Stylish
je doplněk do Chrome, který umožňuje přidat webovým stránkám vlastní
CSS styly.
(Lze ho nainstalovat i do nové Opery, nejprve si přidejte Download
Chrome extension a pak už ho přímo nainstalujete z Chrome webstore.)
Stylish jsem si přidal kvůli GitHubu, který mě štve příliš širokými
tabulátory a hlavně nezalamováním řádků s textem, bez čehož se podobné commity
vůbec nedají číst.
Zalamování jsem vyřešil stylem:
div.blob-wrapper td.blob-code {
white-space: pre-wrap !important;
}
A tabulátory:
html * {
tab-size: 4 !important;
}
Pak jsem si ještě vzpomněl, jak mi vadí nevhodně umístěné tlačítko
„Close pull request“ hned vedle „Comment“ a posunul jsem ho
trošku bokem:
button.js-comment-and-button {
float: left !important;
color: #C22;
}
A hned je svět krásnější 
Jsou tomu 3 roky, kdy vyšlo Nette 2.0.0. Šlo o přelomovou
verzi. Uzavřela pár let trvající vývoj a přinesla novinky, bez kterých si
dnes vůbec nelze vývoj v Nette představit.
- Dependency Injection
- formát NEON
- Debug Bar rozšiřitelný o vlastní panely
- unobtrusive JavaScript validation ve formulářích
- nové API pro rozšiřování Latte
- novou strukturu jmenných prostorů a tříd
- představila databázovou vrstvu Nette Database
a NDBT
- a také úplně nově sepsanou dokumentaci
Shodou okolností v té době byly vydány i přelomové dvojkové verze
významných frameworků Zend a Symfony. Nedá mi to nepřipomenout, že na
rozdíl od nich Nette nehodilo uživatele svých předchozích verzí přes
palubu, tj. neudělalo mezi verzemi tlustou čáru, ale naopak se snažilo
o zachování kompatibility, jak to jen bylo možné. Uživatelé také
například dostali nástroj, který jim ve zdrojových kódech nahradil
původní názvy tříd za nové atd.
PHP 5.2
Řada 2.0 stále držela podporu PHP 5.2, včetně verze PHP 5.2.0, což
bylo skutečně bolestivé. Šlo totiž o jednu z méně povedených verzí
PHP, jenže Debian ji měl předinstalovanou a konzervativní správci ji
odmítali aktualizovat.
Zajímavostí je, že Nette bylo již od
roku 2010 psáno čistě v PHP 5.3 se všemi jeho vymoženostmi, jako
jsou jmenné prostory nebo anonymní funkce. (Dvě) verze pro PHP 5.2 byly
vytvářeny strojově převodníkem. Ten nejen zaměňoval názvy tříd na
varianty bez jmenných prostorů, ale poradil si i s přepisem anonymních
funkcí a řadou dalších odlišností, jako například nemožností použít
func_get_args() jako parametr funkce atd.
Příklad kódu v PHP 5.3:
/**
* Caches results of function/method calls.
* @param mixed
* @param array dependencies
* @return Closure
*/
public function wrap($function, array $dependencies = null)
{
$cache = $this;
return function() use ($cache, $function, $dependencies) {
$key = array($function, func_get_args());
$data = $cache->load($key);
if ($data === null) {
$data = $cache->save($key, Nette\Callback::create($function)->invokeArgs($key[1]), $dependencies);
}
return $data;
};
}
A převedeného kódu pro PHP 5.2:
/**
* Caches results of function/method calls.
* @param mixed
* @param array dependencies
* @return NClosure
*/
public function wrap($function, array $dependencies = null)
{
$cache = $this;
return create_function('',
'extract($GLOBALS[0]['.array_push($GLOBALS[0], array('cache'=>$cache,'function'=> $function,'dependencies'=> $dependencies)).'-1], EXTR_REFS);
$_args=func_get_args(); $key = array($function, $_args);
$data = $cache->load($key);
if ($data === null) {
$data = $cache->save($key, NCallback::create($function)->invokeArgs($key[1]), $dependencies);
}
return $data;
');
}
Dependency Injection
Co zpětně vidím jako nejdůležitější přínos Nette 2.0? Dependency
Injection. Ale slovy klasika:
To není jednoduchá věc to Dependency Injection. Není. To je věc, ve
které se ne každý dost dobře vyzná.
DI nahradilo do té doby používaný objektový Service Locator a jeho
statickou variantu, třídu Environment. Čímž naprosto převrátilo způsoby,
jak aplikace navrhovat. Přineslo kvalitativní posun na novou úroveň. Proto
také přepsat aplikaci používající Environment na Dependency Injection je
nesmírně náročné, protože to vlastně znamená ji navrhnout znovu
a lépe.
End of Life
První den roku 2014 vyšlo Nette 2.0.14. Ano, tak hezky to vyšlo Tím byl ukončen
vývoj řady 2.0 a série vstoupila do roční fáze critical issues
only, kdy byly opravovány jen závažné chyby. Dnes tato fáze končí.
Před pár dny vyšlo Nette 2.0.18,
definitivně poslední verze této řady a také poslední verze pro
PHP 5.2.
Tak sbohem a šáteček!
(Do fáze critical issues only nyní vstupuje řada 2.1. Po
dobu roku 2015 budou opravovány jen závažné chyby.)
Tři roky slýchávám otázku: „Budeš mít školení Nette
i pro pokročilé?“ – „Budu,“ odpovídal jsem, ale zdaleka netušil,
že přípravy zaberou tolik času. Konečně je to tady!
Pokročilé školení Mistrovství
v Nette volně navazuje na základní kurz Vývoj
aplikací v Nette a je určeno všem, kteří už framework používají a
chtějí proniknout do podstaty jeho fungování. Vědět vše o Dependency
Injection a co jim přinese psaní tzv. rozšíření. Jak tvořit vlastní
makra do Latte. Jak správně navrhovat komponenty. Nebo vytvářet vlastní
formulářové prvky. A tak dále.
Příprava trvala tak dlouho hlavně kvůli mé permanentní nespokojenosti
s frameworkem  Nechci školit oblasti, dokud mi nepřipadají perfektní. Ano, je to asi
hloupost, ale jelikož vždycky na školeních otevřeně říkám i to, co se
mi na Nette nelíbí, tak ten dobrý vnitřní pocit je tuze důležitý.
Nechci školit oblasti, dokud mi nepřipadají perfektní. Ano, je to asi
hloupost, ale jelikož vždycky na školeních otevřeně říkám i to, co se
mi na Nette nelíbí, tak ten dobrý vnitřní pocit je tuze důležitý.
S verzí Nette 2.2 jsem konečně začal být spokojený.
V říjnu jsem vypsal beta-verzi kurzu, na kterou se přihlásilo 3×
více lidí, než jaká byla kapacita. Mezi nimi možná i ti vaši konkurenti
Udělal jsem
proto testovací školení tři, odladil pořadí i náročnost témat a všem
účastníkům děkuji za feedback.
Teď už jedeme naostro.
Přihlaste se na školení Mistrovství
v Nette a staňte se Nette guru!
Composer, nejdůležitější nástroj
pro PHP vývojáře, umožňuje 3 způsoby, jak instalovat balíčky:
- lokální
composer require vendor/name
- globální
composer global require vendor/name
- jako projekt
composer create-project vendor/name
Lokálně
Lokální instalace se používá nejčastěji. Mám projekt, ve kterém chci
třeba použít Tracy, tak v kořenovém
adresáři projektu zadám:
composer require tracy/tracy
a Composer zaktualizuje (nebo vytvoří) soubor composer.json a
stáhne Tracy do podsložky vendor. Zároveň vygeneruje
autoloader, takže v kódu jej stačí inkludovat a můžu rovnou Tracy
použít:
require __DIR__ . '/vendor/autoload.php';
Tracy\Debugger::enable();
Jako projekt
Diametrálně odlišná situace nastává tehdy, pokud místo knihovny,
jejíž třídy ve svém projektu používám, instaluji nástroj, který
jen spouštím z příkazové řádky.
Příkladem může být třeba ApiGen pro
generování přehledných API dokumentací. V takovém případě se použije
třetí způsob:
composer create-project apigen/apigen
Composer vytvoří novou složku (a tedy i nový projekt)
apigen a do ní stáhne celý nástroj a nainstaluje jeho
závislosti.
Bude mít vlastní composer.json a vlastní podsložku
vendor.
Tímto způsobem se instaluje i třeba Nette Sandbox nebo CodeChecker. Nikoliv však
testovací nástroje jako je Nette Tester
nebo PHPUnit, protože jejich třídy naopak
v testech používáme, voláme Tester\Assert::same() nebo
dědíme od PHPUnit_Framework_TestCase.
Bohužel Composer umožňuje instalovat nástroje jako je ApiGen i pomocí
composer require a nevypíše ani žádné varování.
Což je totéž, jako když donutíte dva vývojáře, kteří se ani
neznají a kteří pracují na úplně jiném projektu, aby sdíleli společnou
složku vendor. Na to se dá říci:
- Proboha proč by to měli dělat?
- Vždyť to přece nemůže fungovat!
Ano, není žádný rozumný důvod to dělat, nic to nepřinese, naopak to
přestane fungovat v momentě, kdy dojde ke kolizi používaných knihoven. Je
to jen otázka času, stavění domečku z karet, který se dřív nebo
později sesype. Jeden projekt bude vyžadovat knihovnu XY ve verzi 1.0, druhý
ve verzi 2.0 a v tu chvíli to přestane fungovat.
Globálně
Rozdíl mezi variantou 1) a 2), tj. mezi composer require a
composer global require, je pak v tom, že nepůjde o dva cizí
vývojáře, ale o deset cizích vývojářů a deset nesouvisejících
projektů. Tedy je to nesmysl na druhou.
Totiž composer global je špatné řešení úplně vždy,
neexistuje use case, kdy by bylo vhodné jej použít. Výhodou je jen to, že
když si globální adresář vendor/bin přidáte do PATH,
můžete snadno spouštět takto nainstalované knihovny.
Rekapitulace
composer require vendor/name pokud chcete používat třídy
knihovnycomposer global require vendor/name nikdy!composer create-project vendor/name pro nástroje volané jen
z příkazové řádky
Poznámka: npm používá odlišnou
filosofii danou možnostmi JavaScriptu a každou knihovnu instaluje jako
„samostatný projekt“, s vlastním adresářem vendor (resp.
node_modules). Ke konfliktu verzí tak dojít nemůže.
V případě npm naopak platí, že globální instalace
nástrojů, jako je například LESS CSS, jsou
velmi užitečná a příjemná věc.
Naučit se psát všemi deseti, zvládnou správné
prstoklady – to je nepochybně prima přednost. Ale mezi námi, sám datluji
celý život dvěma prsty a při psaní přikládám daleko větší důraz
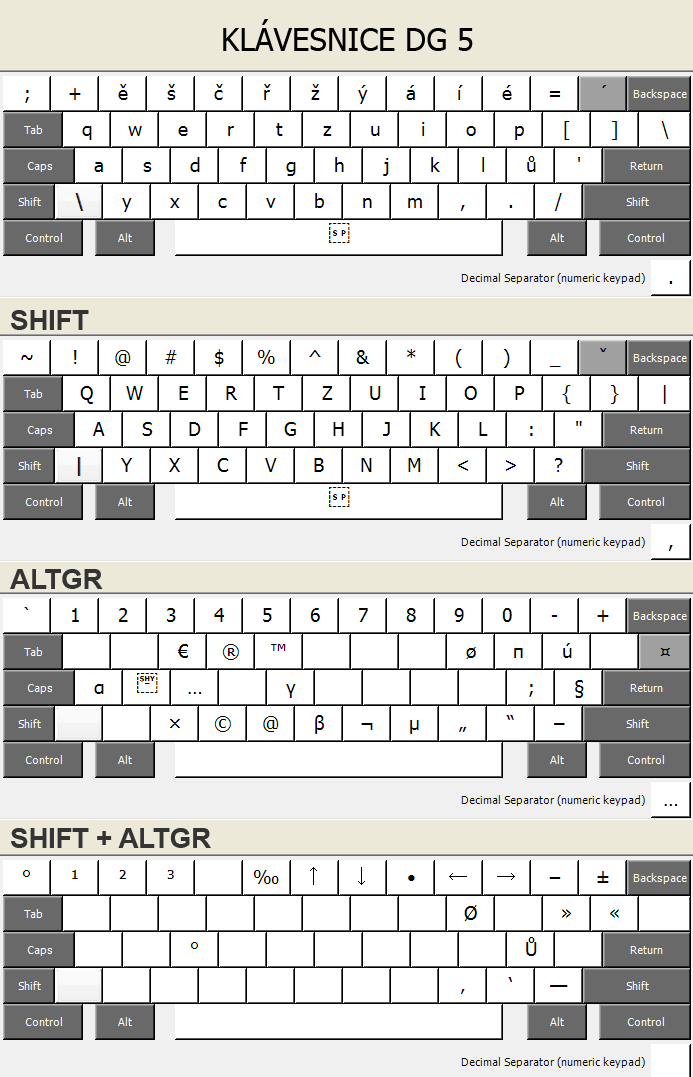
něčemu jinému. A tím je rozložení klávesnice.
Webmasteři, programátoři nebo copywriteři narážejí na problém, že
spousta často používaných znaků na české klávesnici buď úplně chybí,
nebo je hůř přístupná. Nejhůř jsou na tom typografické znaky, jako
české uvozovky „ “, výpustka …, křížek ×, copyright © atd. Obvykle
se to řeší přepínáním mezi dvěma klávesnicemi, českou a anglickou, a
osvojením si milionu zkratek Alt-číslo, které chybějící znaky
suplují. Ať už tak či onak, jedná se o značné brzdy tvořivosti. Nešlo
by to udělat lépe?
Vlastní rozložení klávesnice
Řešením je si vytvořit vlastní rozložení klávesnice. To své jsem si
vypiplal asi před
deseti lety a je vhodné pro programátory, webdesignery, copywritery,
obsahuje všechny důležité typografické vychytávky, jako je pomlčka, dvojité a
jednoduché uvozovky atd., intuitivně umístěné. Rozložení si můžete
samozřejmě upravit, viz dále.
Všechny typografické znaky jsou dosažitelné přes pravý Alt, nebo-li
AltGr. Rozložení je intuitivní:
- české dvojité uvozovky „“ AltGr-<
AltGr->
- české jednoduché uvozovky ‚‘ AltGr-Shift-<
AltGr-Shift->
- nedělitelná mezera AltGr-mezerník
- křížek × AltGr-X
- trojtečka … AltGr-D (dot)
- pomlčka – AltGr-spojovník
- dlouhá pomlčka — AltGr-Shift-spojovník
- copyright © AltGr-C
- trademark ™ AltGr-T
- € AltGr-E
- ø AltGr-O
A tak dále, na celé rozložení se můžete podívat na obrázcích.
Ke stažení: klávesnice dg v5 (pro
Windows)
Jak se tvoří vlastní
rozložení klávesnice?
Je to snadné a je to zábavné. Přímo od Microsoftu si stáhněte
kouzelný a dobře utajený program Microsoft Keyboard
Layout Creator (ke svému chodu vyžaduje .NET Framework).
Hned při spuštění se Vám zobrazí „prázdná“ klávesnice, tedy
taková, kde ještě není definováno žádné rozložení kláves. Začínat
na zelené louce není to pravé ořechové, proto si najděte v menu příkaz
Load existing keyboard a načtěte některé standardní
rozložení (například klasickou českou klávesnici).
U každé klávesy můžete definovat znak, který se napíše při
samostatném stisku a dále při použití přepínačů (tedy Shift,
Ctrl+Alt (pravý Alt), pravý Alt +Shift,
Caps Lock a Shift+Caps Lock). Dále lze klávesu označit
jako mrtvou (dead key), což znamená, že znak se napíše až po stisknutí
další klávesy. Takto funguje například háček a čárka v české
klávesnici.
Skutečná bomba je export hotové klávesnice. Výsledkem je plnohodnotný
ovladač klávesnice včetně instalačního programu. Takže svou klávesnici
si můžete pověsit na internet a nainstalovat na jiné počítače.
Několik tipů, jak vylepšit vzhled vašeho webu v mobilním
telefonu.
Okraje
Zkontrolujte si, jak na mobilu vypadají okraje kolem textu. Velmi
pravděpodobně je bude potřeba přizpůsobit. Buď budou moc široké a
zbytečně tak ubírají drahocenný prostor, nebo nebudou žádné, což je
při čtení značně iritující.
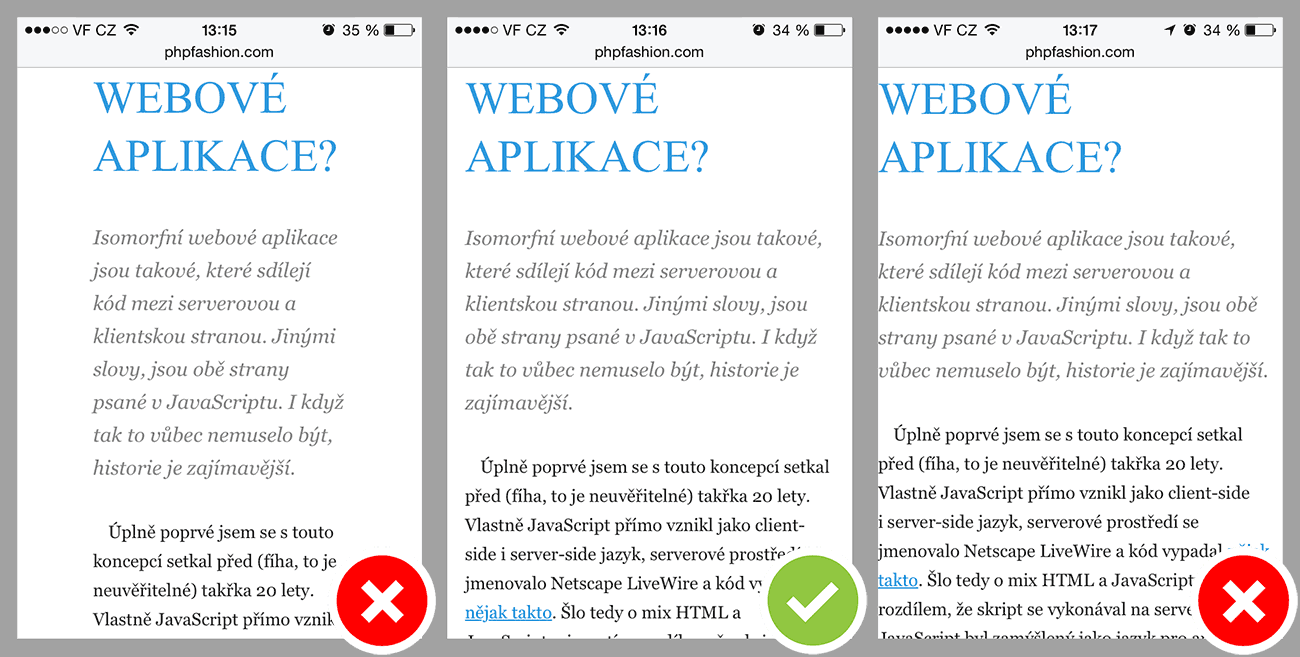
Vlastní písma
Obsah je daleko důležitější, než úžasný webový font, kterým je
napsaný. To si uvědomíte zejména ve chvíli, když si nemůžete v metru
přečíst článek jen proto, že se na zastávce nestihl načíst font
(obrázek vlevo):
Obrázek uprostřed a vpravo se liší v použitém fontu: jeden z nich je
nativní, druhý se natahuje z Google, což představuje řadu HTTP požadavků
a přenesených dat navíc. Kromě autora grafiky stejně nikdo nepozná, který
je který , tak
mobilům klidně ulevte:
/* font stáhneme jen na větších zařízeních */
@import "http://fonts.googleapis.com/css?family=PT+Serif" screen and (min-width: 500px);
body {
font: 18px/1.7 Georgia, serif;
}
@media (min-width: 500px) {
body { /* a font použijeme jen na větších zařízeních */
font-family: 'PT Serif', Georgia, serif;
}
}
Velikost písma
Obvykle používám na webech o něco větší písmo, než je běžné,
protože se mi parádně čte (třeba tento text má velikost 16px
s řádkováním 1.65, podle mě minimum). A to nemám žádné dioptrie, jen
je to příjemnější. Pro lidi s horším zrakem je větší font nutnost.
A na mobilu, který držíme v ruce, často v třesoucím se dopravním
prostředku nebo za chůze, je malé písmo důvod web vůbec nečíst.
Vyšší kontrast
Ironií je, že nejlepší displeje najdete v mobilech a tabletech, zatímco
do notebooků se dávají šunty. Na druhou stranu, z mobilu daleko častěji
čtete na přímém slunci, nebo si snižujete jas kvůli výdrži baterky,
tudíž jemnou hru odstínů tolik neoceníte. Přidejte na kontrastu:
body {
color: #555;
}
@media (max-width: 500px) {
body {
color: #111;
}
}
Vysoké rozlišení
Displeje s vysokým rozlišením (retina) zkomplikovaly životy kodérům,
do života vcházejí nové specifikace pro obrázkové elementy, grafiku je
třeba exportovat v řadě různých rozlišení … houby!
Vůbec si nekomplikujte život. Stačí si jen zvyknout exportovat
veškeré bitmapy ve dvojnásobném rozlišení (či vyšším) a změnu
velikosti nechat na prohlížeči. Kvalitnější obrázky chceme stejně
především kvůli mobilům. V případě fotografií v JPEG stačí snížit
kvalitu, nárůst velikosti souboru bude minimální a okem nepoznáte rozdíl.
Tedy na nízkém rozlišení, na vysokém bude mnohem prokreslenější.
Obrázek definovaný v CSS následně jen zmenšíte pomocí
background-size (umí všechny prohlížeče krom IE8, takže pro
něj budete zatím potřebovat i malý obrázek), obrázek v elementu
<img> pomocí atributu width nebo CSS. Třeba tady na blogu
všechny obrázky v článcích resizuju automaticky pomocí:
article img {
max-width: 100%;
height: auto;
}
Kde je to možné, použijte grafiku vektorovou. Jednobarevné ikony je
nejlepší vyexportovat jako font, protože jen tak jim můžete v CSS měnit
barvu. Můžete použít hotové sady nebo si vytvořit font na míru, šikovný
je na to třeba Fontastic.
Bacha na jednu věc: pokud bude font umístěn na jiné (sub)doméně, musí
jej server odesílat s HTTP hlavičkou
Access-Control-Allow-Origin: *.
Na co rozhodně nikdy nezapomeňte: políčkům pro zadávání emailů
nastavit <input type=email>.
V mobilním telefonu je mnohem lepší mít popisky nad prvky, aby při
vyplňování bylo vidět, co vlastně zadáváte, a ne jen řadu inputů. Tohle
umí šikovně řešit třeba Bootstrap v3, ale i mnoho jiných CSS
frameworků.
A nakonec
Na mobilech nejvíc bolí navazování HTTP požadavků, takže spojujte styly
a JavaScripty do jednoho souboru.
Isomorfní webové aplikace jsou takové, které sdílejí kód
mezi serverovou a klientskou stranou. Jinými slovy, jsou obě strany psané
v JavaScriptu. I když tak to vůbec nemuselo být, historie je
zajímavější.
Úplně poprvé jsem se s touto koncepcí setkal před (fíha, to je
neuvěřitelné) takřka 20 lety. Vlastně JavaScript přímo vznikl jako
client-side i server-side jazyk, serverové prostředí se jmenovalo Netscape
LiveWire a kód vypadal nějak
takto. Šlo tedy o mix HTML a JavaScriptu, jen s tím rozdílem, že
skript se vykonával na serveru. JavaScript byl zamýšlený jako jazyk pro
amatérské
programátory, jako konkurent tehdejšího PHP a Microsoftího ASP,
zatímco pro profesionály tu byla client-side a server-side Java.
Nic nedopadlo podle očekávání. Kvůli soudním sporům Java
z prohlížečů zmizela, ke konci se držela už jen v porno chatech a
bankovnictví, a dnes je z ní jeden velký bezpečnostní kráter
distribuovaný jako adware, který je nutno v prohlížečích
vypínat. Neuspěl ani JavaScript na serveru, protože byl příliš
nezralý a nevhodný na takové nasazení a serverové řešení upadajícího
Netscape nezískalo popularitu.
Vývoj webů na mnoho let zbrzdilo šílenství okolo specifikací
začínajících na X a monopol Internet Exploreru, ale pak došlo k jejich
svržení a máme tu hromadu nových technologií. A s tím se pochopitelně
vrací i otázka jednoho jazyka na obou stranách. Odstartoval to zejména
výkonnostně nadupaný interpret JavaScriptu z Google Chrome a platforma
Node.js.
Situace je dosti jiná, než před 20 lety:
- server-side technologie ušly obrovský kus cesty a vyzrály
- client-side prožívá pubertu
- v průniku jazyků je pouze JavaScript
Tvorba webů pomocí serverových frameworků se stává komoditou, na řadu
složitých otázek odpovídají zažité návrhové vzory. Na straně klienta
to naopak bují, dnešní novinky nejspíš brzy nahradí novinky jiné, a to se
ještě několikrát zopakuje. Tenhle stav je fajn, dohání se dlouhé
zpoždění a máte šanci se zapojit a odvětvím pohnout.
Dohání také JavaScript, leč jeho skutečnou pozici nejlépe
charakterizuje potřeba a popularita nejrůznějších nadstaveb, ať už jde
o CoffeeScript, Google Closure Compiler nebo TypeScript. Pomocí nich už dnes
lze z JavaScriptu udělat něco celkem robustního, což ale ve skutečnosti
stále není. Přičemž jazyky s ambicí jej nahradit existují.
Osobně mi cesta k izomorfním aplikacím připadá přirozená a správná.
U klientského skriptování jsem začínal a stále hledal různé spojnice,
například Nette má dosud poměrně ojedinělou vlastnost, že pravidla pro
validaci formulářů zapsaná na straně serveru vám automaticky překlopí na
stranu prohlížeče. Isomorfní validace formulářů od roku 2008.
Ale v žádném případě bych si isomorfně nenechal naprogramovat
třeba e-shop. Zatím.
Příliš mladé prostředí znamená absenci zažitých návrhových vzorů
a různá rizika. Když si Dan Steigerwald, který pro mě částečně
pochopitelně odmítá jakékoliv problémy této technologie
připouštět, si tuhle posteskl,
že čeští vývojáři jsou pozadu za frikulíny ze San Francisca a
stále se drží serverových technologií, rozjela se diskuse o výhodách a
nevýhodách jednotlivých přístupů a Dan jako odpověď na jednu námitku
poslal příklad webu (tuším jeho kolegů) iodine.com psaný v React.js.
Čímž poskytl pěkný příklad neduhů SPA/isomorfních aplikací:
- na webu nefunguje správně tlačítko zpět
- na mnoha různých URL se nachází identický obsah
- jeho výroba byla násobně dražší
Zdůrazňuji, že z jeho stany nešlo o ukázkový příklad, nicméně
tím lépe demonstruje hlavní problém SPA/isomorfních aplikací: udělat
je dobře je stále velmi těžké a potažmo drahé. Přičemž tentýž
web za použití server-side frameworku, jako je například Nette, zvládne
napsat i průměrný a levný programátor. A podobných hrubek se přitom
nedopustí.
Izomorfním aplikacím se nevyhýbejte, zkoušejte si novinky, zavčasu
odhalujte slepé cesty, rozšiřujte si obzory. Ale s ostrým nasazením se
držte jen u typů aplikací, kde je to skutečně nutné a výhodné. Není
jich zase tolik.
Navíc nemáte v žádné žhavé technologii jistotu. Tvrdit opak, třeba
proto, že za nějakou z nich stojí obří firma, znamená být slepý
k historii posledních 20 let.
Tuhle jsem zveřejnil skript na
cherry-pickování přímo z GitHubu, který dodnes používám, ale bylo
otravné tím stahovat celé pull requesty, pokud obsahovaly víc komitů.
Takže jsem ho naučil stahovat je na jeden zátah. Opět stačí jako argument
uvést URL:
php pullpick.php https://github.com/nette/tracy/pull/58
Oproti cherry-picku je potřeba navíc zjistit zdrojový repozitář a
větev, k čemuž použijeme GitHub
API. Skript vypadá takto:
<?php
$url = @$_SERVER['argv'][1];
if (!preg_match('#github.com/([^/]+)/([^/]+)/pull/(\w+)#', $url, $m)) {
die('Invalid URL');
}
list(, $name, $repo, $pull) = $m;
$context = stream_context_create(array('http' => array('user_agent' => 'Me')));
$info = file_get_contents("https://api.github.com/repos/$name/$repo/pulls/$pull", false, $context);
$info = json_decode($info);
if (!isset($info->head->repo->clone_url, $info->head->ref)) {
die('Missing repo info.');
}
passthru("git checkout -b pull-$pull master");
passthru("git pull --no-tags {$info->head->repo->clone_url} {$info->head->ref}");
Pull request se stáhne do nové větve s názvem jako
pull-123.
Mám i skript na vytvoření nového pull requestu. Spustíte jej ve větvi,
ze které chcete PR vytvořit, bez parametrů. On větev pushne do vašeho forku
a poté otevře prohlížeč s formulářem pro vytvoření pull requestu:
<?php
$remote = 'dg'; // tady dejte název 'remote' vedoucí k forku na GitHubu
exec('git remote -v', $remotes);
$repo = null;
foreach ($remotes as $rem) {
if (preg_match('#^' . preg_quote($remote) . '\tgit@github.com:(.+)\.git \(#', $rem, $m)) {
$repo = $m[1];
break;
}
}
if (!$repo) {
die('Not Github repo');
}
exec('git rev-parse --abbrev-ref HEAD', $branch);
$branch = $branch[0];
if (!$branch) {
die('Unable to retrieve branch name');
}
echo "Pushing to $repo & $branch\n";
exec("git push --set-upstream $remote $branch");
$url = "https://github.com/$repo/compare/$branch?expand=1";
exec('start "" ' . $url); // tohle otevře prohlížeč pod Windows. Pro jiné OS si upravte.
Mám skvělý pocit z právě vydané verze Nette 2.2.3, protože se tam
podařilo vychytat řadu drobností, počínaje chytřejším rozpoznání chyb u nativních
funkcí, přes výstižnější chybové hlášky DI kontejneru, až po
různé novinky (viz release
notes). Už jsem ji nasadil na všechny své weby a běží výborně.
Rád bych vypíchl 3 užitečné novinky. První se týká Latte a jde o funkci
invokeFilter(), kterou můžete volat filtr i mimo šablonu:
$latte = new Latte\Engine;
$latte->addFilter('upper', 'strtoupper');
$upper = $latte->invokeFilter('upper', array('abc')));
// obdoba {'abc'|upper} v šabloně
Druhá novinka se týká Tracy. Ta
nyní dokáže logovat chyby jako je E_NOTICE v plné náloži
(tj. s HTML souborem), jako když loguje výjimky. Které chyby má takto
logovat nastavíte do proměnné $logSeverity:
Tracy\Debugger::$logSeverity = E_NOTICE | E_WARNING;
Třetí novinka souvisí s bezpečností. Třída Configurator
má metodu setDebugMode(), pomocí které určujete, zda aplikace
poběží v produkčním nebo vývojářském režimu. Raději jí nikdy
nepředávejte argument true, může se pak snadno stát, že to
deploynete na ostrý server a máte hned bezpečnostní kráter. Správné je
jako argument předat IP adresy, pro které chcete vývojářský režim na
ostrém serveru povolit:
$configurator->setDebugMode('23.75.345.200');
Jenže IP adresy se mohou měnit a dostane ji někdo jiný. Proto je nově
možné přidat ještě pojistku v podobně cookie. Do cookie nazvané
nette-debug si uložíte tajný řetězec (buď funkcí setcookie
nebo pomocí vývojářského nástroje prohlížeče, každopádně
nezapomeňte na příznak httpOnly), například mysecret a
necháte Configurator, aby ověřoval i jej. Teprve sedí-li IP adresa
i hodnota v cookie, bude aktivován vývojářský režim:
$configurator->setDebugMode('mysecret@23.75.345.200');
Čtvrtá novinka ze tří se týká DI
kontejneru a je velmi dobře skrytá. Dovoluje nastavit, které třídy
vynechat z autowiringu. Typickým kandidátem je
Nette\Application\UI\Control, kterého vám může DI kontejner
cpát třeba do konstruktoru formuláře. Seznam ignorovaných tříd předáte
metodě ContainerBuilder::addExcludedClasses(). K té se dostanete
například v bootstrap.php:
$configurator->onCompile[] = function($configurator, $compiler) {
$compiler->getContainerBuilder()->addExcludedClasses(array(
'stdClass',
'Nette\Application\UI\Control',
));
};
A do pětice všeho dobrého: při vývoji můžete narazit na upozornění
Possible problem: you are sending a HTTP header while already having some data in output buffer. Try OutputDebugger or start session earlier.
To se objeví, když se snažíte odeslat HTTP hlavičky, a ono to sice ještě
jde, nicméně aplikace už nějaký výstup předtím odeslala, jen ho zachytil
output buffer.
V takové situaci je nejlepší nastartovat OutputDebugger
a zjistit, odkud se výstup posílal a předejít tomu. Od verze 2.2.3 máte
také možnost toto dobře míněné upozornění potlačit pomocí proměnné
Nette\Http\Response::$warnOnBuffer. Třeba opět z bootstrapu:
$container->getByType('Nette\Http\Response')->warnOnBuffer = false;
Do žebříčku 5 největších zrůdností jazyka PHP
rozhodně patří nemožnost zjistit, zda volání nativní funkce skončilo
úspěchem, nebo chybou. Ano, čtete správně. Zavoláte funkci a nevíte, zda
došlo k chybě a k jaké.
Teď si možná klepete na čelo a říkáte: selhání přece poznám podle
návratové hodnoty, ne? Hmmm…
Návratová hodnota
Nativní (nebo interní) funkce obvykle vracejí v případě neúspěchu
false. Jsou tu výjimky, například json_decode,
která vrací null, pokud je vstup nevalidní nebo překročí
limit zanoření. Což najdeme v dokumentaci, potud ok.
Tato funkce slouží k dekódování JSONu i jeho hodnot, tedy volání
json_decode('null') také vrátí null, tentokrát ale
jako korektní výsledek. Musíme tedy rozlišovat null jakožto
správný výsledek a null jakožto chybu:
$res = json_decode($s);
if ($res === null && $s !== 'null') {
// došlo k chybě
}
Je to hloupé, ale pámbů zaplať, že to vůbec lze. Existují totiž
funkce, u kterých nelze z návratové hodnoty poznat, že k chybě došlo.
Např. preg_grep nebo preg_split vrací částečný
výsledek, tedy pole, a nepoznáte vůbec nic (více v Zrádné regulární výrazy).
json_last_error & spol.
Funkce informující o poslední chybě v určitém rozšíření PHP.
Bohužel bývají mnohdy nespolehlivé a je obtížné zjistit, co to vlastně
ta poslední chyba je.
Například json_decode('') neresetuje příznak poslední
chyby, takže json_last_error vrací výsledek nikoliv pro
poslední, ale pro nějaké předchozí volání json_decode (viz
How to encode and decode JSON in
PHP?). Obdobně ani preg_match('neplatývýraz', $s) neresetuje
preg_last_error. Pro některé chyby nemají tyto funkce kód,
takže je vůbec nevrací, atd.
error_get_last
Obecná funkce vracející poslední chybu. Bohužel je nesmírně
komplikované zjistit, zda se chyba týkala vámi volané funkce. Onu poslední
chybu totiž mohla vygenerovat úplně jiná funkce.
První možností je přihlížet ke error_get_last() jen ve
chvíli, kdy návratová hodnota značí chybu. Bohužel třeba funkce
mail() umí vygenerovat chybu, i když vrátí true.
Nebo naopak preg_replace v případě neúspěchu nemusí chybu
generovat vůbec.
Druhou možností je před voláním naší funkce „poslední chybu“
vyresetovat:
@trigger_error('', E_USER_NOTICE); // reset
$file = fopen($path, 'r');
if (error_get_last()['message']) {
// došlo k chybě
}
Kód je zdánlivě jasný, chyba může vzniknout pouze při volání funkce
fopen(). Ale není tomu tak. Pokud je $path objekt,
bude převeden na řetězec metodou __toString. Pokud je to jeho
poslední výskyt, bude volán i destruktor. Mohou se volat funkce URL
wrapperu. Atd.
Tedy i zdánlivě nevinný řádek může vykonat spoustu PHP kódu, který
může generovat jiné chyby, z nichž poslední pak vrátí
error_get_last().
Musíme se proto ujistit, že k chybě došlo skutečně při volání
fopen:
@trigger_error('', E_USER_NOTICE); // reset
$file = fopen($path, 'r');
$error = error_get_last();
if ($error['message'] && $error['file'] === __FILE__ && $error['line'] === __LINE__ - 3) {
// došlo k chybě
}
Ona magická konstanta 3 je počet řádků mezi
__LINE__ a voláním fopen. Prosím bez
komentáře.
Tímto způsobem už chybu odhalíme (tedy pokud ji funkce emituje, což
třeba zmíněné funkce pro práci s regulárními výrazy zpravidla
nedělají), ale nejsme schopni ji potlačit, tedy zabránit tomu, aby se
zalogovala apod. Použití například shut-up operátoru @ je
problematické v tom, že zatají vše, tedy veškerý další PHP kód, který
se v souvislosti s naší funkcí volá (viz zmíněné destruktory,
wrappery atd.).
Vlastní error handler
Šíleným, ale zřejmě jediným možným způsobem, jak zjistit, zda
určitá funkce vyhodila chybu s možností ji potlačit, je instalace
vlastního chybového handleru pomocí set_error_handler. Jenže
není sranda to udělat správně:
- vlastní handler musíme také odstranit
- musíme jej odstranit i v případě, že se vyhodí výjimka
- musíme zachytávat skutečně jen chyby vzniklé
v inkriminované funkci
- a všechny ostatní předat původnímu handleru
Výsledek vypadá takto:
$prev = set_error_handler(function($severity, $message, $file, $line) use (& $prev) {
if ($file === __FILE__ && $line === __LINE__ + 9) { // magická konstanta
throw new Exception($message);
} elseif ($prev) { // volej předchozí uživatelský handler
return $prev(...func_get_args());
}
return false; // volej systémový handler
});
try {
$file = fopen($path, 'r'); // o tuhle funkci nám jde
} finally {
restore_error_handler();
}
Co je magická konstanta 9 už víte.
No a tak my v PHP žijem, no.