differently from other elements:
(?<special_element>
< # starting tag
(?<special_element_name>
script|style|textarea|title # element name
)
(?&attribute)* # optional attributes
\s*
> # end of the starting tag
(?> # atomic group
.*? # smallest possible number of any characters
</ # ending tag
(?P=special_element_name)
)
\s*
> # end of the ending tag
)
The lazy quantifier .*? ensures that the expression stops at the
first ending sequence, and the atomic group ensures that this stop is
definitive.
A typical HTML comment starts with the sequence <!-- and
ends with -->. A regular expression for HTML comments might
look like this:
(?<comment>
<!--
(?> # atomic group
.*? # smallest possible number of any characters
-->
)
)
The lazy quantifier .*? again ensures that the expression stops
at the first ending sequence, and the atomic group ensures that this stop is
definitive.
Doctype
This is a historical relic that exists today only to switch the browser to
so-called standard mode. It usually looks like
<!doctype html>, but can contain other characters as well.
Here is the regular expression that captures it:
(?<doctype>
<!doctype
\s
[^>]* # any character except '>'
>
)
Putting It All Together
With the regular expressions ready for each part of HTML, it's time to
create an expression for the entire HTML 5 document:
\s*
(?&doctype)? # optional doctype
(?<content>
(?&void_element) # void element
|
(?&special_element) # special element
|
(?&element) # paired element
|
(?&comment) # comment
|
(?&entity) # entity
|
[^<] # character
)*
We can combine all the parts into one complex regular expression. This is
it, a superhero among regular expressions with the ability to parse
HTML 5.
Final Notes
Even though we have shown that HTML 5 can be parsed using regular
expressions, the provided example is not useful for processing an HTML
document. It will fail on invalid documents. It will be slow. And so on. In
practice, regular expressions like the following are more commonly used (for
finding URLs of images):
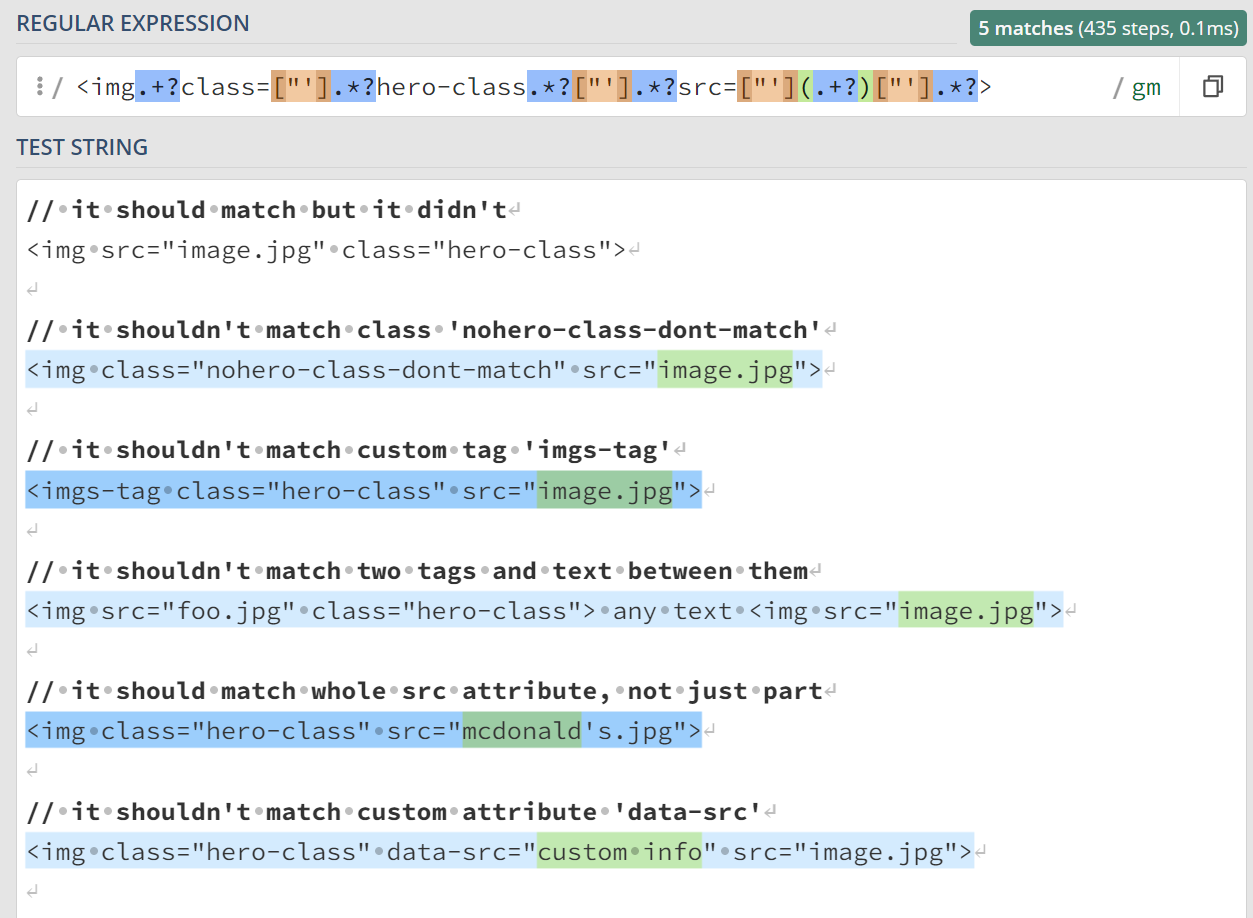
<img.+?src=["'](.+?)["'].*?>
But this is a very unreliable solution that can lead to errors. This regexp
incorrectly matches custom tags
such as <imgs-tag src="image.jpg">, custom attributes like
<img data-src="custom info">, or fails when the attribute
contains a quote <img src="mcdonald's.jpg">. Therefore, it is
recommended to use specialized libraries. In the world of PHP, we're unlucky
because the DOM extension supports only the ancient, decaying HTML
4. Fortunately, PHP 8.4 promises an HTML 5 parser.
Pojďme jednou provždy rozlousknout tuhle věčnou otázku,
která rozděluje komunitu programátorů. Rozhodl jsem se ponořit do temných
vod regulárních výrazů, abych přinesl odpověď (spoiler: ano, je to
možné).
Takže, co vlastně HTML dokument obsahuje? Jde o mix textu, entit, značek,
komentářů a speciální značky doctype. Prozkoumejme nejprve každou
ingredienci zvlášť.
Entity
Základem HTML stránky je text, který tvoří obyčejné znaky a
speciální sekvence zvané HTML entity. Ty mohou být buď pojmenované, jako
je pro nezlomitelnou mezeru, nebo číselné, a to buď
v desítkovém   nebo šestnáctkovém
  formátu. Regulární výraz, který zachytí HTML
entitu, by vypadal takto:
(?<entity>
&
(
[a-z][a-z0-9]+ # pojmenovaná entita
|
\#\d+ # desítkové číslo
|
\#x[0-9a-f]+ # hexadecimální číslo
)
;
)
Všechny regulární výrazy jsou zapsány v režimu extended, ignorují
velikost písmen a tečka představuje jakýkoliv znak. Tj. modifikátor
six.
Značky
Tyto ikonické prvky dělají HTML tím čím je. Tag začíná
<, následuje název tagu, možná sada atributů a uzavírá se
> nebo />. Atributy mohou mít volitelnou
hodnotu a ta může být uvozena do dvojitých, jednoduchých nebo žádných
uvozovek. Regulární výraz zachytávající atribut by vypadal takto:
(?<attribute>
\s+ # alespoň jeden bílý znak před atributem
[^\s"'<>=`/]+ # název atributu
(
\s* = \s* # rovnítko před hodnotou
(
" # hodnota uzavřená ve dvojitých uvozovkách
(
[^"] # libovolný znak kromě dvojité uvozovky
|
(?&entity) # nebo HTML entita
)*
"
|
' # hodnota uzavřená v jednoduchých uvozovkách
(
[^'] # libovolný znak kromě uvozovky
|
(?&entity) # nebo HTML entita
)*
'
|
[^\s"'<>=`]+ # hodnota bez uvozovek
)
)? # hodnota je volitelná
)
Všimněte si, že se odvolávám na pojmenovanou skupinu entity
definovanou dříve.
Elementy
Element může představovat jak samostatná značka (tzv. prázdný
element), tak značky párové. Existuje pevný výčet jmen prázdných
elementů, podle kterých je rozeznáme. Regulární výraz pro jejich
zachytávání by vypadal takto:
(?<void_element>
< # začátek značky
( # název elementu
img|hr|br|input|meta|area|embed|keygen|source|base|col
|link|param|basefont|frame|isindex|wbr|command|track
)
(?&attribute)* # volitelné atributy
\s*
/? # volitelné /
> # konec značky
)
Ostatní značky jsou tedy párové a zachytí je tento regulární výraz
(používám v něm odvolávku na skupinu content, kterou teprve
nadefinujeme):
(?<element>
< # počáteční značka
(?<element_name>
[a-z][^\s/>]* # název elementu
)
(?&attribute)* # volitelné atributy
\s*
> # konec počáteční značky
(?&content)*
</ # koncová značka
(?P=element_name) # zopakujeme název elementu
\s*
> # konec koncové značky
)
Speciálním případem jsou elementy jako <script>,
jejichž obsah se musí zpracovávat odlišně od ostatních elementů:
(?<special_element>
< # počáteční značka
(?<special_element_name>
script|style|textarea|title # název elementu
)
(?&attribute)* # volitelné atributy
\s*
> # konec počáteční značky
(?> # atomická skupina
.*? # nejmenší možný počet jakýchkoliv znaků
</ # koncová značka
(?P=special_element_name)
)
\s*
> # konec koncové značky
)
Líný kvantifikátor .*? zajistí, že se výraz zastaví
u první ukončovací sekvence, a atomická skupina zajistí, že toto
zastavení bude definitivní.
Komentáře
Typický HTML komentář začíná sekvencí <!-- a končí
sekvencí -->. Regulární výraz pro HTML komentáře může
vypadat takto:
(?<comment>
<!--
(?> # atomická skupina
.*? # nejmenší možný počet jakýchkoliv znaků
-->
)
)
Líný kvantifikátor .*? opět zajistí, že se výraz zastaví
u první ukončovací sekvence, a atomická skupina zajistí, že toto
zastavení bude definitivní.
Doctype
Jde o historický relikt, který dnes existuje jen proto, aby přepnul
prohlížeč do tzv. standardního režimu. Obvykle vypadá jako
<!doctype html>, ale může obsahovat i další znaky. Zde
je regulární výraz, který jej zachytí:
(?<doctype>
<!doctype
\s
[^>]* # jakékoliv znaky kromě '>'
>
)
Dejme to dohromady
Když máme hotové regulární výrazy zachytávající každou část HTML,
je čas vytvořit výraz pro celý HTML 5 dokument:
\s*
(?&doctype)? # volitelný doctype
(?<content>
(?&void_element) # prázdný element
|
(?&special_element) # speciální element
|
(?&element) # párový element
|
(?&comment) # komentář
|
(?&entity) # entita
|
[^<] # znak
)*
Všechny části můžeme spojit do jednoho komplexního regulárního
výrazu. Tohle je
on, superhrdina mezi regulárními výrazy se schopností parsovat
HTML 5.
Závěrečné poznámky
I když jsme si ukázali, že HTML 5 lze parsovat pomocí regulárních
výrazů, uvedený příklad k ničemu užitečný není. Nepomůže
vám se zpracováním HTML dokumentu. Vyláme si zuby u nevalidního dokumentu.
Bude pomalý. A tak dále. V praxi se používají spíš reguláry jako je
tento (pro hledání URL obrázků):
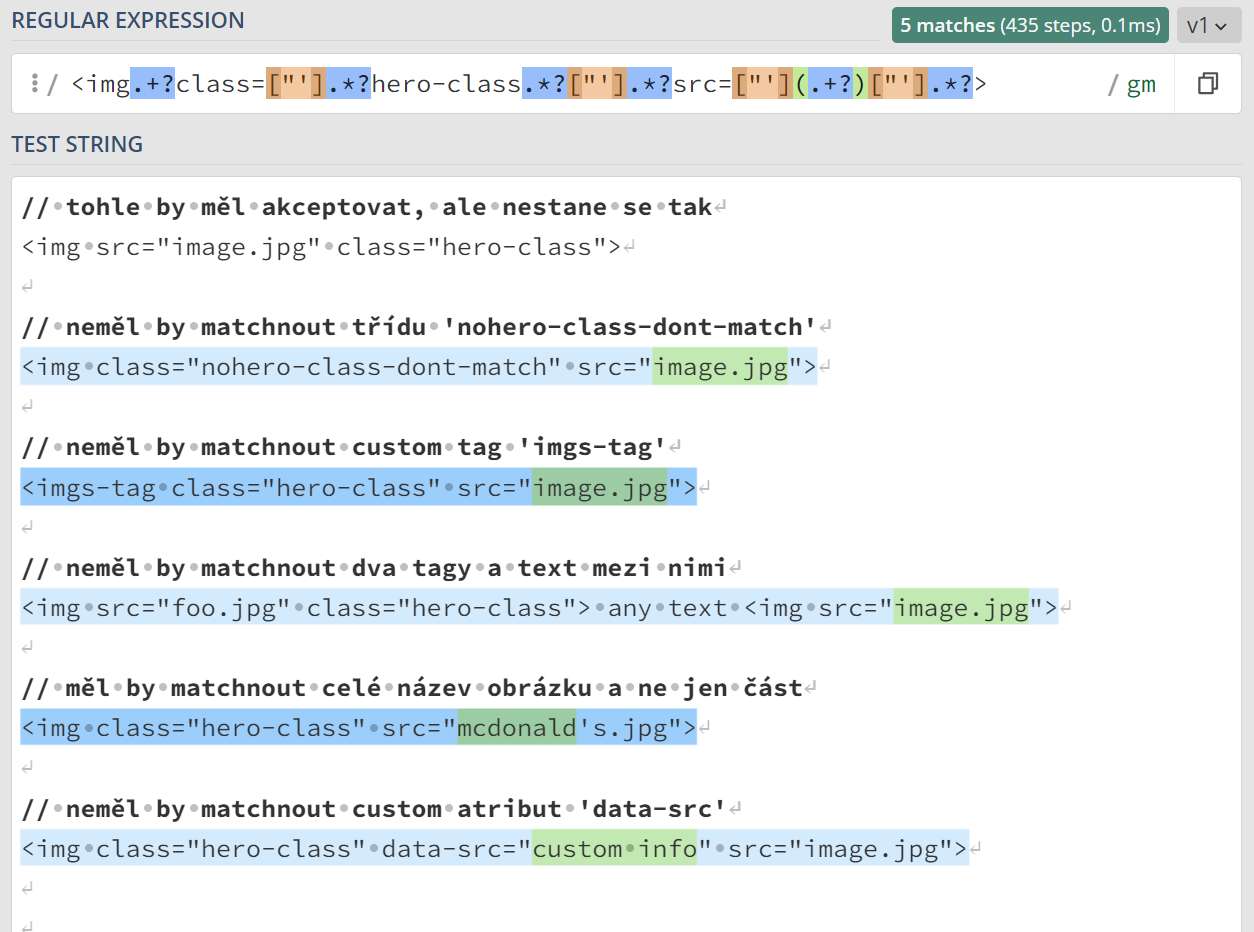
<img.+?src=["'](.+?)["'].*?>
Ale to je opravdu velmi nespolehlivé řešení, která vede k chybám.
Tento regexp chybně matchuje
třeba custom tagy jako například
<imgs-tag src="image.jpg">, custom atributy jako
<img data-src="custom info">, nebo selže, když atribut bude
obsahovat uvozovku <img src="mcdonald's.jpg">. Proto je
doporučeno používat specializované knihovny. Ve světě PHP máme
smolíčka, protože rozšíření DOM podporuje pouze pravěké ztrouchnivělé
HTML 4. Naštěstí PHP 8.4 slibuje parser pro HTML
5.
A video from Microsoft, intended to be a dazzling
demonstration of Copilot's capabilities, is instead a tragically comedic
presentation of the decline in programming craftsmanship.
I'm referring to this video.
It's supposed to showcase the abilities of GitHub Copilot, including how to use
it to write a regular expression for searching <img> tags
with the hero-image class. However, the original code being
modified is as holey as Swiss cheese, something I would be embarrassed to use.
Copilot gets carried away and instead of correcting, continues in the
same vein.
The result is a regular expression that unintentionally matches other
classes, tags, attributes, and so on. Worse still, it fails if the
src attribute is listed before class.
I write about this because this demonstration of shoddy work, especially
considering the official nature of the video, is startling. How is it possible
that none of the presenters or their colleagues noticed this? Or did they notice
and decide it didn't matter? That would be even more disheartening. Teaching
programming requires precision and thoroughness, without which incorrect
practices can easily be propagated. The video was meant to celebrate the art of
programming, but I see in it a bleak example of how the level of programming
craftsmanship is falling into the abyss of carelessness.
Just to give a bit of a positive spin: the video does a good job of showing
how Copilot and GPT work, so you should definitely give it a look 🙂
Video od Microsoftu, které mělo být oslnivou ukázkou
možností Copilota, je spíš tragikomickou prezentací úpadku
programátorského řemesla.
Mluvím o tomto videu.
Má demonstrovat možnosti GitHub Copilota, mimo jiné jak pomocí něj napsat
regulární výraz pro vyhledávání značek <img>
s třídou hero-image. Jenže už původní kód, který
upravují, je děravý jako švýcarský sýr, já bych se za něj styděl.
Copilot se nechá strhnout a místo opravy pokračuje ve stejném duchu.
Výsledkem je regulární výraz, který nezamýšleně matchuje i jiné
třídy, jiné značky, jiné atributy a tak dále. Ba co víc, selže, pokud je
atribut src uveden před class.
Píšu o tom, protože tato demonstrace fušeřiny, zejména vzhledem
k oficiální povaze videa, je zarážející. Jak je možné, že si toho
nevšiml ani jeden z prezentujících či jejich kolegů? Nebo si toho všimli
a řekli si, že o nic nejde? To by bylo ještě smutnější. Výuka
programování vyžaduje preciznost a důslednost, bez nichž se snadno mohou
propagovat nesprávné praktiky. Video mělo být oslavou programátorského
umění, ale já v něm vidím ponurou ukázku, jak se úroveň
programátorského řemesla propadá do propasti nedbalosti.
Ale ať nejsem jenom negativní: je tam hezky ukázáno, jak funguje Copilot
a v něm GPT, takže si je určitě pusťte 🙂
Chcete se ponořit do světa objektově orientovaného
programování v PHP, ale nevíte, kde začít? Mám pro vás nového
stručného průvodce OOP, který vás seznámí se všemi těmi pojmy, jako
class, extends, private atd.
V průvodci se dozvíte, co je to:
- třída a objekt
- jmenné prostory
- dědičnost versus kompozice
- viditelnost
- klíčové slovo final
- statické vlastnosti, metody a konstanty
- rozhraní nebo abstraktní třída
- typová kontrola
- Fluent Interfaces
- traity
- a jak fungují výjimky
Průvodce si neklade za cíl udělat z vás mistry v psaní čistého kódu
nebo podat zcela vyčerpávající informace. Jeho cílem je vás rychle
seznámit se základními koncepty OOP v současném PHP a dát vám fakticky
správné informace. Tedy poskytnout pevný základ, na kterém můžete dále
stavět. Třeba aplikace v Nette.
Jako navazující čtení doporučuji podrobný průvodce
světem správného návrhu kódu. Ten je přínosný i pro všechny, co
PHP a objektově orientované programování ovládají.
Programování v jazyce PHP byla vždycky trošku výzva, ale naštěstí
prošlo mnohými změnami k lepšímu. Pamatujete na časy před verzí PHP 7,
kdy skoro každá chyba znamenala fatal error, což aplikaci okamžitě
ukončilo? V praxi to znamenalo, že jakákoli chyba mohla aplikaci zcela
zastavit, aniž by programátor měl možnost ji zachytit a náležitě na ni
reagovat. Nástroje jako Tracy využívaly magických triků, aby dokázaly
takové chyby vizualizovat a logovat.
Naštěstí s příchodem PHP 7 se tohle změnilo. Chyby nyní vyvolávají
výjimky, jako jsou Error, TypeError a ParseError, které lze snadno zachytávat
a řešit. Avšak i v moderním PHP existuje slabé místo, kdy se chová
stejně jako ve své páté verzi. Mluvím o chybách během kompilace. Ty
nelze zachytit a okamžitě vedou k ukončení aplikace. Jedná se o chyby
úrovně E_COMPILE_ERROR. PHP jich generuje na dvě stovky. Vzniká paradoxní
situace, že když PHP načte soubor se syntaktickou chybou, jako je třeba
chybějící středník, vyhodí zachytitelnou ParseError. Avšak když je
soubor syntakticky v pořádku, ale obsahuje chybu odhalitelnou až při
kompilaci (jako dvě metody se stejným jménem), vyústí to ve
fatální chybu.
try {
require 'cesta_k_souboru.php';
} catch (ParseError $e) {
echo "Syntaktická chyba v PHP souboru";
}
Bohužel, kompilační chyby v PHP nemůžeme ověřit interně. Existovala
funkce php_check_syntax(), která navzdory názvu odhalovala
i kompilační chyby. Byla zavedena v PHP 5.0.0, ale záhy odstraněna ve
verzi 5.0.4 a od té doby nikdy nebyla nahrazena. Pro ověření správnosti
kódu se musíme spolehnout na linter z příkazové řádky:
php -l soubor.php
Z prostředí PHP lze ověřit kód uložený v proměnné
$code třeba takto:
$code = '... PHP kód pro ověření ...';
$process = proc_open(
PHP_BINARY . ' -l',
[['pipe', 'r'], ['pipe', 'w'], ['pipe', 'w']],
$pipes,
null,
null,
['bypass_shell' => true],
);
fwrite($pipes[0], $code);
fclose($pipes[0]);
$error = stream_get_contents($pipes[1]);
if (proc_close($process) !== 0) {
echo 'Chyba v PHP souboru: ' . $error;
}
Nicméně režie spouštění externího PHP procesu kvůli ověření
jednoho souboru je docela velká. Ale dobrá zpráva přichází s verzí PHP
8.3, která přinese možnost ověřovat více souborů najednou:
php -l soubor1.php soubor2.php soubor3.php
PHP users have been waiting for the ?? operator for an
incredibly long time, perhaps ten years. Today, I regret that it took
longer.
- Wait, what? Ten years? You're exaggerating, aren't you?
- Really. Discussion started in 2004 under the name “ifsetor”. And it
didn't make it into PHP until December 2015 in version 7.0. So almost
12 years.
- Aha! Oh, man.
It's a pity we didn't wait longer. Because it doesn't fit into the
current PHP.
PHP has made an incredible shift towards strictness since 7.0. Key
moments:
The ?? operator simplified the annoying:
isset($somethingI[$haveToWriteTwice]) ? $somethingI[$haveToWriteTwice] : 'default value'
to just:
$write[$once] ?? 'default value'
But it did this at a time when the need to use isset() has
greatly diminished. Today, we more often assume that the data we access exists.
And if they don't exist, we damn well want to know about it.
But the ?? operator has the side effect of being able to detect
null. Which is also the most common reason to use it:
$len = $this->length ?? 'default value'
Unfortunately, it also hides errors. It hides typos:
// always returns 'default value', do you know why?
$len = $this->lenght ?? 'default value'
In short, we got ?? at the exact moment when, on the contrary,
we would most need to shorten this:
$somethingI[$haveToWriteTwice] === null
? 'default value'
: $somethingI[$haveToWriteTwice]
It would be wonderful if PHP 9.0 had the courage to modify the behavior of
the ?? operator to be a bit more strict. Make the “isset
operator” really a “null coalesce operator”, as it is officially called by
the way.
PHPStan and checkDynamicProperties:
true helps you to detect typos suppressed by the ??
operator.
Na operátor ?? se v PHP čekalo neskutečně dlouho, snad
deset let. Dnes je mi ale líto, že se nečekalo déle.
- Počkej, cože? Deset let? Tak to přeháníš, ne?
- Opravdu. Začal se řešit v roce 2004, pod názvem „ifsetor“.
A dostal se do PHP až v prosinci 2015 ve verzi 7.0. Takže téměř
12 let.
- Aha! Notyvole.
Škoda, že se nečekalo déle. Do současného PHP totiž nezapadá.
PHP počínaje verzí 7.0 udělalo neuvěřitelný posun ke striktnosti.
Klíčové okamžiky:
Operátor ?? zjednodušil otravné:
isset($necoCo[$musimNapsatDvakrat]) ? $necoCo[$musimNapsatDvakrat] : 'default value'
na pouhé:
$pisu[$jednou] ?? 'default value'
Jenže udělal to v době, kdy potřeba používat isset()
značně klesla. Dnes častěji počítáme s tím, že data, ke kterým
přistupujeme, existují. A pokud neexistují, tak se o tom sakra chceme
dozvědět.
Operátor ?? má ale vedlejší efekt a to schopnost detekovat
null. Což je taky nejčastější důvod k jeho užití:
$len = $this->length ?? 'default value'
Bohužel zároveň zatajuje chyby. Zatajuje překlepy:
// vždy vrátí 'default value', víte proč?
$len = $this->lenght ?? 'default value'
Zkrátka ?? jsme dostali přesně ve chvíli, kdy bychom naopak
nejvíc potřeboval zkrátit tohle:
$necoCo[$musimNapsatDvakrat] === null
? 'default value'
: $necoCo[$musimNapsatDvakrat]
Bylo by úžasné, kdyby PHP 9.0 mělo odvahu chování operátoru
?? upravit k trošku větší striktnosti. Udělat z „isset
operátoru“ opravdu „null coalesce operator“, jak se mimochodem oficiálně jmenuje.
S detekcí překlepů zamlčených operátorem ?? vám
pomůže PHPStan s nastavením checkDynamicProperties:
true.
Určitě už jste někdy narazili debatu „tabulátory vs. mezery“ pro
odsazování. Polemika probíhá od nepaměti a oba tábory vyzdvihují své
argumenty:
Tabulátory:
- odsazování je jejich účel
- menší soubory, protože odsazení zabírá jeden znak
- můžete si nastavit vlastní šířku odsazení (? k tomu se
vrátíme)
Mezery:
- kód bude vypadat všude stejně a konzistence je klíčová
- vyhnete se možným problémům v prostředích citlivých na
bílé znaky
Co když jde ale o víc než o osobní preference? ChaseMoskal nedávno
zveřejnil na Redditu velmi podnětný příspěvek s názvem Nikdo
nezmínil skutečný důvod, proč používat tabulátory místo mezer,
který vám otevře oči.
Stěžejní důvod, proč
používat tabulátory
Chase ve svém příspěvku popisuje zkušenost se zaváděním mezer na
svém pracovišti a negativní dopady, které to mělo na spolupracovníky se
zrakovým postižením.
Jeden z nich byl zvyklý používat šířku tabulátoru 1, aby se vyhnul
velkým odsazením při použití obřího písma. Druhý používá šířku
tabulátoru 8, protože mu nejlépe vyhovuje na ultraširokém monitoru. Pro oba
však představuje kód s mezerami vážný problém, musí je převádět na
tabulátory před čtením a zase zpátky na mezery před komitováním.
Pro nevidomé programátory, kteří používají braillské displeje,
představuje každá mezera jednu braillskou buňkou. Pokud je tedy výchozí
odsazení 4 mezery, odsazení 3. úrovně plýtvá 12 cennými braillskými
buňkami ještě před začátkem kódu. Na 40buňkovém displeji, který se
u notebooků používá nejčastěji, je to více než čtvrtina dostupných
buněk, které jsou promrhány bez jakékoliv informace.
Nám se může přizpůsobení šířky odsazení zdát jako zbytečnost,
jsou ale mezi námi programátoři, pro které je naprosto nezbytné. A to
prostě nemůžeme ignorovat.
Tím, že budeme v našich projektech používat tabulátory, dáváme jim
možnost tohoto přizpůsobení.
Nejdříve
přístupnost, pak osobní preference
Jistě, nejde přesvědčit každého, aby se přiklonil na jednu či druhou
stranu, jde-li o preference. Každý má své. A měli bychom být rádi za
možnost volby.
Zároveň však musíme dbát na to, abychom zohledňovali všechny. Abychom
respektovali odlišnosti a používali přístupné prostředky. Jakým je
například znak tabulátor.
Myslím, že Chase to vystihl dokonale, když ve svém příspěvku uvedl,
že „…neexistuje žádný protiargument, který by se jen blížil k tomu
převážit potřeby přístupnosti našich spolupracovníků“.
Accessible first
Stejně jako při navrhování webů se vžila metodika „mobile first“,
kdy se snažíme zajistit, aby každý, bez ohledu na zařízení, měl
s vaším produktem skvělou user experience – měli bychom usilovat o
„accessible first“ prostředí tím, že zajistíme, aby každý měl
stejnou možnost pracovat s kódem, ať už v zaměstnání nebo na opensource
projektu.
Pokud se tabulátory stanou výchozí volbou pro odsazování, odstraníme
jednu bariéru. Spolupráce pak bude příjemná pro každého, bez ohledu na
jeho schopnosti. Pokud budou mít všichni stejné možnosti, můžeme
maximálně využít společný potenciál ❤️
Článek vychází z Default
to tabs instead of spaces for an ‚accessible first‘ environment.
Podobně přesvědčivý post jsem si přečetl v roce 2008 a ještě ten den
změnil ve všech svých projektech mezery na tabulátory. Zůstala po tom stopa
v Gitu, ale samotný článek už zmizel v propadlišti dějin.
Knihovna Texy od verze 3.1.6 přidává podporu pro Latte
3 v podobě značky {texy}. Co umí a jak ji nasadit?
Značka {texy} představuje snadný způsob, jak v Latte
šablonách psát přímo v syntaxi Texy:
{texy}
You Already Know the Syntax
----------
No kidding, you know Latte syntax already. **It is the same as PHP syntax.**
{/texy}
Stačí do Latte nainstalovat rozšíření a předat mu objekt Texy
nakonfigurovaný podle potřeby:
$texy = new Texy\Texy;
$latte = new Latte\Engine;
$latte->addExtension(new Texy\Bridges\Latte\TexyExtension($texy));
Pokud je mezi značkami {texy}...{/texy} statický text, tak se
přeloží pomocí Texy už během kompilace šablony a výsledek do ní
uloží. Pokud je obsah dynamický (tj. jsou uvnitř Latte značky),
zpracování pomocí Texy se provádí pokaždé při vykreslování
šablony.
Pokud je žádoucí Latte značky uvnitř vypnout, dá se to
udělat takto:
{texy syntax: off} ... {/texy}
Do rozšíření lze kromě objektu Texy předat také vlastní funkci a tak
umožnit předávat ze šablony parametry. Kupříkladu chceme mít možnost
předávat parametry locale a heading:
$processor = function (string $text, int $heading = 1, string $locale = 'cs'): string {
$texy = new Texy\Texy;
$texy->headingModule->top = $heading;
$texy->typographyModule->locale = $locale;
return $texy->process($text);
};
$latte = new Latte\Engine;
$latte->addExtension(new Texy\Bridges\Latte\TexyExtension($processor));
Parametry v šabloně předáme takto:
{texy locale: en, heading: 3}
...
{/texy}
Pokud chcete pomocí Texy formátovat text uložený v proměnné, můžete
použít filtr:
{$description|texy}