Journey into the heart of the three most known CSS
preprocessors continues, though not in the way I originally planned.
CSS preprocessor is a tool that take code written in their own syntax and
generates the CSS for the browser. The most popular preprocessors are SASS, LESS and
Stylus. We have talked about
installation
and syntax
+ mixins. All three preprocessors have a fundamentally different way of
mixins conception.
Each of them have gallery of finished mixins: For SASS there is a
comprehensive Compass, the LESS has
framework Twitter
Bootstrap or small Elements a Stylus
NIB.
… this was opening sentences of article I started write year and
quarter ago and never finished. I came to the conclusion that all three
preprocessors are useless. They required to do so many compromises that
potential benefits seemed insignificant. Today I will explain it.
A question that many webmasters ask: do search engines perceive these URLs
as the same? How should they be treated?
http://example.com/article
http://example.com/article/
http://example.com/Article
https://example.com/article
http://www.example.com/article
http://example.com/article?a=1&b=2
http://example.com/article?b=2&a=1
The short answer would be: “URLs are different.” However, a more detailed
analysis is needed.
From a user's perspective, these addresses differ only in minor details
which they generally disregard. Thus, they perceive them as the same, although
technically, they are different addresses. Let's call them similar
addresses. For the sake of “user experience”, two principles should be
adhered to:
Do not allow different content on similar addresses. As I will show
soon, this would not only confuse users but also search engines.
Allow users access through similar addresses.
If the addresses differ in protocol http / https or
with www domain or without, search engines consider them different.
Not so for users. It would be a fatal mistake to place different content on such
similar addresses. However, it would also be a mistake to prevent access through
a similar address. The address with www and without
www must both function, with SEO recommending sticking to one
variant and redirecting the others to it using a 301 HTTP code. This can be
managed for the www subdomain with a
.htaccess file:
# redirection to the non-www variant
RewriteCond %{HTTP_HOST} ^www\.
RewriteRule ^.*$ http://example.com/$0 [R=301,NE,L]
# redirection to the www variant
RewriteCond %{HTTP_HOST} !^www\.
RewriteRule ^.*$ http://www.example.com/$0 [R=301,NE,L]
Immediately test whether your servers redirect, including the full address
and correct parameter passing.
Don't forget variants like www.subdomain.example.cz. Because some
browsers can bypass missing redirections, try a low-level service like Web-Sniffer.
URLs are case-sensitive except for the scheme and domain. However, users do
not differentiate and therefore, it is unfortunate to offer different content on
addresses differing only by letter case. A poor example can be seen in
Wikipedia:
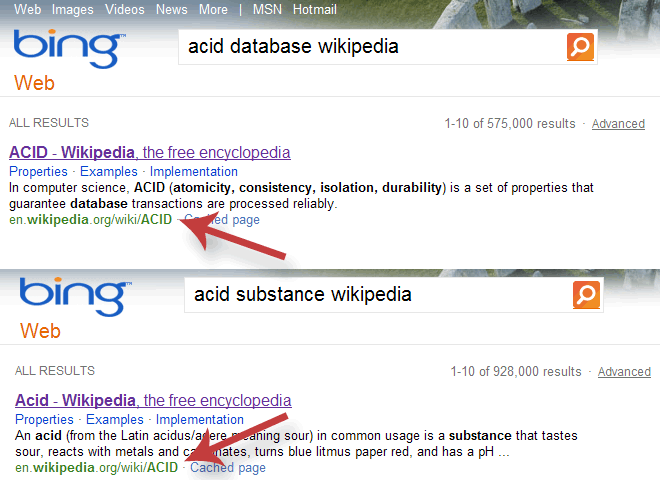
Bing amusingly suffers from an error, returning the same URL whether you
search for acid or a database (although the textual description is correct).
Google and Yahoo do not have this issue.
Bing does not differentiate between acid and database
Some services (webmails, ICQ) convert uppercase letters in URLs to lowercase,
which are all reasons to avoid distinguishing letter size, even in parameters.
Better adhere to the convention that all letters in URLs should be
lowercase.
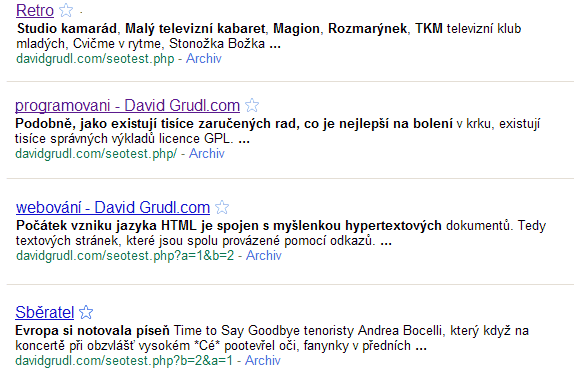
Distinguishing some similar addresses is also a challenge for search
engines. I conducted an experiment by placing different content on URLs
differing in details like the presence of a trailing slash or parameter order.
Only Google was able to index them as different. Other search engines could
always handle only one of the variants.
Only Google can index these pages as different
As for trailing slashes, the web server usually redirects to the canonical
form for you; if you access a directory without a trailing slash, it adds one
and redirects. Of course, this does not apply when you manage URIs on your own
(Cool URIs, etc.)
Finally: does the order of parameters really matter? There should be no
difference between article?a=1&b=2 and
article?b=2&a=1. However, there are situations where this is
not the case, especially when passing complex structures such as arrays. For
instance, ?sort[]=name&sort[]=city might be different from
?sort[]=city&sort[]=name. Nevertheless, redirecting if
parameters are not in the specified order would be considered unnecessary
overcorrection.
p.s. Nette Framework automatically
handles redirection to canonical URLs on its own.
I recently participated in a discussion that reminded me
(again) of the deeply entrenched myths regarding the differences between HTML
and XHTML. The campaign for the formats with the letter “X” was accompanied
by great emotions, which usually do not go hand in hand with a clear head.
Although the enthusiasm has long since faded, a significant part of the
professional community and authors still believe a number of misconceptions.
In this article, I will attempt to bury the biggest of these myths in the
following way. This article will contain only facts. I will save my
opinions and your comments for a second article.
In the text below, by HTML I mean the version HTML 4.01, and by XHTML I mean the
version XHTML 1.0 Second Edition.
For completeness, I add that HTML is an application of the SGML
language, while XHTML is an application of the XML language.
Myth: HTML allows tag crossing
Not at all. Tag crossing is directly prohibited in SGML, and consequently in
HTML. This fact is mentioned, for example, in the W3C recommendation:
“…overlapping is illegal in SGML…”. All these markup languages
perceive the document as a tree structure, and therefore it is not possible to
cross tags.
I am also responding to a reformulation of the myth: “The advantage of
XHTML is the prohibition of crossing tags.” This is not the case; tags cannot
be crossed in any existing version of HTML or XHTML.
Myth:
XHTML banned presentation elements and introduced CSS
Not at all. XHTML contains the same sort of elements as HTML 4.01. This is
mentioned right in the first
paragraph of the XHTML specification: “The meaning of elements and
their attributes is defined in the W3C recommendation for HTML 4.” From
this perspective, there is no difference between XHTML and HTML.
Some elements and attributes were deprecated already in HTML
4.01. Presentation elements are forbidden in favor of CSS, which also
answers the second part of the myth: the arrival of cascading styles with XHTML
is unrelated, having occurred earlier.
Myth: HTML parser must
guess tag endings
Not at all. In HTML, for a defined group of
elements, the ending or starting tag can optionally be omitted. This is for
elements where omitting the tag cannot cause ambiguity. As an example,
take the ending tag for the p element. Since the standard states
that a paragraph cannot be inside another paragraph, it is clear by
writing…
<p>....
<p>....
…that by opening the second paragraph, the first must close. Therefore,
stating the ending tag is redundant. However, for example, the div
element can be nested within itself, so both the starting and ending tags are
required.
Myth: HTML attribute
notation is ambiguous
Not at all. XHTML always requires enclosing attribute values in quotes or
apostrophes. HTML also requires
this, except if the value consists of an alphanumeric string. For
completeness, I add that even in these cases, the specification recommends
using quotes.
Thus, in HTML it is permissible to write
<textarea cols=20 rows=30>, which is formally as unambiguous
as <textarea cols="20" rows="30">. If the value contained
multiple words, HTML insists on using quotes.
Myth: HTML document is
ambiguous
Not at all. The reasons given for ambiguity are either the possibility of
crossing tags, ambiguity in writing attributes without quotes, which are already
debunked myths, or also the possibility of omitting some tags. Here I repeat
that the group of elements where tags can be omitted is chosen so as to omit
only redundant information.
Thus, an HTML document is always unambiguously determined.
Myth: Only in XHTML
is the ‘&’ character written as ‘&’
Not at all – it must also be written that way in HTML. For both languages,
the characters < and & have a specific meaning.
The first opens a tag and the second an entity. To prevent them from being
understood in their meta-meaning, they must be written as an entity. Thus also
in HTML, as stated by the specification.
Myth: HTML
allows ‘messes’ that would not pass in XHTML
Not at all. This view is rooted in a series of myths that I have already
refuted above. I haven't yet mentioned that XHTML, unlike HTML, is case
sensitive for element and attribute names. However, this is a completely
legitimate feature of the language. In this way, Visual Basic differs from C#,
and it cannot objectively be said that one or the other approach is worse. HTML
code can be made confusing by inappropriately mixing upper and lower case
(<tAbLe>), XML code can also be confusing by using strings
like id, ID, Id for different
attributes.
The clarity of the notation in no way relates to the choice of one language
over the other.
Myth: Parsing XHTML is much
easier
Not at all. Comparing them would be subjective and therefore has no place in
this article, but objectively, there is no reason why one parser should have a
significantly easier time. Each has its own set of challenges.
Parsing HTML is conditioned by the fact that the parser must know the
document type definition. The first reason is the existence of optional tags.
Although their addition is unambiguous (see above) and algorithmically easy to
handle, the parser must know the respective definition. The second reason
concerns empty elements. That an element is empty is known to the parser only
from the definition.
Parsing XHTML is complicated by the fact that the document can (unlike HTML)
contain an internal subset DTD with the definition of its own entities (see example). I add that
an “entity” does not have to represent a single character, but any lengthy
segment of XHTML code (possibly containing further entities). Without processing
the DTD and verifying its correctness, we cannot talk about parsing XHTML.
Furthermore, syntactically, DTD is essentially the opposite of XML language.
In summary: both HTML and XHTML parsers must know the document type
definition. The XHTML parser additionally must be able to read it in DTD
language.
Myth: Parsing XHTML is much
faster
In terms of the syntactic similarity of both languages, the speed of parsing
is only determined by the skill of the programmers of the individual parsers.
The time required for machine processing of a typical web page (whether HTML or
XHTML) on a regular computer is imperceptible to human perception.
Myth: HTML parser must always
cope
Not at all. The HTML specification does
not dictate how an application should behave in case of processing an
erroneous document. Due to competitive pressures in the real world, browsers
have become completely tolerant of faulty HTML documents.
It is different in the case of XHTML. The specification, by referring to XML
dictates
that the parser must not continue processing the logical structure of the
document in case of an error. Again, due to competitive pressures in the real
world, RSS readers have become tolerant of faulty XML documents (RSS is an
application of XML, just like XHTML).
If we were to deduce something negative about HTML from the tolerance of web
browsers, then we must necessarily deduce something negative about XML from
the tolerance of RSS readers. Objectively, the draconian approach
of XML to errors in documents is utopian.
Conclusion?
If your mind is no longer burdened by any of the myths mentioned above, you
can better perceive the difference between HTML and XHTML. Or rather, you can
better perceive that there is no difference. The real difference occurs a level
higher: it is the departure from SGML and the transition to the new XML.
Unfortunately, it cannot be said that XML only solves the problems of SGML
and adds no new ones. I have encountered two in this article alone. One of them
is the draconian processing of errors in XML, which is not in line with
practice, and the other is the existence of a different DTD language inside XML,
which complicates parsing and the understandability of XML documents. Moreover,
the expressive capability of this language is so small that it cannot formally
cover even XHTML itself, so some features must be defined separately. For a
language not bound by historical shackles, this is a sad and striking finding.
However, criticism of XML is a topic for a separate article.
(If I encounter more myths, I will gradually update the article. If you
want to refer to them, you can take advantage of the fact that each headline has
its own ID)
As you might know, web forms have to by styled with care, since
their native look often is the best you can achieve.
That said, sometimes even default look has its bugs. A truly flagrant
mistake concerns buttons in Internet Explorer (including version 7) in Windows
XP. If the button's caption is too long, the browser produces such a
nasty thing:
This articles is actually an answer to e-mail by Honza Bien, who was asking
me about the manipulations
I was doing with conditional coments. Say, generally accepted idea is, that
one kind of a comments (downlevel-hidden) is valid and the other
(downlevel-revealed) is not. I tried to adapt those invalid comments the way
that they would be valid. I'll explain the whole sequence.
Although flash is the most spread active element of webpages, a
lot of designers still don't know the correct way to insert it into HTML
document.. The standard concept, advertised by Macromedia is absolutely
unusable.