Už pár let jsem si pořádně nezakódoval a začalo mi to
chybět. Zachtělo se mi udělat stránky podle nejnovějších trendů.
Responsivní design okořeněný CSS preprocesory. Ale váhal jsem: jsou
preprocesory víc, než jen chvilková móda?
CSS preprocesor je nástroj, který vám ze zdrojového kódu zapsaného ve
vlastní syntaxi vygeneruje CSS pro prohlížeč. Mezi nejznámější patří
SASS, LESS
a Stylus.
Faktem je, že jakmile začne stylopis kynout do větších rozměrů, řada
věcí se řeší dosti nepohodlně. Je třeba vynaložit úsilí, aby zůstal
čitelný a srozumitelný. Aby se z něj nestal write-only soubor plný
magický konstant a hacků. Spoustu těchto nešvarů preprocesory řeší,
nejvíc se těším na vnořené
definice, matematické
výrazy, mixiny
a proměnné.
Vlastně je smutné, že preprocesory musely vzniknout. Ukazuje to na
zanedbanost vývoje CSS. Na druhou stranu, může z nich i těžit.
Preprocesory jsou mladé projekty procházející bouřlivým vývojem, reagují
na potřeby uživatelů a lze u nich, na rozdíl od standardu, tolerovat
i případné nekompatibilní změny. Ve finále tak mohou ukázat směr,
kterým se má vydat příští CSS.
Pokud se kódováním webů bavíte řadu let, máte vybudovanékonvence
pomáhající nedostatky obcházet. Preprocesory pak nemusí být úplně
samozřejmou volbou. Nicméně dnes je běžné používat různé CSS generátory a preprocesor nabízí
čistější cestu, než copy&pastovat vygenerovaný kód.
Rád zkouším nové věci, proto jsem dal preprocesorům šanci. Který ale
zvolit? Nejlepší je si všechny osahat.
Instalace
Začneme tedy rovnou instalací. Na webu SASS i LESS rychle najdete
vyčerpávající postup, jak knihovny získat. SASS je napsaný v Ruby, LESS v Node.js, takže prvním krokem bude instalace
překladače, což by neměl být v žádném operačním systému problém.
Preprocesor pak nainstalujete příkazem:
gem install sass
resp.
npm install less
Velmi snadné, PHP může závidět.
Naopak web Stylusu selhává, snaží se mást odkazy na Github, zatímco
informace, jak ho instalovat, je důmyslně skrytá kdesi vespod úvodní
stránky. Vězte tedy, že Stylus je také napsán v Node.js a nainstaluje se
obdobně příkazem npm install stylus.
Pozor na jednu věc, npm instaluje
balíček do aktuálního adresáře, takže abyste mohli preprocesory pohodlně
spouštět z příkazové řádky, musíte si cestu k lessc.cmd a
stylus.cmd přidat do proměnné PATH. Ve Windows se to dělá sparťansky, takže
spíš oceníte možnost nainstalovat balíčky do globálního adresáře
(pomocí přepínače -g, tj. npm install -g stylus),
ke kterému už cestu zaregistroval při instalaci překladač.
Příkazová řádka pro SASS a Stylus nabízí spoustu voleb, LESS umí jen
konvertovat vstupní soubor do výstupního CSS. Zmátlo mě, že SASS i Stylus
zavolané bez parametrů se nijak neohlásí a očekávají vstup
z klávesnice. Zavolejte je tedy s parametrem -h a vypíše se
nápověda všech voleb.
Vývoj a deployment
Preprocesory vyžadují, aby se mezi úpravou stylopisu a zobrazením
v prohlížeči udělat jeden krok navíc: kompilace do CSS.
Tento krůček může mnohé odradit. Pokud jste zvyklí rovnou editovat CSS
soubory na FTP serveru, nad preprocesorem vůbec neuvažujte. Existují sice
možnosti, jak třeba z LESS generovat CSS za běhu přímo v prohlížeči,
ale rozhodně nejsou určeny pro produkční nasazení.
Pokud máte deployment automatizovaný, stačí do procesu zařadit kompilaci
voláním příkazové řádky a je vystaráno.
Jak řešit onen krok navíc během vývoje? Kodéra rozhodně blbnutí
s příkazovou řádkou nezajímá a chce rovnou psát stylopis.
Jak jsem zmínil, LESS umí překládat stylopisy v prohlížeči, stačí
tedy zalinkovat soubor less.js a můžete rovnou připojovat soubory ve formátu
LESS (povšimněte hodnoty atributu rel):
SASS a Stylus zase nabízejí sledovací režim, ve kterém monitorují
adresář se styly ve svém formátu a při každé změně souboru je ihned
překládají do CSS.
// překlad souborů z adresáře /css.sass do /css (včetně podadresářů)
sass --watch css.sass:css
// překlad souborů z adresáře /css.stylus do /css
stylus --watch css.stylus --out css
Do vygenerovaného CSS lze pomocí přepínače --line-numbers
přidat pro lepší orientaci komentáře s číslem řádku zdrojového
souboru. Pokud vyvíjíte ve Firefoxu, ještě užitečnější je nainstalovat
FireStylus
a kompilovat s přepínačem --firebug. V záložce HTML by se
pak měly objevovat odkazy přímo na zdrojový soubor. Píšu měly, protože
mi to nefunguje.
Všechny tři preprocesory jsou seřazeny na startovní čáře. Který
z nich běží nejlépe? Pokračování příště.
(Doporučuji aktuálnější průvodce CSS preprocesory od Martina
Michálka, první a druhý
díl.)
I found a strange bug in Internet Explorer 9, which appears in the last
version 9.0.8112.16421. If the same cookie is sent twice, once with the
expiration at the end of the session and once with any other expiration, IE9
will remove cookie. Webpage must have a strict doctype.
Example:
<?php
// expire at the end of the session
setcookie('test', 'value', 0);
// expire in 1 hour
setcookie('test', 'value', 3600 + time());
// switch browser and document mode to IE9
?>
<!doctype html>
Is cookie set? <?php echo isset($_COOKIE['test']) ? 'yes' : 'no' ?>
S pomocí jQuery lze vytvořit HTML element docela jednoduše:
var $el = $('<a href="https://phpfashion.com">blogísek</a>');
Do proměnné $el se přiřadí objekt jQuery obalující
vytvořený HTML element (proto jsem použil dolar v názvu proměnné),
k nativnímu DOM objektu se dostanete přes $el[0].
Co ale v případě, že potřebujeme jako hodnoty použít proměnné?
Přímočaré řešení by vypadalo takto:
// špatně: riziko XSS
var url = 'https://phpfashion.com';
var title = 'blogísek';
var $el = $('<a href="' + url + '">' + title + '</a>');
Jenže, jak uvádí komentář v kódu, koledujeme si tímto o průšvih
jménem Cross-site scripting (XSS). Stačí, aby například proměnná
url obsahovala uvozovky a výsledek bude nezamýšlený. Proto je
nutné proměnné escapovat,
tj. nahradit znaky mající speciální význam za HTML entity. Na to si
můžeme napsat funkci escapeHtml:
// správné, ale ne příliš přehledné
var escapeHtml = function(s) {
return s.replace('&', '&').replace('"', '"')
.replace("'", ''').replace('<', '<');
};
var $el = $('<a href="' + escapeHtml(url) + '">' + escapeHtml(title) + '</a>');
Skládání řetězců postrádá onu lehkost a srozumitelnost první
ukázky, nemluvě o riziku, že escapeHtml zapomeneme zavolat.
Naštěstí jQuery od verze 1.4 nabízí elegantní řešení: proměnné
uvedeme ve druhém parametru (viz dokumentace)
// dokonalé
var $el = $('<a>', {
href: url,
text: title
});
Příjemné je, že takto lze kromě HTML atributů definovat i kaskádové
styly a události:
Otázka, kterou si klade řada webmasterů: vnímají vyhledávače tyto URL
jako stejné? Jak s nimi naložit?
http://example.com/article
http://example.com/article/
http://example.com/Article
https://example.com/article
http://www.example.com/article
http://example.com/article?a=1&b=2
http://example.com/article?b=2&a=1
Stručná odpověď by byla: „URL jsou odlišné.“ Chce to ale
podrobnější rozbor.
Z pohledu uživatelů se tyto adresy liší v drobnostech, kterým
nepřikládají žádnou váhu. Tedy je vnímají jako stejné, ačkoliv
z technického hlediska jde o adresy různé. Říkejme jim třeba adresy
podobné. V zájmu uživatelského
prožitku proto dodržujte 2 zásady:
Nedovolte, aby se na podobných adresách nacházel odlišný obsah.
Jak záhy ukážu, nevedlo by to jen ke zmatení uživatelů, ale
i vyhledávačů.
Umožněte uživatelům přístup i přes podobné adresy.
Pokud se adresy liší v protokolu http / https
nebo doméně s www či bez, považují je vyhledávače za
různé. Nikoliv tak uživatelé. Bylo by tedy fatální chybou na takto
podobné adresy umístit různý obsah. Nicméně chybou by bylo
i znemožnění přístupu přes podobnou adresu. Musí tedy fungovat
adresa s www i bez www. Přičemž SEO nabádá
držet se jedné varianty a ostatní na ni přesměrovávat HTTP kódem 301. To
lze u www subdomény zajistit například souborem
.htaccess:
# presmerovani na variantu bez www
RewriteCond %{HTTP_HOST} ^www\.
RewriteRule ^.*$ http://example.com/$0 [R=301,NE,L]
# presmerovani na variantu s www
RewriteCond %{HTTP_HOST} !^www\.
RewriteRule ^.*$ http://www.example.com/$0 [R=301,NE,L]
Schválně si hned vyzkoušejte, jestli vaše servery přesměrovávají a to
včetně celé adresy a správného
předání parametrů. Nezapomeňte i na varianty
www.subdomena.example.cz. Protože některé prohlížeče umí
chybějící přesměrování obcházet, zkuste raději nízkoúrovňovou
službu jako Web-Sniffer.
Velká a malá písmena se v URL rozlišují všude kromě schéma a
domény. Avšak uživatel je opět nerozlišuje a je tedy nešťastné nabízet
rozdílný obsah na adresách lišících se jen velikostí písmen. Jako
špatný příklad může posloužit Wikipedie:
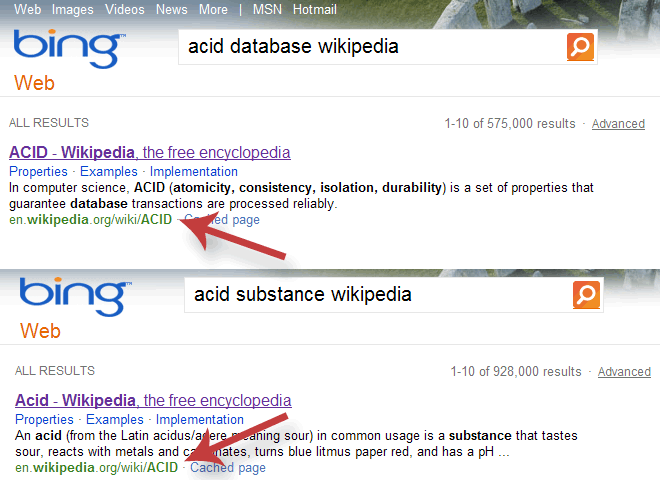
Kuriózní chybou trpí Bing, který vrací stejné URL, ať už hledáte
kyselinu nebo databázi (ačkoliv textový popis je správný). Google nebo
Yahoo tímto problémem netrpí.
Bing nerozlišuje mezi kyselinou a databází
Také některé služby (webmaily, ICQ) převádí velká písmenka v URL na
malá, což jsou všechno důvody, proč se rozlišování velikosti vyhnout a
to nejlépe i v parametrech. Raději dodržujte konvenci, že všechna
písmenka v URL budou malá.
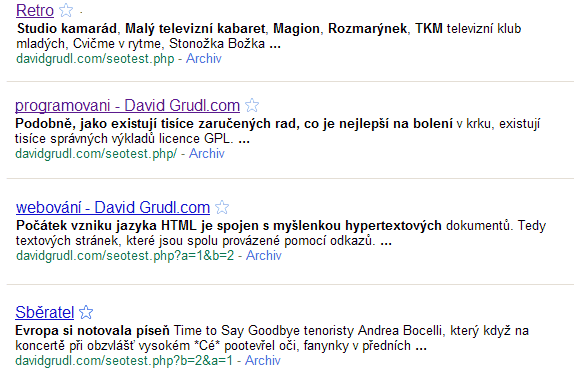
Rozlišit některé podobné adresy je oříšek i pro vyhledávače.
Udělal jsem experiment a na URL lišící se v detailech jako je přítomnost
pravostranného lomítka nebo pořadí parametrů umístil odlišný obsah.
Zaindexovat je byl schopen pouze Google. Ostatní vyhledávače dokázaly
pojmout vždy jen jednu z variant.
Jen Google tyto stránky umí indexovat jako rozdílné
Pokud jde o pravostranná lomítka, webový server přesměrovává na
kanonickou podobu obvykle za vás; přistoupíte-li k adresáři bez
pravostranného lomítka, doplní je a přesměruje. Samozřejmě to neplatí,
když URI spravujete ve vlastní režii (Cool URI apod.)
A nakonec: skutečně záleží na pořadí parametrů? Mezi adresou
article?a=1&b=2 a article?b=2&a=1 by neměl
být žádný rozdíl. Jsou ale situace, kdy to neplatí, zejména když
předáváme složitější struktury jako třeba pole. Například
?sort[]=name&sort[]=city může být něco jiného, než
?sort[]=city&sort[]=name. Nicméně přesměrovávat, nejsou-li
parametry ve stanoveném pořadí, bych považoval za zbytečnou
hyperkorektnost.
p. s. Nette Framework přesměrování na
kanonické URL provádí zcela automaticky ve své režii
Pracovat s webovým formulářem na straně JavaScriptu se poměrně snadno
může stát očistcem. Nebo jak se nazývá ta věc na čištění záchodové
mísy. Přitom za všechno může jedno nešťastné rozhodnutí.
K jeho jednotlivým prvkům přistoupíme přes vlastnost
elements:
var form = document.getElementById('myform');
var query = form.elements.query.value;
// pochopitelně také form.elements['query'].value
A iterovat nad prvky lze cyklem for:
for (var i = 0; i < form.elements.length; i++) {
alert(form.elements[i].value);
}
Z historických důvodů lze vlastnost elements v příkladech
vynechat, neboť jednotlivé prvky se mapují přímo do objektu
form. Takže by fungovalo i form.query.value,
form.length nebo form[i].value. Což se záhy ukáže
jako nemilé. Formulářové prvky totiž přepisují nativní
metody a proměnné objektu form. Například metoda submit(),
která je klíčová pro AJAXové odeslání formuláře, se stane nedostupnou,
pokud formulář obsahuje prvek nazvaný submit. A uznejte, že to
je zrovinka název pro odesílací tlačítko jako dělaný. Pokud by tedy
formulář vypadal takto
nebude jej možné příkazem form.submit() odeslat, místo toho
JavaScript zařve „form.submit is not a function“ a má pravdu,
form.submit není funkce ale objekt HtmlInputElement. Dobrá, dáme
si pozor a nebudeme formulářové prvky nazývat submit.
(prozradím trik, jak by formulář šlo odeslat i v tomto případě:
document.createElement('form').submit.call(form))
Jenže název submit není tím jediným, kterému se musíme
vyhnout. Prvek pojmenovaný elements způsobí, že
form.elements nebude očekávaná kolekce a výše uvedené
příklady skončí chybou. Název length zase znemožní nad
kolekcí iterovat. A tak by se dalo pokračovat, nativních prvků třeba DOM
Firefoxu definuje hodně přes stovku. Pro zajímavost uvádím seznam jen těch
jednoslovných (tj. vynechávám nodeName nebo
innerHTML):
Bylo by skvělé, kdyby se HTML5 dokázalo s tímto nešvarem vypořádat.
Zatím jsem ve specifikaci nic takového nenašel.
Podobně mi chybí možnost, jak v obsluze události onsubmit
zjistit, kterým tlačítkem byl formulář odeslán. Triviální a užitečná
věc a jak složitě se musí řešit.
Řeším to tak, že odchytávám událost click jednotlivých
tlačítek a název prvku ukládám do vlastní proměnné formuláře. O něco
jednodušší je využít bublání a odchytávat click přímo na
formuláři. Nicméně v HTML5 tohle už nebude fungovat spolehlivě, protože
prvek může být umístěn i mimo strom formuláře a přiřazen k němu
atributem form. Bylo by tedy fajn, kdyby HTML5 zavedlo vlastnost
například form.submitter, který by vracela název
odesílajícího tlačítka.
p. s. Nette Framework s těmito
situacemi počítá a snaží se je v rámci možností řešit za
programátora
Poslyšte příběh: klient si přál učinit svůj web hezčím a tak
jsem mu doporučil jednoho z těch mála dobrých tuzemských grafiků. Před
pár dny jsme měli schůzku a on se svěřil, že už dostal od grafika návrh
a není z něj gór šťastný. Že písmo je moc malé a celé je to jakési
kostrbaté. Nějak se mi to nezdálo, poprosil jsem ho, aby návrh otevřel, že
se na to podíváme. Dohledal email, odkliknul obrázek a naběhl mu výchozí
prohlížeč obrázků ve Windows. A protože obrázek měl větší rozměry,
zobrazil se (mírně) zmenšený. A hned bylo jasné, kde je
zakopaný pes.
Pokud klient není expert, nemá šanci zjistit, že se dívá na obrázek
zdeformovaný zmenšením. Prohlížeč obrázků ve Windows XP nebo Vista na to
nijak neupozorní. Ba co víc – i kdyby to zaregistroval, nejspíš se mu
nepodaří obrázek zvětšit na plnou velikost. Alespoň kolečkem myši nebo
klávesami +- to nejde. Ty obrázek
zvětšují/zmenšují o 20 % a hranici 100 % bez zastavení přeskočí.
Zobrazit jej v měřítku 1:1 vyžaduje fištróna.
Z příběhu vyplývá velmi cenná a nejspíš překvapivá zkušenost:
neposílejte klientům náhledy webů jako obrázek.
Jak tedy náhledy posílat? Nejvhodnější je klientovi poslat URL. Design
tak uvidí v kontextu webového prohlížeče a bude mít daleko ucelenější
dojem. Ale pozor, pokud byste poslali přímo URL obrázku, prohlížeč by jej
opět zmenšil. Je nad ním potřeba vytvořit HTML obálku. Nahrejte proto na
web kromě obrázku ještě soubor nahled.php:
Nedávno jsem se zúčastnil diskuse, která mi (opět)
připomněla, jak silně jsou u nás zakořeněné mýty týkající se
rozdílů mezi HTML a XHTML. Kampaň za formáty s písmenem X doprovázely
velké emoce a ty obvykle nechodí ruku v ruce s čistou hlavou. Sice
nadšení dávno opadlo, ale značná část odborné veřejnosti i autorit
dosud věří celé řadě bludů.
Pokusím se tímto článkem ty největší z nich pohřbít. A to
následujícím způsobem. Tento článek bude obsahovat pouze a jen
fakta. Své názory i vaše komentáře si nechám až na
článek druhý.
V následujícím textu pod termínem HTML rozumím verzi HTML 4.01, pod XHTML verzi XHTML 1.0 Second Edition. Pro úplnost
dodávám, že HTML je aplikací jazyka SGML,
zatímco XHTML je aplikací jazyka XML.
Mýtus: v HTML je
povolené křížení značek
Nikoliv. Křížení značek je zakázáno přímo v SGML, důsledkem
čehož i v HTML. Tento fakt je zmíněn například v doporučení W3C:
„…overlapping is illegal in SGML…“. Všechny tyto značkovací
jazyky chápou dokument jakožto stromovou strukturu, a právě proto není
možné značky křížit.
Zároveň tak reaguji i na reformulaci mýtu: „Výhodou XHTML je zákaz
křížení značek“. Není tomu tak, značky nelze křížit v žádné
existující verzi HTML nebo XHTML.
Mýtus:
XHTML zakázalo prezentační elementy a zavedlo CSS
Nikoliv. XHTML obsahuje tutéž sortu elementů, jako má HTML 4.01. Je to
zmíněno hned v prvním
odstavci XHTML specifikace: „Význam elementů a jejich atributů je
definován v doporučení W3C pro HTML 4“. Z tohoto pohledu mezi XHTML
a HTML žádný rozdíl neexistuje.
Některé elementy a atributy byly zapovězené (deprecated) již v HTML 4.01.
Prezentační elementy se tu zapovídají právě ve prospěch CSS, což je
také odpověď na druhou část mýtu: příchod kaskádových stylů s XHTML
nesouvisí, odehrál se již dříve.
Mýtus: HTML parser
musí tipovat konce značek
Nikoliv. V HTML je možné u definované skupiny
elementů volitelně neuvádět koncovou nebo počáteční značku. Jde
o elementy, u kterých vypuštění značky nemůže způsobit
nejasnost. Jako příklad si můžeme vzít koncovou značku u elementu
p. Jelikož norma říká, že se odstavec nemůže nacházet
uvnitř jiného odstavce, je v případě zápisu…
<p>....
<p>....
…jednoznačně dáno, že otevřením druhého odstavce se musí uzavřít
ten první. Uvedení koncové značky je tedy redundantní. Naopak třeba
element div může být zanořený sám v sobě, proto u něj je
počáteční i koncová značka povinná.
Mýtus: zápis
atributů v HTML je nejednoznačný
Nikoliv. XHTML vždy vyžaduje uzavírat hodnoty atributů do uvozovek nebo
apostrofů. HTML to vyžaduje
také, s výjimkou, pokud hodnotu tvoří alfanumerický řetězec. Pro
úplnost dodám, že i v těchto případech specifikace doporučuje
uvozovky užít.
Tedy v HTML je přípustné zapsat
<textarea cols=20 rows=30>, což je formálně stejně
jednoznačné, jako <textarea cols="20" rows="30">. Pokud by
hodnota obsahovala více slov, HTML trvá na užití uvozovek.
Mýtus: HTML dokument je
nejednoznačný
Nikoliv. Jako důvod nejednoznačnosti se uvádí buď možnost křížení
značek, nejednoznačnost zápisu atributů bez uvozovek, což jsou již
vyvrácené mýty, nebo také možnost některé značky vynechávat. Tady
zopakuji, že skupina elementů, u kterých je možné značky vynechávat, je
zvolena tak, aby se vynechala pouze redundantní informace.
HTML dokument je tedy vždy jednoznačně určen.
Mýtus: až v XHTML se
píše znak & entitou &
Nikoliv – musí se tak psát i v HTML. Pro oba jazyky mají znaky
< a & specifický význam. První otevírá
značku a druhý entitu. Aby nebyly chápány v jejich meta-významu, musí se
zapsat entitou. Tedy i v HTML, jak uvádí specifikace.
Mýtus:
HTML dovoluje ‚prasárny‘, které Vám v XHTML neprojdou
Nikoliv. Tento názor má kořeny v řadě mýtů, které už jsem vyvrátil
výše. Ještě jsem nezmínil, že XHTML u jmen elementů a atributů na
rozdíl od HTML rozlišuje velikost písmen (je „case sensitive“). Nicméně
jde o zcela legitimní vlastnost jazyka. Takto se liší například Visual
Basic od C# a nelze objektivně říci, že jeden nebo druhý přístup by byl
horší. HTML kód je možné znepřehlednit tím, že budeme nevhodně
střídat velká a malá písmena (<tAbLe>), XHTML kód
zase třeba používáním řetězců abc, AbC,
aBC pro odlišné třídy XML kód zase třeba používáním
řetězců id, ID, Id pro odlišné
atributy.
Čistota zápisu v žádném případě nesouvisí s volbou jednoho nebo
druhého jazyka.
Mýtus: Parsování XHTML je
mnohem snazší
Nikoliv. Srovnání na miskách vah by bylo subjektivní, a tedy nemá
v tomto článku místo, objektivně však lze prohlásit, že není žádný
důvod, proč by jeden z parserů měl mít výrazně jednodušší život.
Každý z nich má na krku jiný balvan.
Parsování HTML je podmíněno faktem, že parser musí znát definici typu
dokumentu. Prvním důvodem je existence volitelných značek. Ačkoliv je
jejich doplňování jednoznačné (viz výše) a algoritmicky snadno
řešitelné, tak parser musí příslušnou definici znát. Druhým důvodem
jsou prázdné elementy. Že je element prázdný ví parser pouze
z definice.
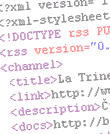
Parsování XHTML je zase ztíženo tím, že dokument může (na rozdíl od
HTML) obsahovat interní podsadu DTD s definicí vlastních entit (viz příklad). Raději
dodávám, že „entita“ nemusí představovat jeden znak, ale libovolně
dlouhý úsek XHTML kódu (obsahující případně další entity). Bez
zpracování DTD a ověření jeho správnosti vůbec nelze o parsování XHTML
hovořit. Věc navíc zkomplikuje to, že syntakticky je DTD v podstatě
protipólem jazyka XML.
Shrnuto: jak HTML tak XHTML parser musí znát definici typu dokumentu. XHTML
parser ji navíc musí umět číst v DTD jazyce.
Mýtus: Parsování XHTML
je mnohem rychlejší
Z hlediska syntaktické podobnosti obou jazyků je rychlost parsování
dána pouze šikovností programátorů jednotlivých parserů. Čas potřebný
pro strojové zpracování běžné webové stránky (ať už HTML nebo XHTML)
na běžném počítači je lidským vnímáním nepostřehnutelný.
Mýtus: HTML parser si musí
vždy poradit
Nikoliv. Specifikace HTML nenařizuje,
jak se má aplikace zachovat v případě zpracování chybného dokumentu.
Z důvodu konkurenceschopnosti v reálném prostředí došlo k tomu, že
prohlížeče se staly zcela tolerantní k vadným HTML dokumentům.
Jinak je tomu v případě XHTML. Specifikace odvoláním na XML nařizuje,
že parser v případě chyby nesmí pokračovat v dalším zpracování
logické struktury dokumentu. Opět z důvodu konkurenceschopnosti v reálném
světě došlo k tomu, že RSS čtečky se staly tolerantní k vadným XML
dokumentům (RSS je aplikací XML, stejně jako XHTML).
Pokud bychom chtěli z tolerantnosti webových prohlížečů něco
negativního usuzovat o HTML, pak nutně musíme z tolerantnosti RSS čteček
něco negativního usuzovat o XML. Objektivně lze shrnout, že drakonický přístup XML
k chybám v dokumentech je utopistický.
Závěr?
Pokud už nemáte mysl zatíženou žádným z výše uvedených mýtů,
můžete mnohem lépe vnímat rozdíl mezi HTML a XHTML. Lépe řečeno můžete
lépe vnímat, že tam žádný rozdíl není. Skutečný rozdíl se odehrává
až o patro výše: je jím opuštění SGML a přechod k novému XML.
Bohužel nelze říci, že XML pouze řeší problémy SGML a žádné nové
nepřidává. Jen v tomto článku jsem na dva narazil. Jedním z nich je
drakonické zpracování chyb v XML, které není v souladu s praxí, a tím
druhým je existence odlišného jazyka DTD uvnitř XML, které komplikuje
parsování i srozumitelnost XML dokumentů. Navíc vyjadřovací schopnost
tohoto jazyka je tak malá, že nedokáže formálně postihnout ani samotné
XHTML, takže některé vlastnosti je nutné dodefinovat zvlášť.
U jazyka, který není svázán historickými okovy, je to smutné a
zarážející zjištění. Kritika XML je však téma na samostatný
článek.
(Pokud narazím na další mýty, budu článek postupně doplňovat.
Budete-li chtít na ně odkazovat, můžete využít toho, že jednotlivé
titulky mají vlastní ID)
Jak účinně zamaskovat e-maily před zraky spamových
robotů? To měl zjistit půlroční experiment. Jenže výsledky jsou docela
překvapivé.
Trocha teorie
Důležitým zdrojem, kde spammeři získávají e-mailové adresy, jsou
webové stránky. Těmi procházejí roboti a adresy hromadně extrahují. Proto
se doporučuje zapisovat e-maily ve formě pochopitelné člověku, avšak
nepochopitelné stroji. Například ve tvaru
franta (at) example.cz. Jenže i tento zápis může některým
lidem připadat matoucí, naopak robot se mu může přizpůsobit. Proto se
vymýšlejí stále sofistikovanější způsoby, jak adresu zakamuflovat
(klíčové slovo: obfuscate email).
V této souvislosti se pochlubím s nápadem, jak neviditelně zastřít
e-mail pomocí HTML komentáře.
Použil jsem ho v Texy2 a nahradil jím méně přístupné (at) zavináče z Texy 1.
Jenže je otázka, jak chytří spamoví roboti skutečně jsou? Který
způsob maskování je dostatečný? Proč to nevyzkoušet.
Roboti pod lupou
Jako pokusného králíka jsem použil tento blog. GTPR 6 a cca
350 stránek obsahu by mělo škodnou přilákat.
Protože jsem od robotů žádné zázraky nečekal, nejprve jsem ověřil,
jestli vůbec převádějí HTML entity na znaky
(v řeči PHP: zavolají html_entity_decode). Pokud by je
totiž zmátlo primitivní používání entit, nemusel bych
experimentovat dál.
Na všechny stránky La Trine jsem na půl roku umístil skryté
pastičky:
// 1) nechráněná e-mailová adresa v textu stránky
<a href="mailto:foo">test@example.com</a>
// 2) nechráněná e-mailová adresa jako odkaz
<a href="mailto:test@example.com">foo</a>
// 3) "mailto:" chráněné HTML entitami
<a href="mailto:test@example.com">foo</a>
// 4) zavináč chráněný HTML entitou
<a href="mailto:test@example.com">foo</a>
// 5) kombinace bodů 3) a 4)
<a href="mailto:test@example.com">foo</a>
Test ukázal, že náhrada zavináče HTML entitou je zcela dostačující
ochranou. Po půl roce dorazily jen tři spamy! A to ještě mohl mít na
svědomí slovníkový útok.
Tím bych mohl článek ukončit. Nejlepší prevence se jmenuje
@. Jenže…
Skutečné zdroje e-mailových
adres
Jak jsem zmínil, do pastiček č. 4 a 5 spadly jen tři spamy. Návnady
č. 2 a 3 přilákaly 85 kousků a
prim pochopitelně drží zcela nechráněný e-mail se 126 zářezy.
Jenže, 126 spamíků za půl roku je nějak podezřele málo. Do mé
schránky jich víc dorazí za jediný den! Jak je to možné?
Po pravdě, netuším. Nejspíš se webové stránky staly zcela okrajovým
zdrojem e-mailových adres. Spameři už loví jinde. Možná se zaměřují na
malware, který šíří do
cizích počítačů. Záškodnický program pak sám rozesílá spam a
e-mailové adresy čerpá z poštovních klientů (adresář + doručená
pošta). Nebo je to úplně jinak…
Všechno je jinak. Ti, co měli pravdu, nám lhali, zatímco
kacíři to s námi mysleli dobře.
Prolog
Začátkem letošního roku napsal Chamurappi na Lupu poměrně neaktuální
článek Soumrak nad
moderním X. Má smysl ještě dnes vyvracet dávno vyvrácené mýty
o XHTML? Ptal jsem se sám sebe. K mému překvapení se pod článkem
rozhořela plamenná diskuse plná emotivních výkřiků, které mě vrátily
do dob nejtvrdší evangelizace. Pochopil jsem, že za ty roky mýty spíš
zakořenily.
Laikům budiž odpuštěno. Jenže v oné diskusi dostala také řada
osobností domácího webdesignu příležitost se historicky znemožnit. Dostala a využila. Přiznám se,
že jsem to dlouho nemohl rozdýchat. S odstupem času to vnímám jako
důležitou životní zkušenost.
Dějství první
Jak se blížilo desetileté výročí vývojového patu XHTML & CSS,
přemýšlel jsem, jak k němu vůbec mohlo dojít. Jak je možné, že
v době neomezené celosvětové komunikace není lidstvo schopno
řešit technické záležitosti? Vlastně celkem banální. Co je HTML markup
proti sestavení vesmírné rakety? Neschopnost řešit humanitní problémy je
pochopitelná, ale i technické?
Získal jsem pocit, že hlavní mozky W3C trpí syndromem mrtvého
koně. Cválají dál na oři jménem XHTML a nechtějí si připustit, že
už je napůl v salámu. Že drakonickým pravidlům XML specifikace nelze
v reálném světě dostát. Že DTD má příliš slabé vyjadřovací
schopnosti, přičemž umí spoustu věcí značně zkomplikovat. Ale hlavně,
že autorům webových stránek slavné XHTML vůbec nic nedalo. Ačkoliv
touží po tolika nových vlastnostech, počínaje lepšími formuláři, konče
třeba elementem pro video.
Pak jsem si uvědomil, že onou neschopností netrpí jen W3C. Dnes a denně
jsme obětí jiné neschopnosti – neschopnosti vylepšit e-mailový protokol
a zbavit se tak tun spamu. A podobných příkladů lze najít celou řadu.
Začalo mi docházet, že problémem ve stáji W3C nebude zesnulý hřebec. Oči
mi otevřela zmíněná diskuse na Lupě. Problémem je komunikace. Tedy
příliš mnoho komunikace. Komunikující komunita. Největší význam pro
rozvoj civilizace má jedinec. Komunita je mor.
První verzi HTML vymyslel jeden chytrej chlap. Jakmile se dalo dohromady
hodně chytrejch chlapů, dopadlo to prachbídně.
Poznámka: jak začnete úvahy rozvíjet dál, zpochybníte si
i principy demokracie. Dnes je mi hodně blízký Aristoteles a sympatizuji
s jeho třemi
právními formami státu.
Dějství druhé
Kupodivu i v oboru webdesignu se našel jednotlivec s ambicemi spasit
HTML. Ian Hixie Hickson se pro mě stal jiskřičkou na konci tunelu, a
to i přesto, že s mnoha jeho názory se neztotožňuji. Jenže, je chytrej,
má obrovské zkušenosti a hlavně – je to jednotlivec 🙂 Holt komunitám
nevěřím. Teď, v době Webu 2.0 🙂
A pak se to stalo! Pak to bouchlo! V květnu W3C
adoptovalo HTML 5, vypiplané dítě Iana Hicksona. Mezi řádky lze číst,
že tím vlastně odpískalo projekt XHTML. Nikdo to nahlas neřekne.
Ještě před pár lety se na HTML vs. XHTML vypisovaly kurzy přesně
opačné. Neuvěřitelné se stalo skutečností.
(pro srandu králíkům, srovnejte úroveň diskusí pod oběma
odkazovanými články na Lupě)
Epilog
Chamurappi může prožívat obrovskou satisfakci. Dlouhé roky upozorňoval
na vady X-specifikací a byl za to nelichotivě častován. A najednou mu
historie, jindy tak nespravedlivá, dala za pravdu. Vlastně se divím, že na
Webylonu letošní převrat vůbec nereflektoval. Mohl napsat: „já vám to
celou tu dobu říkal, vy pitomci.“ Měl by na to právo.
Je docela zvláštní, že o novém svěžím větru informuje
pouze Martin Hassman. Nu což, dělá
to výborně. Také mám v plánu o HTML 5 občas psát. Z toho téma sálá
nadšení a pocit naděje.

{kind=link}