Jako blesk z čistého nebe přišla od Google tisková zpráva
přivádějící v život atribut rel="nofollow". Měl by se stát
postrachem spammerů, zatím však zneklidňuje
spíše SEO odborníky. Nakonec, v SEO sféře panuje poslední dobou docela
nuda, takže konečně je o čem diskutovat.
Když teda jinak nedáte, podělím se s Vámi, drazí čtenáři,
i o svůj názor. A bude vesměs Pragmatický (ačkoliv žiji v Brně).
Nepropadejte panice
Především – nevidím v tom naprosto žádnou tragédii. Proč?
Protože hlavním zájmem Google je přece provozovat kvalitní vyhledávač,
který vrací co nejrelevantnější výsledky.
Zavedením rel="nofollow" dává jasně najevo, že situace už
není taková, jako před pár lety, a že úroveň vyhledávání nevylepší
pouze vývojem algoritmů, ale potřebuje spolupráci i od webmasterů.
Tak nabídl rel="nofollow", jako skvělý a snadný způsob, jak
odlišit významné odkazy od těch nepodstatných, bez nutnosti znásilňovat
elementy <h1> a jemu podobné. Sice vedle šesti úrovní
titulků je tato metoda poněkud binární (nikoliv bizarní), nicméně jsem
rád, že existuje. A ať se o něm píše i v učebnicích HTML a
slabikářích!
Odkazuj a bude Ti odkazováno
Nikde však není řečeno, jak bude Google na atribut
rel="nofollow" pohlížet. Je tu všeobecná představa, že
takové odkazy bude prostě ignorovat. Ta se nejspíš zakládá na tiskové
zprávě, jenže tiskové zprávy nestvořil Bůh proto, abychom jim
věřili, ale proto, aby měli jeho nezdárná dítka co psát a říkat si
u toho manageři. Hehe, z toho jejich povídání aby člověk nakonec měl
pocit, že Google to celé dělá z lásky k blogerům a chce je chránit
před spammery 🙂
Mám za to, že přítomnost Rylnou-falouckého atributu bude jen dalším
faktorem, další proměnnou ve výpočetních algoritmech Google.
A s dolaďováním tohoto vzorce se bude měnit i jeho význam a
důležitost. Je tedy úplně možné, že nevhodně nebo přehnaně použitý
rel="nofollow" bude znamenat bodíky mínus i pro zdrojovou
stránku. A až tohle nějakého anglicky mluvícího SEO guru napadne, bude
zase o čem psát…
Pokud jste několik posledních dní strávili jakoukoliv
příjemnější činností než sezením u komplu a informace o
rel="nofollow" Vám unikla, můžete si víc přečíst na tomto
Yuhůově rozcestníku.
Jiří Kosek napsal svůj první článek na
Interval.cz a hned jím rozpoutal bouřlivou diskuzi. Je v ní víc vášně
než argumentů. Kdyby autorem článku nebyl pisatel tak zvučného jména, zřejmě by byl
v komentářích rychle odbyt.
Z toho celého u mě převládají dva dojmy:
pozitivní: je tu velká spousta webdesignérů, kteří mají zájem
tvořit kvalitní weby moderním způsobem
negativní: spousta diskutujících brání své vyznání a haní
opačné se zřejmým fanatismem, místo argumentů nastupují emoce
Z hlediska zápisu je mezi HTML 4.01 a XHTML 1.0 tak drobný rozdíl, že
jít kvůli tomu do zbraně je absurdní. Ale děje se to. Což potvrzuje
fanatický přístup k problematice. Zkusím poukázat na několik
paradoxů:
Paradox č. 1
Skalní zastánci oddělování obsahu (HTML) od formy (CSS) nejsou
schopni oddělit diskuzi o HTML od diskuze o CSS.
Přitom XHTML a HTML mají naprosto tytéž prostředky, jak CSS
implementovat. Taktéž značka FONT je v označena
jako Deprecated už v HTML 4.
Paradox č. 2
„Internet Explorer není schopen zobrazit XHTML stránky,“ tvrdí
diskutující v komentáři, který napsal v MSIE a odeslal z XHTML validní
stránky Intervalu.
XHTML verze 1.0 je navrženo tak, aby jej bylo možné zobrazit i ve
straších prohlížečích, jako je například IE. Otázkám zpětné
kompatibility je věnován dodatek C specifikace.
Paradox č. 3
O tom, že stránka je v XHTML větší a zabírá více místa, je
možné vést stovky kilobajtů zbytečných diskuzí.
Úvahy nad úsporou datového objemu bývají obvykle užitečné. Třeba
v oborech, které se zabývají komprimací videa a hudby. Uvažovat nad
bajtíky je mrháním časem.
Paradox č. 4
„HTML dovoluje ‚prasárny‘, které Vám u XHTML neprojdou“ soukal
ze sebe, zatímco se cpal pizzou, drobky mu padaly na klávesnici a pak mastnou
rukou klikl na tlačítko odeslat.
Jste-li prasátka a máte-li rádi bordýlek, ať už v kódu, na disku nebo
ve svém pokoji, nepomůže Vám ani XHTML. Chyba není na straně W3C, ale ve
špatné výchově, kterou Vám rodiče poskytli 😉
Paradox č. 5
XHTML píší odborníci, HTML laici.
Asi nejdůležitější moment: Pokud pod pojmem XHTML chápete správně
sestavenou a platnou XHTML stránku, tak je nutné i pod pojmem HTML chápat
jen správně sestavený dokument. Ačkoliv si spousta designérů
myslí, že také tvoří HTML, často to není pravda. Prostě píší textový
soubor s využitím HTML značek, který umí jejich prohlížeč nějakým
způsobem zobrazit.
Takže obojí, jak HTML tak i XHTML, vyžaduje od autora výbornou znalost
problematiky.
A tímto bych článek uzavřel. Sám používám výhradně XHTML
z důvodu kompatibility s XML. Ta otevírá dveře do dalších dimenzí
zpracování dokumentů. Na druhou stranu vím, že převod HTML XHTML je
proveditelný plně automaticky.
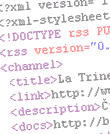
Co mi to milá RSS čtečko, co mi to děláš? Všechny browsery si
s HTML entitami perfektně rozumí, jen ty ty entity mršíš.
To Vám prostě takhle ráno napíše Jiří Bureš, že jeho čtečka
nekousne La Trinní RSS. Tak jsem si prohlédl generovaný dokument a na první
pohled se zdál být ok. Našel jsem si na webu Feed Validátor a ejhle! Diagnóza
zní: nedefinované entity. Ale jen v některých verzích RSS.
Tak nezbývalo, než se seznámit s problematikou RSS více do hloubky,
abych dospěl k zjištění, že existuje hromada různých verzí, které
mají společnou snad jen tu vlastnost, že jsou vzájemně nekompatibilní.
Paráda. A protože odlišné verze staví na odlišných DTD, mají také
(ne)definované jiné entity. Tedy např. ­ v jedné verzi
funguje, v druhé nikoliv.
Řešením by bylo přidat do DOCTYPE další DTD. Myšlenka je to
elegantní, bohužel téměř žádná čtečka to nekousne. Takže rychle ze
slepé uličky ven.
Jak na to
Problém lze vyřešit jednoduchou fintou: místo zápisu
použít ekvivalentní  . Ale to
už jsme jen krůček od úplného odstranění entit – místo
  lze prostě přímo vložit znak s kódem 160. Pokud
je RSS kódované v UTF-8, je taková transformace bezztrátová (vnější
tvář dokument zůstane nezměněna). Samozřejmě entity
& < > znakem nahradit nelze, je třeba
zůstat u mezikroku, tedy & < >.
Mám pocit, že tvůrce RSS kanálů a čteček nenapadlo, že existují
i jiné znaky, než jen ty z anglické abecedy. Ach jo.
Pokud máte za to, že Post a Get jsou bratranci Čuka a Geka, musím Vás
hned předem varovat: „tento článek je určen tvůrcům webových
stránek“. Takže čtěte jen tehdy, je-li webdesign Vaším čálkem
šaje 😉
Při tvorbě HTML formuláře máme k dispozici dvě metody, jak odeslat
data zpět serveru: POST a GET. Data odeslaná metodou GET se stanou součástí
URL, doplní se za otazník a jsou tedy vidět v adresním řádku
prohlížeče. Naopak metoda POST data odesílá odděleně od URL.
Předpokládám, že tohle asi všichni znáte.
Zkusme jít trošku do hloubky. Metodu GET není třeba spojovat jen
s formuláři. Jakékoliv stažení objektu ze serveru je provedením příkazu
GET. Vyvolá jej každé kliknutí na odkaz <a href=...>,
transparentně jej provede <img src=...>.
POST je ryze formulářová záležitost. Jak jsem uváděl, data se
odesílají mimo URL – to se ovšem týká jen položek formuláře.
Zároveň je totiž možné odesílat ještě další data v URL, které je
uvedeno v action formuláře. Zjednodušeně řečeno, POST umí
totéž co GET a ještě o dost víc.
Kdy použít GET a kdy POST?
Protože často tvořím internetové aplikace, kde se to formuláři jen
hemží, snažil jsem se odvodit nějaké univerzální pravidlo, kdy použít
kterou metodu:
Použijte POST, pokud
odeslání formuláře způsobí vnitřní změnu serveru (zápis do
databáze, odeslání e-mailu, …) čtěte poznámku 1
odesílaná data nejsou zcela veřejná
velikost dat může překročit 1000 bajtů (čtěte
poznámku 2)
V ostatních případech lze použít GET.
Toto pravidlo mějte na zřeteli i tehdy, když tvoříte „GET bez
formuláře“, tedy prostý odkaz <a href=...?paramtery>.
Pokud pravidlo říká, že je třeba použít POST, nahraďte přímý odkaz
formulářem POST s tlačítkem. Nebo alespoň změňte odkaz tak, aby vedl na
potvrzovací formulář. A teprve po jeho odkliknutí proveďte akci. Je to
především opatření proti robotům, kteří by mohli při procházení webu
nadělat škodu.
Poznámka 1: Při zpracování položek formuláře je třeba
ověřit, zda byly skutečně odeslány jako POST. V PHP pomůže důsledné
používání superglobálního pole $_POST.
Pokud je nežádoucí, aby refresh stránky nebo návrat v historii
prohlížeče způsobil znovuodeslání formuláře, přesměrujte se po
zpracování na další stránku hlavičkou Location:
header('Location: http://www.example.com/');
Poznámka 2: Pokud formulářem odesíláte soubory, nezapomeňte mu
nastavit enctype="multipart/form-data".
Jde o zabezpečení
Zde uvedené principy a pravidla mají za úkol jediné: pomoci zabezpečit
Váš web či aplikaci. Ať už před koumákem, který se ji pokouší nabourat
záměrně, nebo před robotem, který tak činní v tupé nevinnosti.
Roboti zkoumající Váš web zkusí otevřít každou adresu, stáhnout
každou stránku. Je to jejich úkol a dost možná, že je to i baví. Jediná
věc, před kterou se zastaví, jsou formuláře. A právě proto jsem varoval
před odkazy, které suplují formuláře. Je třeba je používat
s rozvahou.
p.s.: Jste-li autorem webové aplikace, zkuste se zamyslet: jak by to
dopadlo, kdyby se do administrační části náhodou dostal robot?
Jako slepec na střelnici, který se marně snaží trefit růži. Tak si
připadám při ladění JavaScriptu, který generuje HTML výstup. Pokud se
napoprvé netrefím, hledání chyb bývá zdlouhavé a nervy drásající.
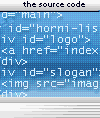
Nesmírně užitečnou pomocí je proto vypsání kódu, který prohlížeč
skutečně zobrazuje (rendered source). Tohle dokáže Internet Explorer díky
své proprietární vlastnosti outerHTML. Stačí tedy nějakým
způsobem zobrazit následující:
document.documentElement.outerHTML
Na Choseho
blogu je popsáno jednoduché řešení využívající značky XMP.
Bohužel se tím přepíše původní obsah okna, podívejme se tedy po
elegantnějším řešení. Aby umělo tyto vychytávky:
aktivace přes kontextové menu
zobrazení zdrojového kódu do nového okna
při označení části stránky se zobrazí jen její kód