Pokud píšete vlastní error handler pro PHP, je
bezpodmínečně nutné dodržet několik pravidel. Jinak může nabourat
chování dalších knihoven a aplikací, které nečekají v error
handleru zradu.
Parametry
Signatura handleru vypadá takto:
function errorHandler(
int $severity,
string $message,
string $file,
int $line,
array $context = null // pouze v PHP < 8
): ?bool {
...
}
Parametr $severity obsahuje úroveň chyby
(E_NOTICE, E_WARNING, …). Pomocí handleru nelze
zachytávat fatální chyby, jako třeba E_ERROR, takže těchto
hodnot nikdy nebude parametr nabývat. Naštěstí fatální chyby v podstatě
z PHP zmizely a byly nahrazeny za výjimky.
Parametr $message je chybová hláška. Pokud je zapnutá
direktiva html_errors,
jsou speciální znaky jako < apod. zapsány jako HTML entity,
takže do podoby plain textu je musíte dekódovat.
Ovšem pozor, některé znaky jako entity zapsány nejsou, což je bug.
Samotné zobrazování chyb v čistém PHP je tak náchylné na XSS.
Parametry $file a $line představují název
souboru a řádek, kde k chybě došlo. Pokud chyba nastala uvnitř
eval(), bude $filedoplněný o tuto informaci.
A nakonec parametr $context obsahuje pole lokálních
proměnných, což představuje pro debugování užitečnou informaci, ale od
PHP 8 je zrušený. Pokud má handler fungovat v PHP 8, parametr vynechte nebo
mu dejte výchozí hodnotu.
Návratová hodnota
Návratová hodnota handleru může být null nebo
false. Pokud handler vrátí null, nestane se nic.
Pokud vrátí false, zavolá se ještě standardní PHP handler.
Ten podle konfigurace PHP může chybu vypsat, zalogovat atd. Co je důležité,
tak že také naplní interní informaci o poslední chybě, kterou
zpřístupňuje funkce error_get_last().
Potlačené chyby
V PHP lze potlačit zobrazování chyb buď pomocí shut-up operátoru
@ nebo pomocí error_reporting():
// potlač chyby úrovně E_USER_DEPRECATED
error_reporting(~E_USER_DEPRECATED);
// potlač všechny chyby při volání fopen()
$file = @fopen($name, 'r');
I při potlačení chyb dojde k volání handleru. Proto je nejprve
nutné ověřit, zda chyba je potlačená, a pokud ano, tak musíme
vlastní handler ukončit:
if (!($severity & error_reporting())) {
return false;
}
Ale pozor, musíme je v tomto případě ukončit pomocí
return false, aby se spustil ještě standardní error handler. Ten
nic nevypíše ani nezaloguje (protože chyba je potlačená), ale zajistí, že
chybu půjde zjistit pomocí error_get_last().
Ostatní chyby
Pokud náš handler chybu zpracuje (například vypíše vlastní hlášku
atd.), už není potřeba volat standardní handler. Sice pak nebude možné
chybu zjistit pomocí error_get_last(), ale to v praxi nevadí,
protože tato funkce se používá především v kombinaci s shut-up
operátorem.
Pokud handler naopak chybu z jakéhokoliv důvodu nezpracuje, měl by
vrátit false, aby ji nezatajil.
Ukázkový příklad
Takto by vypadal kód vlastního error handleru, který transformuje chyby na
výjimky ErrorException:
set_error_handler(function (int $severity, string $message, string $file, int $line) {
if (!(error_reporting() & $severity)) {
return false;
}
throw new \ErrorException($message, 0, $severity, $file, $line);
});
Po dvou verzích PHP, které nepřinesly nic moc zajímavého, se blíží
verze, pro kterou bude mít opět smysl aktualizovat knihovny. Jde o PHP 7.4 a
hlavním tahákem jsou typed properties, které
uzavírají mnohaletý posun ke striktně typovanému jazyku, což PHP
zvýhodňuje oproti jiným webovým jazykům.
Ve zkratce, tahle novinka vám umožní deklarovat typy přímo
u proměnných třídy:
class Config
{
public string $dsn;
public ?string $user;
public ?string $password;
public bool $debugger = true;
}
Je potřeba říct, že pokud jste si navykli používat privátní
proměnné a přistupovat k nim přes typehintované metody (což je
správně), tak vlastně o žádnou killer feature nejde. Druhotná kontrola
typů je zbytečná a vlastně jen zpomaluje kód. Diametrálně jiná situace
se týká public/protected proměnných, kde dosud neexistoval žádný způsob,
jak mít jejich hodnotu (a dokonce existenci) pod kontrolou. Až dosud.
Což nevyhnutelně povede k otázce:
Je nutné dál psát settery a
gettery?
Sice veškerý boilerplate kód nám dnes na kliknutí generují editory, ale
určitě vypadá hezky, když tohle:
class Circle
{
private $radius;
function setRadius(float $val)
{
$this->radius = $val;
}
function getRadius(): float
{
return $this->radius;
}
}
nahradíte za:
class Circle
{
public float $radius;
}
Nehledě na to, že i užití objektu je stručnější
$circle->radius = $x vs
$circle->setRadius($x).
Problém ale je, že velkou spoustu setterů a getterů nelze jednoduše
nahradit. Třeba zrovna v uvedeném příkladu by se hodilo ještě ověřit,
že poloměr není záporné číslo:
function setRadius(float $val)
{
if ($val < 0) {
throw new InvalidArgumentException;
}
$this->radius = $val;
}
A v ten moment už nelze kód zredukovat do veřejné proměnné.
Jindy zase chceme, aby jednou nastavená hodnota byla neměnná, což nelze
u public proměnné zajistit.
Nebo vůbec nechceme dávat k dispozici getter, protože nepatří do
veřejného API třídy.
Anebo chceme mít setter či getter součástí rozhraní.
Atd, atd.
Zkrátka někdy bude možné použít typované veřejné proměnné místo
metod, jindy ne, rozdíl bude dost často otázkou vnitřní implementace
třídy a pro uživatele neprůhledný. Což je cesta v nekonzistentnímu API,
kdy jednou se používá proměnná, jindy metoda a uživatel v tom nevidí
logiku. (Podobně jako třeba metoda PDOStatement::errorInfo() vs.
proměnná PDOException::$errorInfo).
Prohlubování nekonzistence ale nechceš. Raději konzistentní setrvání
u metod, privátních proměnných a všeho toho boilerplate kódu. A pro
privátní proměnné, jak jsem zmiňoval v úvodu, je přínos typehintů
sporný. Nebo ne?
V čem je tedy výhoda?
Vlastně je výhod dost, i když v jiných oblastech. Typované proměnné
budou užitečné pro kompilátor kvůli optimalizacím, pro práci s reflexí
nebo nástroje analyzující kód. Důležité budou v šedé zóně protected
proměnných. Umožňují zapsat prostředky jazyka to, co se dosud obcházelo
komentářem. A navíc přinášejí do jazyka nový příznak neinicializovaného
stavu, jakousi obdobu undefined z JavaScriptu.
Jak mockovat třídy, které jsou definované jako final nebo
některé z jejich metod jsou final?
Mockování znamená nahrazení původního objektu za jeho testovací
imitaci, která neprovádí žádnou funkci a jen se tváří jako původní
objekt. A předstírá chování, které potřebujeme kvůli testování.
Takže například místo objektu PDO s metodami jako query() apod.
vytvoříme jeho mock, který práci s databází jen předstírá, a místo
toho ověřuje, že se volají ty správné SQL příkazy atd. Více třeba
v dokumentaci
Mockery.
A aby bylo možné mock předávat metodám, které mají type hint
PDO, je potřeba, aby i třída mocku dědila od PDO. A to může
být kámen úrazu. Pokud by totiž třída PDO nebo metoda query() byla final,
už by to nebylo možné.
Existuje nějaké řešení? První možnost je final vůbec
nepoužívat. To ovšem nepomůže s kódem třetích stran, který final
používá, ale hlavně se tím ochuzujeme o důležitý prvek objektového
návrhu. Existuje dogma, že každá třída by měla být buď final, nebo
abstract.
Druhou a velmi šikovnou možností je použít Nette Tester, který od verze 2.0 disponuje
vychytávkou, která odstraňuje z kódu klíčové slovo final
on-the-fly. Stačí na začátku testu zavolat:
Pozn.: v nejnovějších verzích Nette 2.4 až je tato anotace přímo v kódu.
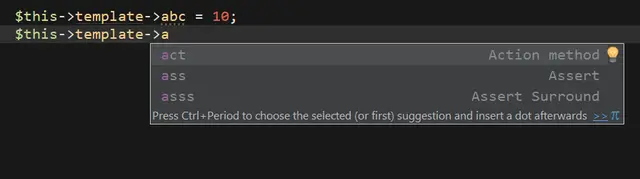
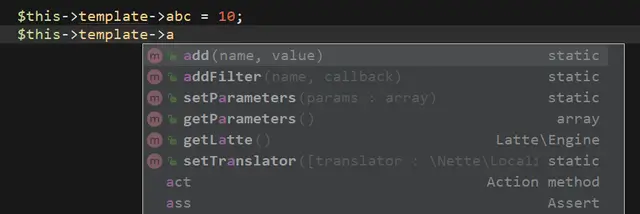
Třída šablony
Třída stdClass v anotaci je workaround pro PhpStorm, který
jinak všechny proměnné považuje za nedefinované. Nicméně zajímavější
je si vytvořit třídu se seznamem skutečných proměnných, které šablona
má, včetně jejich typů. Může vypadat třeba takto:
class ArticleTemplate extends Nette\Bridges\ApplicationLatte\Template
{
/** @var string */
public $lang;
/** @var int */
public $page;
/** @var string[] */
public $menu;
/** @var Model\Page */
public $article;
}
a potom ji v anotaci konkrétního presenteru uvedeme namísto
stdClass:
/**
* @property-read ArticleTemplate $template
*/
final class ArticlePresenter extends Nette\Application\UI\Presenter
Od této chvíle je napovídání perfektní:
Aktualizace: Latte
plugin už podporuje napovídání přímo v šablonách. Stačí přidat
{templateType App\Presenters\ArticleTemplate} na začátek
šablony.
A co se ani v dokumentaci nedočtete, včetně záplaty na
bezpečnostní díru a rady, jak zrychlit odezvu serveru a naopak ji
nezbrzdit.
Output buffering umožňuje, aby výstup PHP skriptu (především funkcí
echo) nebyl okamžitě odeslán do prohlížeče nebo terminálu,
ale byl uchováván v paměti (tj. bufferu). Což se hodí k celé
řadě věcí.
Zabránění vypisování na výstup:
ob_start(); // zapne output buffering
$foo->bar(); // veškerý výstup jde pouze do bufferu
ob_end_clean(); // buffer smaže a ukončí buffering
Zachytávání výstupu do proměnné:
ob_start(); // zapne output buffering
$foo->render(); // výstup jde pouze do bufferu
$output = ob_get_contents(); // obsah bufferu uloží do proměnné
ob_end_clean(); // buffer smaže a ukončí buffering
$output = ob_get_clean(); // obsah bufferu uloží do proměnné a vypne buffering
V uvedených příkladech se obsah bufferu na výstup vůbec nedostal. Pokud
jej naopak na výstup poslat chci, namísto ob_end_clean() jej
ukončím funkcí ob_end_flush()
. Pro současné získání obsahu bufferu, odeslání na výstup a ukončení
bufferování existuje opět zkratka (i včetně chybějícího
end v názvu): ob_get_flush().
Buffer lze kdykoliv vyprázdnit i bez nutnosti jej ukončit, a to pomocí ob_clean()
(smaže jej) a nebo ob_flush()
(pošle jej na výstup):
ob_start(); // zapne output buffering
$foo->bar(); // veškerý výstup jde pouze do bufferu
ob_clean(); // smažu obsah bufferu, ale buffering zůstává aktivní
$foo->render(); // výstup jde stále do bufferu
ob_flush(); // buffer posílám na výstup
$none = ob_get_contents(); // obsah bufferu je nyní prázdný řetězec
ob_end_clean(); // vypne output buffering
Do bufferu se posílá i výstup zapisovaný na php://output,
naopak buffery lze obejít zápisem na php://stdout (nebo do
STDOUT), což je k dispozici pouze pod CLI, tedy při spouštění
skriptů z příkazové řádky.
Zanoření
Buffery je možné zanořovat, takže zatímco je jeden buffer aktivní,
dalším voláním ob_start()
se aktivuje buffer nový. Tedy ob_end_flush() a
ob_flush() neposílají obsah bufferu na výstup, ale do
nadřazeného bufferu. A teprve když žádný nadřazený není, posílá se
obsah na skutečný výstup, tj. do prohlížeče nebo terminálu.
Proto je důležité buffering ukončit, a to i v případě, že
v průběhu nastane výjimka:
ob_start();
try {
$foo->render();
} finally { // finally existuje od PHP 5.5
ob_end_clean(); // nebo ob_end_flush()
}
Velikost bufferu
Buffer může také zrychlit
generování stránky tím, že se do prohlížeče nebude odesílat
každé jednotlivé echo, ale až větší objem dat (například
4kB). Stačí na začátku skriptu zavolat:
ob_start(null, 4096);
Jakmile velikost bufferu překročí 4096 bajtů (tzv.
chunk size), automaticky se provede flush, tj. buffer
se vyprázdní a odešle ven. Téhož se dá dosáhnout i nastavením direktivy
output_buffering.
V CLI režimu se ignoruje.
Ale pozor, spuštění bufferingu bez uvedení velikosti, tedy
prostým ob_start(), způsobí, že se stránka nebude neodesílat
průběžně, ale až se vykreslí celá, takže server bude naopak působit
velmi líně!
HTTP hlavičky
Output buffering nemá žádný vliv na odesílání HTTP hlaviček, ty se
zpracovávají jinou cestou. Nicméně díky bufferingu je možné odeslat
hlavičky i poté, co se vypsal nějaký výstup, jelikož se stále drží
v bufferu. Ovšem jde o vedlejší efekt, na který neradno spoléhat,
protože není jistota, kdy výstup překročí velikost bufferu a
odešle se.
Bezpečnostní díra
Při ukončení skriptu se všechny neukončené buffery vypíší na
výstup. Což lze považovat za nepříjemnou bezpečnostní díru, pokud si
například v bufferu připravujete citlivá data, která nejsou určená pro
výstup a dojde přitom k chybě. Řešením je použít vlastní handler:
ob_start(function () { return ''; });
Handlery
Na output buffering lze navázat vlastní handler, tj. funkci, která obsah
paměti zpracuje před odesláním ven:
ob_start(
function ($buffer, $phase) { return strtoupper($buffer); }
);
echo 'Ahoj';
ob_end_flush(); // na výstup se dostane AHOJ
I funkce ob_clean() nebo ob_end_clean() vyvolají
handler, ale výstup zahodí a ven neposílají. Přičemž handler může
zjistit, která funkce je volána a reagovat na to. Používá se k tomu druhý
parametr $phase, což je bitová maska (od PHP 5.4):
PHP_OUTPUT_HANDLER_START při otevření bufferu
PHP_OUTPUT_HANDLER_FINAL při ukončení bufferu
PHP_OUTPUT_HANDLER_FLUSH při volání ob_flush()
(ale nikoliv ob_end_flush() nebo ob_get_flush())
PHP_OUTPUT_HANDLER_CLEAN při volání ob_clean(),
ob_end_clean() a ob_get_clean()
PHP_OUTPUT_HANDLER_WRITE při automatickém
flush
Fáze start, final a flush (resp. clean) mohou klidně nastat současně,
rozliší se pomocí binárního operátoru &:
if ($phase & PHP_OUTPUT_HANDLER_START) { ... }
if ($phase & PHP_OUTPUT_HANDLER_FLUSH) { ... }
elseif ($phase & PHP_OUTPUT_HANDLER_CLEAN) { ... }
if ($phase & PHP_OUTPUT_HANDLER_FINAL) { ... }
Fáze PHP_OUTPUT_HANDLER_WRITE nastává jen tehdy, pokud má
buffer velikost (chunk size) a ta byla překročena. Jedná se tedy
o zmíněný automatický flush. Jen pozor, konstanta
PHP_OUTPUT_HANDLER_WRITE má hodnotu 0, proto nelze použít
bitový test, ale:
if ($phase === PHP_OUTPUT_HANDLER_WRITE) { .... }
Handler nemusí podporovat všechny operace. Při aktivaci funkcí
ob_start() lze jako třetí parametr uvést bitovou masku
podporovaných operací:
PHP_OUTPUT_HANDLER_CLEANABLE – lze volat funkce
ob_clean() a související
PHP_OUTPUT_HANDLER_FLUSHABLE – lze volat funkci
ob_flush()
PHP_OUTPUT_HANDLER_REMOVABLE – buffer lze ukončit
PHP_OUTPUT_HANDLER_STDFLAGS – je kombinací všech tří
flagů, výchozí chování
Tohle se týká i bufferingu bez vlastního handleru. Například pokud chci
zachytávat výstupu do proměnné, nenastavím flag
PHP_OUTPUT_HANDLER_FLUSHABLE a buffer tak nebude možné (třeba
omylem) poslat na výstup funkcí ob_flush(). Nicméně lze tak
učinit pomocí ob_end_flush() nebo ob_get_flush(),
takže to poněkud ztrácí smysl.
Obdobně by měla absence flagu PHP_OUTPUT_HANDLER_CLEANABLE
zamezit mazání bufferu, ale opět to nefunguje.
A nakonec absence PHP_OUTPUT_HANDLER_REMOVABLE činní buffer
uživatelsky neodstranitelný, vypne se až při ukončení skriptu. Příkladem
handleru, který je vhodné takto nastavit, je ob_gzhandler,
který komprimuje výstup a tedy snižuje objem a zvyšuje rychlost datového
přenosu. Jakmile se tento buffer otevře, odešle HTTP hlavičku
Content-Encoding: gzip a veškerý další výstup musí být
komprimovaný. Odstranění bufferu by rozbilo stránku.
Správné použití je tedy:
ob_start(
'ob_gzhandler',
16000, // bez chunk size by server data neodesílal průběžně
PHP_OUTPUT_HANDLER_FLUSHABLE // ale ne removable nebo cleanable
);
Komprimaci výstupu můžete aktivovat také direktivou zlib.output_compression,
která zapne buffering s jiným handlerem (netuším, v čem konkrétně se
liší), bohužel chybí příznak, že má být neodstranitelný. Protože je
vhodné komprimovat přenos všech textových souborů, nejen v PHP
generovaných stánek, je lepší kompresi aktivovat přímo na straně HTTP
serveru.
Chrome 44 (beta) odesílá nově hlavičku HTTPS: 1,
která může způsobovat problémy.
Na některých hostinzích (z těch co používám třeba
WebSupport už to opravili) si pak PHP myslí, že požadavek je pod
šifrovaným spojením HTTPS. Tj. proměnná
$_SERVER['HTTPS'] === 'on'.
U aplikací v Nette, které neběží pod https, to pak způsobí
nekonečný redirect. Aplikace si prostě myslí, že k ní přistupujete přes
URL https://example.com a přesměrovává na
http://example.com.
Můžete to vyzkoušet z příkazové řádky pomocí:
curl -I --header "HTTPS: 1" http://example.com`
Že je hlavička HTTPS: 1 problematická se
už ví, takže je možné, že se změní a do Chrome nedostane.
Každopádně jako rychlý workaround, aby nedocházelo ke smyčce
přesměrování v betaverzi Chrome, je přidat na začátek bootstrap.php:
unset($_SERVER['HTTPS']);
Zároveň je dobré si uvědomit, že na některých hostinzích lze detekci
šifrovaného spojení velmi snadno ošálit.
Doplnění: Chrome 45 už hlavičku HTTPS: 1 neodesílá.
Nástroj zamění syntax ve všech souborech *.php a
*.phpt v aktuálním adresáři a také ve všech
podadresářích. Změněné soubory jsem pak komitnul (příklad).
Oříšek je ale rebasování dalších větví na takto změněný
master.
Nakonec jsem na to šel přes filtry. Ale
plně zautomatizovat se mi to nepovedlo.
Nejprve je vhodné všechny větve rebasovat na master těsně před samotnou
změnou syntaxe.
Poté jsem si vytvořil filtr nazvaný phparray, který bude
on-the-fly překládat v PHP souborech [] na array()
při checkoutu a obráceně při komitování. Tedy aby slučování probíhalo
při použití staré syntaxe, ale komitnulo se s novou.
Filtr se vytvoří v souboru .git/config, v mém případě to
vypadalo takto:
Aby se filtr při slučování používal (ale i při každém checkoutu,
cherry-picku atd), je nutné doplnit do .git/config ještě
následující:
[merge]
renormalize = true
Filtr se bude aplikovat na soubory *.php a *.phpt,
což se definuje v souboru .git/info/attributes (nepoužívejte
.gitattributes, protože jde o dočasnou záležitost a nechceme
ji komitovat):
*.php filter=phparray
*.phpt filter=phparray
Teď by ve větvi mělo fungovat git rebase master. Bez
konfliktů, které by bylo nutné ručně řešit. Jenže ouha, konflikty se mi
vytvářely (na Windows; je možné, že na Linuxu to půjde) a když jsem je
chtěl řešit v TortoiseGit, objevovala se hláška, že na souboru
.git/index.lock je zámek atd. Zkoušel jsem experimentovat
s dalšími nastaveními pro merge, ale bez výsledku.
Zkusil jsem dělat rebase ručně: což znamená nejprve větev resetnout na
master (git reset master --hard) a pak jednotlivé komity
přidávat pomocí git cherry-pick <hash>. Nedělal jsem to
z příkazové řádky, ale pomocí TortoiseGit. I nadále mi hlásil, že
některé soubory neumí automaticky sloučit a je vyžadován ruční zásah,
ale vždy stačilo soubor rozkliknout do TortoiseGitMerge a rovnou stisknout
Mark as resolved.
Bylo to otravné, ale fungovalo to a postupně jsem „rebasoval“ všechny
větve. Poté jsem filtr z .git/config a
.git/info/attributes smazal.
Proč to nešlo úplně automaticky, nemám páru, nicméně bylo snazší
hodinu klikat, než dva dny studovat Git.
Composer, nejdůležitější nástroj
pro PHP vývojáře, umožňuje 3 způsoby, jak instalovat balíčky:
lokální composer require vendor/name
globální composer global require vendor/name
jako projekt composer create-project vendor/name
Lokálně
Lokální instalace se používá nejčastěji. Mám projekt, ve kterém chci
třeba použít Tracy, tak v kořenovém
adresáři projektu zadám:
composer require tracy/tracy
a Composer zaktualizuje (nebo vytvoří) soubor composer.json a
stáhne Tracy do podsložky vendor. Zároveň vygeneruje
autoloader, takže v kódu jej stačí inkludovat a můžu rovnou Tracy
použít:
Diametrálně odlišná situace nastává tehdy, pokud místo knihovny,
jejíž třídy ve svém projektu používám, instaluji nástroj, který
jen spouštím z příkazové řádky.
Příkladem může být třeba ApiGen pro
generování přehledných API dokumentací. V takovém případě se použije
třetí způsob:
composer create-project apigen/apigen
Composer vytvoří novou složku (a tedy i nový projekt)
apigen a do ní stáhne celý nástroj a nainstaluje jeho
závislosti.
Bude mít vlastní composer.json a vlastní podsložku
vendor.
Tímto způsobem se instaluje i třeba Nette Sandbox nebo CodeChecker. Nikoliv však
testovací nástroje jako je Nette Tester
nebo PHPUnit, protože jejich třídy naopak
v testech používáme, voláme Tester\Assert::same() nebo
dědíme od PHPUnit_Framework_TestCase.
Bohužel Composer umožňuje instalovat nástroje jako je ApiGen i pomocí
composer require a nevypíše ani žádné varování.
Což je totéž, jako když donutíte dva vývojáře, kteří se ani
neznají a kteří pracují na úplně jiném projektu, aby sdíleli společnou
složku vendor. Na to se dá říci:
Proboha proč by to měli dělat?
Vždyť to přece nemůže fungovat!
Ano, není žádný rozumný důvod to dělat, nic to nepřinese, naopak to
přestane fungovat v momentě, kdy dojde ke kolizi používaných knihoven. Je
to jen otázka času, stavění domečku z karet, který se dřív nebo
později sesype. Jeden projekt bude vyžadovat knihovnu XY ve verzi 1.0, druhý
ve verzi 2.0 a v tu chvíli to přestane fungovat.
Globálně
Rozdíl mezi variantou 1) a 2), tj. mezi composer require a
composer global require, je pak v tom, že nepůjde o dva cizí
vývojáře, ale o deset cizích vývojářů a deset nesouvisejících
projektů. Tedy je to nesmysl na druhou.
Totiž composer global je špatné řešení úplně vždy,
neexistuje use case, kdy by bylo vhodné jej použít. Výhodou je jen to, že
když si globální adresář vendor/bin přidáte do PATH,
můžete snadno spouštět takto nainstalované knihovny.
Rekapitulace
composer require vendor/name pokud chcete používat třídy
knihovny
composer global require vendor/name nikdy!
composer create-project vendor/name pro nástroje volané jen
z příkazové řádky
Poznámka: npm používá odlišnou
filosofii danou možnostmi JavaScriptu a každou knihovnu instaluje jako
„samostatný projekt“, s vlastním adresářem vendor (resp.
node_modules). Ke konfliktu verzí tak dojít nemůže.
V případě npm naopak platí, že globální instalace
nástrojů, jako je například LESS CSS, jsou
velmi užitečná a příjemná věc.
Do žebříčku 5 největších zrůdností jazyka PHP
rozhodně patří nemožnost zjistit, zda volání nativní funkce skončilo
úspěchem, nebo chybou. Ano, čtete správně. Zavoláte funkci a nevíte, zda
došlo k chybě a k jaké.
Teď si možná klepete na čelo a říkáte: selhání přece poznám podle
návratové hodnoty, ne? Hmmm…
Návratová hodnota
Nativní (nebo interní) funkce obvykle vracejí v případě neúspěchu
false. Jsou tu výjimky, například json_decode,
která vrací null, pokud je vstup nevalidní nebo překročí
limit zanoření. Což najdeme v dokumentaci, potud ok.
Tato funkce slouží k dekódování JSONu i jeho hodnot, tedy volání
json_decode('null') také vrátí null, tentokrát ale
jako korektní výsledek. Musíme tedy rozlišovat null jakožto
správný výsledek a null jakožto chybu:
$res = json_decode($s);
if ($res === null && $s !== 'null') {
// došlo k chybě
}
Je to hloupé, ale pámbů zaplať, že to vůbec lze. Existují totiž
funkce, u kterých nelze z návratové hodnoty poznat, že k chybě došlo.
Např. preg_grep nebo preg_split vrací částečný
výsledek, tedy pole, a nepoznáte vůbec nic (více v Zrádné regulární výrazy).
json_last_error & spol.
Funkce informující o poslední chybě v určitém rozšíření PHP.
Bohužel bývají mnohdy nespolehlivé a je obtížné zjistit, co to vlastně
ta poslední chyba je.
Například json_decode('') neresetuje příznak poslední
chyby, takže json_last_error vrací výsledek nikoliv pro
poslední, ale pro nějaké předchozí volání json_decode (viz
How to encode and decode JSON
in PHP?). Obdobně ani preg_match('neplatývýraz', $s)
neresetuje preg_last_error. Pro některé chyby nemají tyto funkce
kód, takže je vůbec nevrací, atd.
error_get_last
Obecná funkce vracející poslední chybu. Bohužel je nesmírně
komplikované zjistit, zda se chyba týkala vámi volané funkce. Onu poslední
chybu totiž mohla vygenerovat úplně jiná funkce.
První možností je přihlížet ke error_get_last() jen ve
chvíli, kdy návratová hodnota značí chybu. Bohužel třeba funkce
mail() umí vygenerovat chybu, i když vrátí true.
Nebo naopak preg_replace v případě neúspěchu nemusí chybu
generovat vůbec.
Druhou možností je před voláním naší funkce „poslední chybu“
vyresetovat:
@trigger_error('', E_USER_NOTICE); // reset
$file = fopen($path, 'r');
if (error_get_last()['message']) {
// došlo k chybě
}
Kód je zdánlivě jasný, chyba může vzniknout pouze při volání funkce
fopen(). Ale není tomu tak. Pokud je $path objekt,
bude převeden na řetězec metodou __toString. Pokud je to jeho
poslední výskyt, bude volán i destruktor. Mohou se volat funkce URL
wrapperu. Atd.
Tedy i zdánlivě nevinný řádek může vykonat spoustu PHP kódu, který
může generovat jiné chyby, z nichž poslední pak vrátí
error_get_last().
Musíme se proto ujistit, že k chybě došlo skutečně při volání
fopen:
@trigger_error('', E_USER_NOTICE); // reset
$file = fopen($path, 'r');
$error = error_get_last();
if ($error['message'] && $error['file'] === __FILE__ && $error['line'] === __LINE__ - 3) {
// došlo k chybě
}
Ona magická konstanta 3 je počet řádků mezi
__LINE__ a voláním fopen. Prosím bez
komentáře.
Tímto způsobem už chybu odhalíme (tedy pokud ji funkce emituje, což
třeba zmíněné funkce pro práci s regulárními výrazy zpravidla
nedělají), ale nejsme schopni ji potlačit, tedy zabránit tomu, aby se
zalogovala apod. Použití například shut-up operátoru @ je
problematické v tom, že zatají vše, tedy veškerý další PHP kód, který
se v souvislosti s naší funkcí volá (viz zmíněné destruktory,
wrappery atd.).
Vlastní error handler
Šíleným, ale zřejmě jediným možným způsobem, jak zjistit, zda
určitá funkce vyhodila chybu s možností ji potlačit, je instalace
vlastního chybového handleru pomocí set_error_handler. Jenže
není sranda to udělat správně:
vlastní handler musíme také odstranit
musíme jej odstranit i v případě, že se vyhodí výjimka
musíme zachytávat skutečně jen chyby vzniklé
v inkriminované funkci
a všechny ostatní předat původnímu handleru
Výsledek vypadá takto:
$prev = set_error_handler(function($severity, $message, $file, $line) use (& $prev) {
if ($file === __FILE__ && $line === __LINE__ + 9) { // magická konstanta
throw new Exception($message);
} elseif ($prev) { // volej předchozí uživatelský handler
return $prev(...func_get_args());
}
return false; // volej systémový handler
});
try {
$file = fopen($path, 'r'); // o tuhle funkci nám jde
} finally {
restore_error_handler();
}
Dobře udržovaný software má mít kvalitní API dokumentaci.
Jistě. Ovšem stejným prohřeškem, jakým je absence dokumentace, je i její
přebytečnost. U psaní dokumentačních komentářů je totiž potřeba,
podobně jako u návrhu API nebo uživatelského rozhraní, přemýšlet.
Přičemž přemýšlením bych nenazýval proces, který se udál v hlavě
vývojáře, když doplnil konstruktor tímto komentářem:
class ChildrenIterator
{
/**
* Constructor.
*
* @param array $data
* @return \Zend\Ldap\Node\ChildrenIterator
*/
public function __construct(array $data)
{
$this->data = $data;
}
Šest řádků, které nepřidaly ani jednu jedinou informaci. Místo
toho roste
vizuální šum
duplicita informací
objem kódu
možnost chybovosti
Nesmyslnost uvedeného komentáře vám možná připadá evidentní, pak
jsem rád. Občas totiž dostávám pull requesty, které se snaží podobné
smetí do kódu propašovat. Někteří programátoři dokonce používají
editory, které takto znečišťují kód automaticky. Au.
Nebo jiný příklad. Zkuste se zamyslet, zda vám komentář prozradil
něco, co by bez něj nebylo zřejmé:
class Zend_Mail_Transport_Smtp extends Zend_Mail_Transport_Abstract
{
/**
* EOL character string used by transport
* @var string
* @access public
*/
public $EOL = "\n";
S výjimkou anotace @return lze pochybovat o přínosnosti
i v tomto případě:
class Form
{
/**
* Adds group to the form.
* @param string $caption optional caption
* @param bool $setAsCurrent set this group as current
* @return ControlGroup
*/
public function addGroup($caption = null, $setAsCurrent = true)
Pokud používáte výmluvné názvy metod a parametrů (což byste měli),
pokud ty ještě navíc mají výchozí hodnoty nebo typehinty, nedá vám tento
komentář takřka nic. Buď bych ho zredukoval o informační duplicity, nebo
naopak rozšířil.
Ale pozor na opačný extrém, jakým jsou romány v phpDoc:
/**
* Performs operations on ACL rules
*
* The $operation parameter may be either OP_ADD or OP_REMOVE, depending on whether the
* user wants to add or remove a rule, respectively:
*
* OP_ADD specifics:
*
* A rule is added that would allow one or more Roles access to [certain $privileges
* upon] the specified Resource(s).
*
* OP_REMOVE specifics:
*
* The rule is removed only in the context of the given Roles, Resources, and privileges.
* Existing rules to which the remove operation does not apply would remain in the
* ACL.
*
* The $type parameter may be either TYPE_ALLOW or TYPE_DENY, depending on whether the
* rule is intended to allow or deny permission, respectively.
*
* The $roles and $resources parameters may be references to, or the string identifiers for,
* existing Resources/Roles, or they may be passed as arrays of these - mixing string identifiers
* and objects is ok - to indicate the Resources and Roles to which the rule applies. If either
* $roles or $resources is null, then the rule applies to all Roles or all Resources, respectively.
* Both may be null in order to work with the default rule of the ACL.
*
* The $privileges parameter may be used to further specify that the rule applies only
* to certain privileges upon the Resource(s) in question. This may be specified to be a single
* privilege with a string, and multiple privileges may be specified as an array of strings.
*
* If $assert is provided, then its assert() method must return true in order for
* the rule to apply. If $assert is provided with $roles, $resources, and $privileges all
* equal to null, then a rule having a type of:
*
* TYPE_ALLOW will imply a type of TYPE_DENY, and
*
* TYPE_DENY will imply a type of TYPE_ALLOW
*
* when the rule's assertion fails. This is because the ACL needs to provide expected
* behavior when an assertion upon the default ACL rule fails.
*
* @param string $operation
* @param string $type
* @param Zend_Acl_Role_Interface|string|array $roles
* @param Zend_Acl_Resource_Interface|string|array $resources
* @param string|array $privileges
* @param Zend_Acl_Assert_Interface $assert
* @throws Zend_Acl_Exception
* @uses Zend_Acl_Role_Registry::get()
* @uses Zend_Acl::get()
* @return Zend_Acl Provides a fluent interface
*/
public function setRule($operation, $type, $roles = null, $resources = null, $privileges = null,
Zend_Acl_Assert_Interface $assert = null)
Vygenerovaná API dokumentace je pouhá referenční příručka, nikoliv
kniha, kterou by si člověk četl před spaním. Litanie sem skutečně
nepatří.
Asi nejoblíbenějším místem, kde se lze dokumentačně vyřádit, jsou
hlavičky souborů:
<?php
/**
* Zend Framework
*
* LICENSE
*
* This source file is subject to the new BSD license that is bundled
* with this package in the file LICENSE.txt.
* It is also available through the world-wide-web at this URL:
* http://framework.zend.com/license/new-bsd
* If you did not receive a copy of the license and are unable to
* obtain it through the world-wide-web, please send an email
* to license@zend.com so we can send you a copy immediately.
*
* @category Zend
* @package Zend_Db
* @subpackage Adapter
* @copyright Copyright (c) 2005-2012 Zend Technologies USA Inc. (http://www.zend.com)
* @license http://framework.zend.com/license/new-bsd New BSD License
* @version $Id: Abstract.php 25229 2013-01-18 08:17:21Z frosch $
*/
Kolikrát se zdá, že záměrem je hlavičku natáhnout tak, aby po
otevření souboru vůbec nebyl vidět kód. K čemu je 10řádková informace
o licenci New BSD, obsahující klíčové zvěsti, jako že její znění
najdete v souboru LICENSE.txt, že je dostupná přes
world-wide-web a pokud náhodou nedisponujete moderními výstřelky, jako je
tzv. webový prohlížeč, máte odeslat email na license@zend.com a oni vám
ji okamžitě pošlou? Navíc v balíku zopakovaná 4400×. Schválně jsem
žádost zkusil poslat, ale odpověď nepřišla 🙂
Též uvedení letopočtu v copyrightu vede k vášni dělat komity jako
update copyright year to 2014, které změní všechny soubory, což
komplikuje porovnávání verzí.
Je vůbec potřeba uvádět v každém souboru copyright? Z právního
hlediska to potřeba není, nicméně pokud open source licence dovolují
uživatelům používat části kódu s tím, že musí zachovat copyrighty, je
vhodné je tam mít. Stejně tak je užitečné v každém souboru uvádět,
z jakého produktu pochází, pomůže to lidem v orientaci, když na něj
jednotlivě narazí. Dobrým příkladem je třeba:
/**
* Zend Framework (http://framework.zend.com/)
*
* @link http://github.com/zendframework/zf2 for the canonical source repository
* @copyright Copyright (c) 2005-2014 Zend Technologies USA Inc. (http://www.zend.com)
* @license http://framework.zend.com/license/new-bsd New BSD License
*/
Přemýšlejte proto prosím nad každým řádkem, jestli skutečně má pro
uživatele přínos. Pokud ne, jde o smetí, které nemá v kódu
co dělat.
(Prosím případné komentátory, aby článek nevnímali jako souboj
frameworků, tím rozhodně není.)