Content Security Policy (CSP) je dodatečný bezpečnostní prvek, který
prohlížeči říká, jaké další zdroje může stránka načítat a jak
může být zobrazena. Chrání tak před vkládáním škodlivého kódu a
útokům jako je XSS. Odesílá se v podobě hlavičky sestavené z řady direktiv.
Jeho nasazení ale není vůbec triviální.
Obvykle chceme používat JavaScriptové knihovny umístěné na různých
místech mimo náš server, například měřící kód Google Analytics,
reklamní systémy, captchy atd. A tady bohužel první verze CSP selhává.
Vyžaduje přesnou analýzu načítaného obsahu a nastavení správných
pravidel. Tedy vytvořit whitelist, výčet všech domén, což není snadné,
jelikož některé skripty dynamicky dotahují další skripty z jiných
domén, nebo jsou na jiné domény přesměrované atd. A i když si dáte
práci a seznam vytvoříte ručně, nikdy nevíte, co se může v budoucnu
změnit, takže musíte neustále sledovat, jestli je seznam stále aktuální a
opravovat ho. Analýza Google ukázala, že i to pečlivé ladění ve finále
vede k tomu, že povolíte tak široký přístup, že celý smysl CSP padá,
jen posíláte s každým požadavek mnohem větší hlavičky.
CSP level 2 už k problému přistupuje jinak, pomocí nonce, nicméně
teprve třetí verze řešení dotáhla do konce. Bohužel zatím (rok 2019)
nemá dostatečnou podporu u prohlížečů.
O tom, jak sestavit direktivy script-src a
style-src, aby správně fungovaly i ve starších
prohlížečích a přitom s tím bylo co nejméně práce, jsem sepsal podrobný
článek v partnerské sekci Nette. V zásadě výsledná podoba může
vypadat nějak takto:
Než nastavíte nová pravidla pro CSP, vyzkoušejte si je nejprve nanečisto
pomocí hlavičky Content-Security-Policy-Report-Only. Ta funguje
ve všech prohlížečích podporujících CSP. Při porušení pravidel
prohlížeč nezablokuje skript, ale jen pošle notifikaci na URL uvedené
v direktivě report-uri. K příjmu notifikací a jejich analýze
můžete použít třeba službu Report
URI.
Můžete zároveň používat obě hlavičky a v
Content-Security-Policy mít ověřené a aktivní pravidla a
zároveň v Content-Security-Policy-Report-Only si testovat jejich
úpravu. Samozřejmě i selhání ostrých pravidlech si můžete nechat
monitorovat.
Názvoslovný oříšek: jak souhrnně označovat třídy a rozhraní? Jak
třeba nazvat proměnnou, která může obsahovat jak název třídy, tak
rozhraní? Co zvolit místo $class?
Dá se tomu říkat type ($type), nicméně to je zase
příliš obecné, protože typem je i řetězec nebo pole. Z pohledu jazyka
jím může být i něco komplikovanějšího, třeba ?array.
Navíc je sporné, co je v případě objektu jeho typ: je jím název třídy,
nebo je to object?
Nicméně souhrnné označení pro třídy a rozhraní skutečně existuje:
je jím slovo třída.
Cože?
Z pohledu deklarace je interface hodně ořezaná třída. Může obsahovat
jen veřejné abstraktní metody. Což také implikuje nemožnost vytvářet
objekty. Rozhraní jsou tedy podmnožinou tříd. A pokud je něco
podmnožinou, tak to můžeme označovat názvem nadmnožiny. Člověk je savec,
stejně jako rozhraní je třída.
Nicméně je tady ještě pohled užití. Třída může dědit jen od
jedné třídy, ale může implementovat vícero rozhraní. Nicméně tohle je
omezení týkající se tříd, samotné rozhraní za to nemůže. Obdobně:
třída nemůže dědit od final třídy, ale přitom final třídu pořád
vnímáme jako třídu. A také pokud třída může implementovat víc
rozhraní (tj. tříd, viz 1.), stále je vnímejme jako třídy.
A co traity? Ty sem vůbec nepatří, z hlediska OOP jednoduše
neexistují.
Tedy problém se společným pojmenováním tříd a rozhraní je vyřešen.
Říkejme jim prostě třídy.
classes + interfaces = classes
No jo, ale vznikl tady problém nový. Jak říkat třídám, které nejsou
rozhraní? Tedy jejich doplňku. Tomu, co se ještě na začátku článku
nazývalo třídy. Nerozhraní? Nebo implementations? 🙂
To je ještě větší oříšek. To je pořádný ořech. Víte co, raději
zapomeňme na to, že rozhraní jsou také třídy, a tvařme se opět, že
každý OOP identifikátor je buď třída, nebo rozhraní. Bude to
snazší.
Stylish
je doplněk do Chrome, který umožňuje přidat webovým stránkám vlastní
CSS styly.
(Lze ho nainstalovat i do nové Opery, nejprve si přidejte Download
Chrome extension a pak už ho přímo nainstalujete z Chrome webstore.)
Stylish jsem si přidal kvůli GitHubu, který mě štve příliš širokými
tabulátory a hlavně nezalamováním řádků s textem, bez čehož se podobné commity
vůbec nedají číst.
Naučit se psát všemi deseti, zvládnou správné
prstoklady – to je nepochybně prima přednost. Ale mezi námi, sám datluji
celý život dvěma prsty a při psaní přikládám daleko větší důraz
něčemu jinému. A tím je rozložení klávesnice.
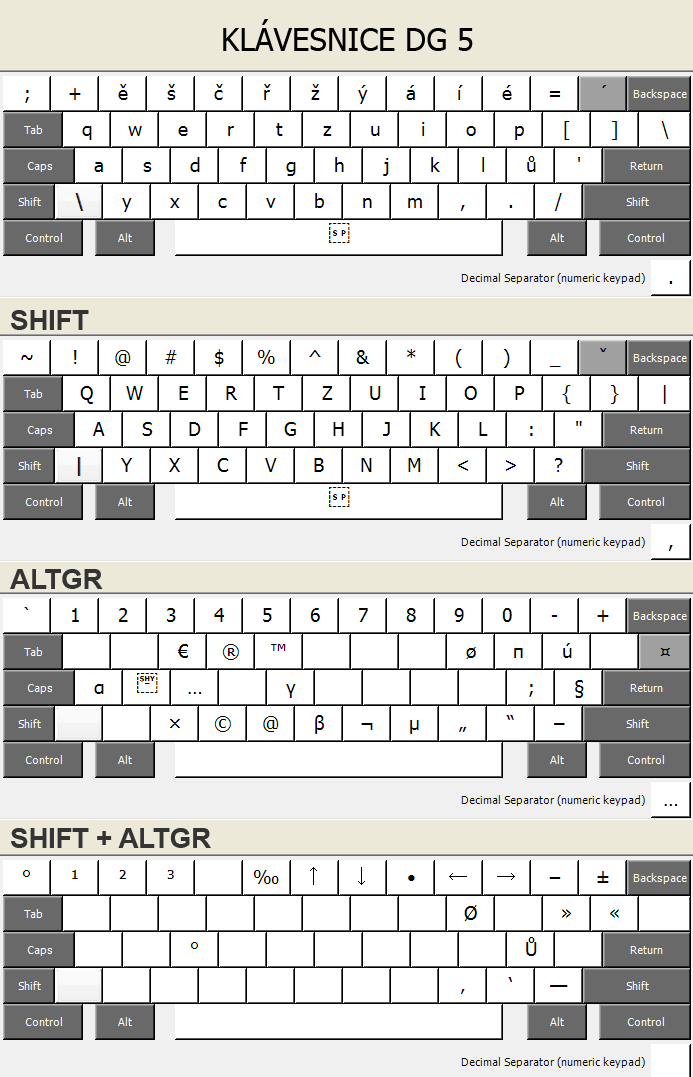
Řešením je si vytvořit vlastní rozložení klávesnice. To své jsem si
vypiplal asi před
deseti lety a je vhodné pro programátory, webdesignery, copywritery,
obsahuje všechny důležité typografické vychytávky, jako je pomlčka, dvojité a
jednoduché uvozovky atd., intuitivně umístěné. Rozložení si můžete
samozřejmě upravit, viz dále.
Všechny typografické znaky jsou dosažitelné přes pravý Alt, nebo-li
AltGr. Rozložení je intuitivní:
české dvojité uvozovky „“ AltGr-<AltGr->
české jednoduché uvozovky ‚‘ AltGr-Shift-<AltGr-Shift->
Je to snadné a je to zábavné. Přímo od Microsoftu si stáhněte
kouzelný a dobře utajený program Microsoft Keyboard
Layout Creator (ke svému chodu vyžaduje .NET Framework).
Hned při spuštění se Vám zobrazí „prázdná“ klávesnice, tedy
taková, kde ještě není definováno žádné rozložení kláves. Začínat
na zelené louce není to pravé ořechové, proto si najděte v menu příkaz
Load existing keyboard a načtěte některé standardní
rozložení (například klasickou českou klávesnici).
U každé klávesy můžete definovat znak, který se napíše při
samostatném stisku a dále při použití přepínačů (tedy Shift,
Ctrl+Alt (pravý Alt), pravý Alt +Shift,
Caps Lock a Shift+Caps Lock). Dále lze klávesu označit
jako mrtvou (dead key), což znamená, že znak se napíše až po stisknutí
další klávesy. Takto funguje například háček a čárka v české
klávesnici.
Skutečná bomba je export hotové klávesnice. Výsledkem je plnohodnotný
ovladač klávesnice včetně instalačního programu. Takže svou klávesnici
si můžete pověsit na internet a nainstalovat na jiné počítače.
Tuhle jsem zveřejnil skript na cherry-pickování přímo
z GitHubu, který dodnes používám, ale bylo otravné tím stahovat celé
pull requesty, pokud obsahovaly víc komitů. Takže jsem ho naučil stahovat je
na jeden zátah. Opět stačí jako argument uvést URL:
Pull request se stáhne do nové větve s názvem jako
pull-123.
Mám i skript na vytvoření nového pull requestu. Spustíte jej ve větvi,
ze které chcete PR vytvořit, bez parametrů. On větev pushne do vašeho forku
a poté otevře prohlížeč s formulářem pro vytvoření pull requestu:
<?php
$remote = 'dg'; // tady dejte název 'remote' vedoucí k forku na GitHubu
exec('git remote -v', $remotes);
$repo = null;
foreach ($remotes as $rem) {
if (preg_match('#^' . preg_quote($remote) . '\tgit@github.com:(.+)\.git \(#', $rem, $m)) {
$repo = $m[1];
break;
}
}
if (!$repo) {
die('Not Github repo');
}
exec('git rev-parse --abbrev-ref HEAD', $branch);
$branch = $branch[0];
if (!$branch) {
die('Unable to retrieve branch name');
}
echo "Pushing to $repo & $branch\n";
exec("git push --set-upstream $remote $branch");
$url = "https://github.com/$repo/compare/$branch?expand=1";
exec('start "" ' . $url); // tohle otevře prohlížeč pod Windows. Pro jiné OS si upravte.
Už jsem odpověděl na spoustu pull requestů „Can you add
tests?“ Ale ne proto, že bych byl testofil, nebo abych dotyčného
buze prudil.
Pokud posíláte pull request, který opravuje nějakou chybu, tak
pochopitelně musíte před odesláním vyzkoušet, jestli skutečně funguje.
Kolikrát si člověk myslí, že něco snadno fixne a ejhle, rozbije to ještě
víc. Nechci se opakovat, ale tím, že to vyzkoušíte, jste vyrobili test, tak ho jen
přiložte.
(Bohužel někteří lidé svůj kód doopravdy nevyzkouší. Kdyby to šlo,
dával bych měsíční bany za pull requesty vytvořené přímo ve webovém
editoru Githubu.)
Ale to stále není ten nejhlavnější důvod: Test je jediná záruka,
že vaše oprava bude fungovat v budoucnu.
Už mnohokrát se stalo, že někdo poslal pull request, který mi nebyl
užitečný, ale upravoval funkcionalitu důležitou pro něj. Zejména pokud to
byl někdo, koho znám, a vím, že je dobrý programátor, tak jsem to mergnul.
Pochopil jsem, k čemu to chce, nevadilo to ničemu jinému, tak jsem PR
přijal a v tu chvíli vypustil z hlavy.
Pokud svůj pull request doplnil testem, tak jeho kód dodnes funguje a bude
fungovat i nadále.
Pokud ho testem nedoplnil, tak se klidně může stát, že mu to nějaká
další úprava rozbije. Ne schválně, prostě se to stane. Nebo už se to
stalo. A nemá smysl láteřit, jaký jsem vůl, že jsem mu už potřetí
rozbil jeho kód, ačkoliv jsem před 3 lety přijal jeho pull request, si to
snad musím pamatovat né, takže mu to snad dělám naschvál… Nedělám.
Nikdo si nepamatujeme, co jsme měli před třemi lety na svačinu.
Pokud vám na nějaké funkcionalitě záleží, přiložte k ní test.
Pokud vám na ni nezáleží, vůbec ji neposílejte.
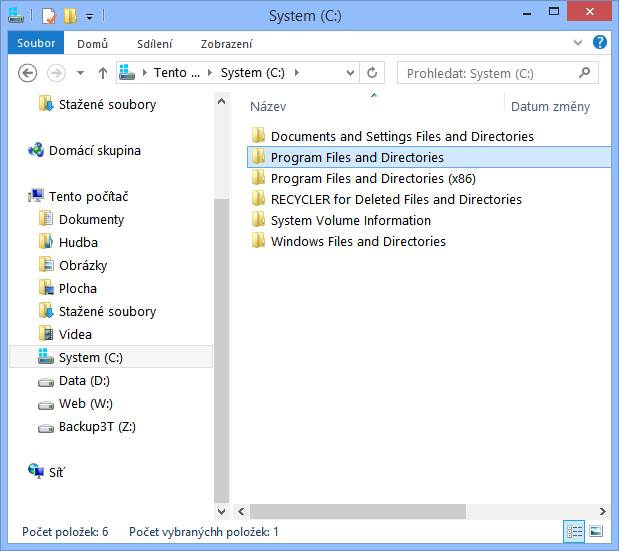
Vždycky jsem obdivoval Microsoft, jak dokáže perfektně pojmenovávat
systémové adresáře, třeba takové c:\Documents and Settings namísto
trapného /home nebo /Users, nicméně vždycky mě trápila složka Program
Files, protože na jedné straně je skvělé, že v názvu uvádí, že
uvnitř jsou soubory (což třeba mekaře u takové /Applications vůbec
nemusí napadnout), na druhou stranu úplně opomíjí adresáře.
Navrhuji proto každou složku, která může obsahovat soubory nebo
adresáře, tedy každou složku, doplnit v názvu touto informací. Tedy
v příštích Windows přejmenovat c:\Program Files na přesnější
c:\Program Files and Directories.
To by mohlo zase více posunout Microsoft tam, kde v poslední
době je.
Václav Novotný připravil infografiku porovnávající
aktivitu vývojářů v Nette a Symfony. Rád a zvědavě se podívám, leč
bez vysvětlení metriky umí být čísla krutě zrádná. S nadsázkou: při
určitém workflow a naivním měření mohu ve statistikách vyjít jako autor
100 % kódu, aniž bych naprogramoval jedinou řádku.
I při přímočarých workflow je poměřování množství komitů
zákeřné. Není komit jako komit. Pokud přidáte pětici důležitých
komitů a zároveň deset lidí vám opraví překlepy v komentářích, jste
co do počtu komitů autorem třetiny kódu. Což ale není pravda, jste autorem
celého kódu, opravy překlepů se za autorství (jak ho obvykle vnímáme)
nepovažují.
V GITu dále věc komplikují „merge-commits“. Pokud někdo připraví
zajímavý komit a vy ho schválíte (tedy vznikne ještě merge-commit), jste
autorem poloviny komitů. Ale jaký je vlastně skutečný podíl? Obvykle
nulový, schválení je otázka jednoho kliknutí v GitHubu, byť někdy
diskusí strávíte víc času, než kdybyste si kód napsal sám, ale
neuděláte to, protože potřebujete vývojáře vychovávat.
Proto místo počtu komitů je vhodnější analyzovat jejich obsah.
Nejjednodušší je brát v úvahu počet změněných řádek. Ale i to
může být zavádějící: pokud vytvoříte 100 řádkovou třídu a někdo
jiný soubor s ní jen přejmenuje (či rozdělí na dva), „změnil“
vlastně 200 řádků a opět jste autorem třetiny.
Pokud týden ladíte u sebe několik komitů a až potom je pošlete do
repozitáře, jste v počtu změněných řádek v nevýhodě oproti tomu, kdo
je pošle hned a teprve poté dolaďuje následujícími komity. Nebylo by tedy
od věci analyzovat třeba až souhrny za celý den. Je třeba odfiltrovat
i údržbové komity, zejména ty, které mění u všech souborů letopočet
nebo verzi v hlavičce.
Do toho přicházejí ještě situace, kdy se automatizovaně kopírují
komity z jedné větve do jiné, nebo do jiného repozitáře. Což de facto
znemožňuje dělat jakékoliv globální statistiky.
Analýza jednoho projektu je věda, natož ta srovnávací. Docela mi to
připomíná skvělý analytický kvíz od Honzy
Tichého.
Není nic horšího, než uploadovat soubory na FTP ručně,
například pomocí Total Commanderu. (Ačkoliv, ještě horší je editovat
soubory přímo na serveru a pak se zoufale pokoušet o jakousi synchronizaci.)
Jakmile totiž proces nezautomatizujete, stojí vás mnohem víc času a hrozí
riziko chyby. Třeba, že některý soubor zapomenete nahrát.
Dnes už se používají sofistikované techniky nasazování aplikací na
web, například pomocí Gitu, ale mnoho lidí stále zůstává u nahrávání
jednotlivých souborů skrze FTP. Právě pro ně je určen nástroj FTP
Deployment, který zautomatizuje a zjednoduší nahrávání aplikací
přes FTP.
FTP Deployment je skript
napsaný v PHP, který celý proces zautomatizuje. Stačí jen říct, který
adresář (local) má kam nahrát (remote). Tyto
údaje zapíšete do souboru deployment.ini, jehož odkliknutí
můžete rovnou asociovat se spuštěním skriptu, takže deployment se stane
věcí jednoho kliknutí:
php deployment deployment.ini
A jak vypadá soubor deployment.ini? Povinná je vlastně jen
položka remote, všechny ostatní jsou nepovinné:
; remote FTP server
remote = ftp://user:secretpassword@ftp.example.com/directory
; you can use ftps:// or sftp:// protocols (sftp requires SSH2 extension)
; do not like to specify user & password in 'remote'? Use these options:
;user = ...
;password = ...
; FTP passive mode
passiveMode = yes
; local path (optional)
local = .
; run in test-mode? (can be enabled by option -t or --test too)
test = no
; files and directories to ignore
ignore = "
.git*
project.pp[jx]
/deployment.*
/log
temp/*
!temp/.htaccess
"
; is allowed to delete remote files? (defaults to yes)
allowDelete = yes
; jobs to run before uploading
before[] = local: lessc assets/combined.less assets/combined.css
before[] = http://example.com/deployment.php?before
; jobs to run after uploading and before uploaded files are renamed
afterUpload[] = http://example.com/deployment.php?afterUpload
; directories to purge after uploading
purge[] = temp/cache
; jobs to run after everything (upload, rename, delete, purge) is done
after[] = remote: unzip api.zip
after[] = remote: chmod 0777 temp/cache ; change permissions
after[] = http://example.com/deployment.php?after
; files to preprocess (defaults to *.js *.css)
preprocess = no
; file which contains hashes of all uploaded files (defaults to .htdeployment)
deploymentFile = .deployment
; default permissions for new files
;filePermissions = 0644
; default permissions for new directories
;dirPermissions = 0755
V testovacím režimu (při spuštění s parametrem -t)
k uploadu nebo mazání souborů na FTP nedochází, můžete jej tedy použít
k ověření, zda máte všechny hodnoty dobře nastavené.
Položka ignore používá stejný formát jako .gitignore:
log – ignoruje všechny soubory či adresáře
log, i uvnitř všech podsložek
/log – ignoruje soubor či adresář log
v kořenovém adresáři
app/log – ignoruje soubor či adresář log
v podsložce app kořenového adresáře
data/* – ignoruje vše uvnitř složky data,
ale samotnou služku na FTP vytvoří
!data/session – z předchozího pravidla učiní výjimku
pro soubor či složku session
project.pp[jx] – ignoruje soubory či složky
project.ppj a project.ppx
Před započetím uploadu a po jeho skončení můžete nechat zavolat
skripty na vašem serveru (viz before a after), které
mohou například server přepnout do maintenance režimu, kdy bude
odesílat hlavičku 503.
Aby synchronizace i velkého množství souborů proběhla (v rámci
možností) transakčně, všechny soubory se nejprve nahrají s příponou
.deploytmp a poté, což už je rychlé, přejmenují. Zároveň se
na server uloží soubor .htdeployment, kde jsou uloženy md5
otisky všech souborů a právě pomocí něj se nadále web synchronizuje.
Při dalším spuštění tedy nahrává pouze změněné soubory a maže
smazané (pokud to nezakážeme direktivou allowdelete).
Nahrávané soubory je možné nechat zpracovat preprocesorem. Standardně
jsou nastaveny pravidla, že všechny .css soubory se zkomprimují
pomocí Clean-CSS a .js pomocí Google Closure Compiler. Před
samotnou komprimací se ještě expandují základní mod_include
direktivy Apache. Můžete tedy vytvořit například soubor
combined.js:
Který vám bude Apache na lokálním serveru za běhu sestavovat spojením
tří uvedených souborů. Říci si o to můžete takto:
<FilesMatch "combined\.(js|css)$">
Options +Includes
SetOutputFilter INCLUDES
</FilesMatch>
Přičemž na server se nahraje už ve spojené a zkomprimované podobě.
Vaše HTML stránka tak bude šetřit zdroje a načítat jediný JavaScriptový
soubor.
V konfiguračním souboru deployment.ini můžete vytvořit
i více sekcí, případně si udělat jeden konfigurák zvlášť pro data a
jeden pro aplikaci, aby synchronizace byla co nejrychlejší a nemusel se vždy
počítat otisk velkého množství souborů.
Nástroj FTP Deployment jsem si vytvořil před mnoha lety a plně pokrývá
mé požadavky na deployovací nástroj. Zároveň je třeba zdůraznit, že FTP
protokol tím, že přenáší heslo v čitelné podobě, představuje
bezpečnostní riziko a rozhodně byste jej neměli používat třeba na
veřejných Wi-Fi.