A naming conundrum: how to collectively refer to classes and interfaces? For
instance, what should you call a variable that could contain either a class or
an interface name? What should be used instead of $class?
One might consider the term type ($type), but this is
quite generic because a type can also be a string or an array. From the
perspective of the language, a type could be something more complex, such as
?array. Moreover, it's debatable what constitutes the type of an
object: is it the class name, or is it object?
However, there indeed exists a collective term for classes and interfaces: it
is the word class.
How so?
From a declaration standpoint, an interface is essentially a stripped-down
class. It can only contain public abstract methods, which also implies that
objects cannot be created. Therefore, interfaces are a subset of classes. If
something is a subset, we can refer to it by the name of the superset. Just as a
human is a mammal, an interface is a class.
Nevertheless, there's also the usage perspective. A class can inherit from
only one class but can implement multiple interfaces. However, this limitation
pertains to classes, not to the interfaces themselves. Similarly, a class cannot
inherit from a final class, but we still perceive the final class as a class.
Also, if a class can implement multiple interfaces (i.e., classes, see 1.), we
still regard them as classes.
And what about traits? They simply do not belong here, as they do not exist
from an OOP standpoint.
Thus, the issue of naming classes and interfaces together is resolved.
Let’s simply call them classes.
classes + interfaces = classes
Well, but a new problem has arisen. How to refer to classes that are not
interfaces? That is, their complement. What was referred to at the beginning of
the article as classes. Non-interface? Or “implementations”#Class_vs._type)? 🙂
That's an even bigger nut to crack. It’s a tough nut indeed. You know
what, let's forget that interfaces are also classes and again pretend that
every OOP identifier is either a class or an interface. It will be easier.
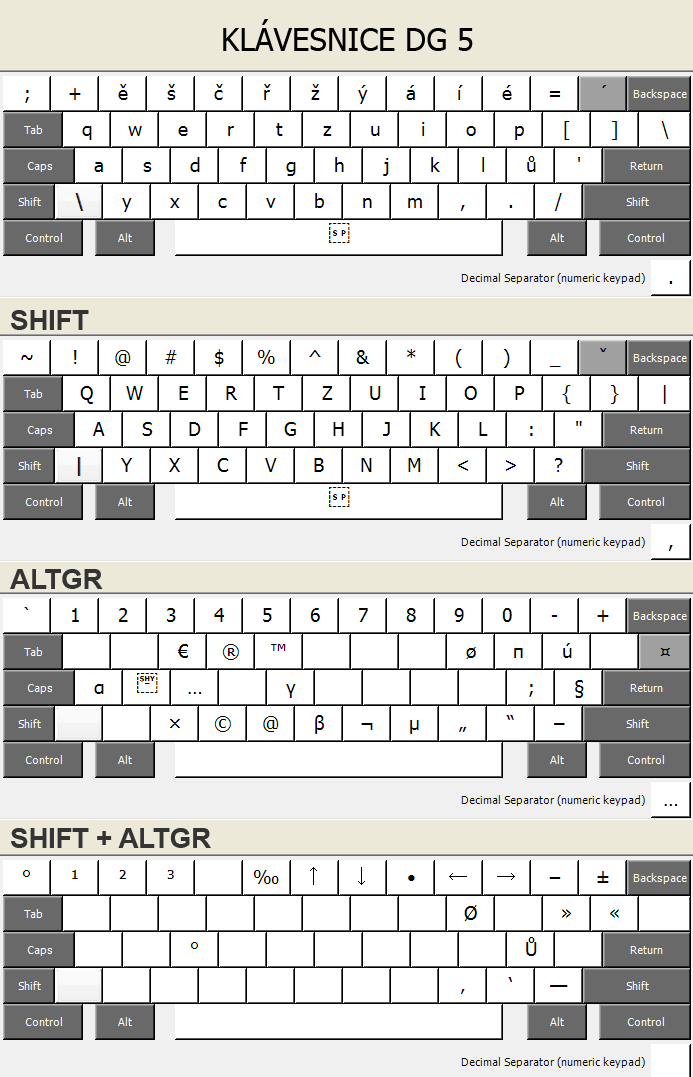
Learning to type using all ten fingers and mastering the
correct finger placement is undoubtedly a great skill. But between us, I've
spent my entire life “pecking” at the keyboard with two fingers, and when
typing, I place far greater importance on something else. And that is the
layout of the keyboard.
The solution is to create your own keyboard layout. I perfected mine about ten
years ago, and it's suitable for programmers, web designers, and
copywriters, containing all the essential typographic tricks like dash, double and single
quotation marks, etc., intuitively placed. Of course, you can customize the
layout further, as described below.
All typographic characters are accessible via the right Alt, or AltGr. The
layout is intuitive:
Czech double quotation marks „“ AltGr-<AltGr->
Czech single quotation marks ‚‘ AltGr-Shift-<AltGr-Shift->
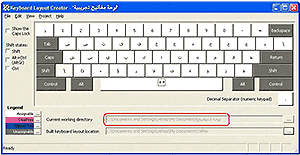
It's easy and fun. Directly from Microsoft, download the magical and
well-hidden program Microsoft Keyboard
Layout Creator (requires .NET Framework to run).
Upon launching, you'll see an “empty” keyboard, meaning no layout is
defined yet. Starting from scratch isn't ideal, so find the
Load existing keyboard command in the menu and load one of the
standard layouts (like the classic Czech keyboard).
For each key, you can define the character that is typed when the key is
pressed alone and also when combined with modifiers (i.e., Shift,
Ctrl+Alt (right Alt), right Alt +Shift,
Caps Lock, and Shift+Caps Lock). You can also designate a
key as a dead key, meaning the character is typed only after pressing another
key. This is how accents like háček and čárka function on the Czech
keyboard.
The real gem is exporting the finished keyboard layout. The result is a
full-fledged keyboard driver, including an installation program. So, you can
upload your keyboard to the internet and install it on other computers.
I've responded to many pull requests with “Can you add
tests?” Not because I'm a testophile, or to annoy the person involved.
When you send a pull request that fixes a bug, naturally, you must test it
before submitting to ensure it actually works. Often, one thinks something can
be easily fixed, but lo and behold, it ends up breaking even more. I don’t
want to repeat myself, but by testing it, you created a test, so just attach it.
(Unfortunately, some people really don’t test their code. If it were up to
me, I would give out monthly bans for pull requests made directly in the Github
web editor.)
But that's still not the main reason: A test is the only guarantee that
your fix will work in the future.
It has happened many times that someone sent a pull request that wasn’t
useful to me, but altered functionality important to them. Especially if it was
someone I know and I know they are a good programmer, I would merge it.
I understood what they wanted, it didn’t interfere with anything else, so
I accepted the PR and then I put it out of my mind.
If their pull request included a test, then their code still works today and
will continue to work.
If they didn’t add a test, it might easily happen that some other
modification will break it. Not intentionally, it just happens. Or it has
already happened. And there's no point in complaining about how stupid I am
because I broke their code for the third time, even though I accepted their
pull request three years ago—am I supposed to remember that? No, so perhaps
I’m doing it on purpose… I’m not. No one remembers what we had for lunch
three years ago.
If you care about a functionality, attach a test to it. If you don’t
care about it, don’t send it at all.
Václav Novotný has prepared an infographic comparing
developer activity in Nette and Symfony. I'm eager and curious to look at it,
but without an explanation of the metric, the numbers can be treacherously
misleading. Exaggerating a bit: with a certain workflow and naive measurement,
I could appear in the statistics as the author of 100% of the code without
having written a single line.
Even with straightforward workflows, comparing the amount of commits is
tricky. Not all commits are equal. If you add five important commits and at the
same time ten people correct typos in your comments, you are, in terms of the
number of commits, the author of one-third of the code. However, this isn't
true; you are the author of the entire code, as corrections of typos are not
usually considered authorship (as we typically perceive it).
In GIT, “merge-commits” further complicate matters. If someone prepares
an interesting commit and you approve it (thus creating a merge-commit), you are
credited with half of the commits. But what is the actual contribution? Usually
none, as approval is a matter of one click on GitHub, although sometimes you
might spend more time discussing it than if you had written the code yourself,
but you don't because you need to train developers.
Therefore, instead of the number of commits, it is more appropriate to
analyze their content. The simplest measure is to consider the number of changed
lines. But even this can be misleading: if you create a 100-line class and
someone else merely renames the file with it (or splits it into two), they have
“changed” effectively 200 lines, and again you are the author of
one-third.
If you spend a week debugging several commits locally before sending them to
the repository, you are at a disadvantage in the number of changed lines
compared to someone who sends theirs immediately and only then fine-tunes with
subsequent commits. Therefore, it might be wise to analyze, perhaps, summaries
for the entire day. It is also necessary to filter out maintenance commits,
especially those that change the year or version in the header of
all files.
Then there are situations where commits are automatically copied from one
branch to another, or to a different repository. This effectively makes it
impossible to conduct any global statistics.
Analyzing one project is science, let alone comparative analysis. This quite
reminds me of the excellent analytical quiz by
Honza Tichý.
There is nothing worse than manually uploading files via FTP,
for example, using Total Commander. (Although, editing files directly on the
server and then desperately trying to synchronize them is even worse.) Once you
fail to automate the process, it consumes much more of your time and increases
the risk of errors, such as forgetting to upload a file.
Today, sophisticated application deployment techniques are used, such as via
Git, but many people still stick to uploading individual files via FTP. For
them, the FTP Deployment tool is designed to automate and simplify the uploading
of applications over FTP.
FTP Deployment is a PHP
script that automates the entire process. You simply specify which directory
(local) to upload to (remote). These details are
written into a deployment.ini file, clicking which can immediately
launch the script, making deployment a one-click affair:
deployment deployment.ini
What does the deployment.ini file look like? The
remote item is actually the only required field; all others are
optional:
; remote FTP server
remote = ftp://user:secretpassword@ftp.example.com/directory
; you can use ftps:// or sftp:// protocols (sftp requires SSH2 extension)
; do not like to specify user & password in 'remote'? Use these options:
;user = ...
;password = ...
; FTP passive mode
passiveMode = yes
; local path (optional)
local = .
; run in test-mode? (can be enabled by option -t or --test too)
test = no
; files and directories to ignore
ignore = "
.git*
project.pp[jx]
/deployment.*
/log
temp/*
!temp/.htaccess
"
; is allowed to delete remote files? (defaults to yes)
allowDelete = yes
; jobs to run before uploading
before[] = local: lessc assets/combined.less assets/combined.css
before[] = http://example.com/deployment.php?before
; jobs to run after uploading and before uploaded files are renamed
afterUpload[] = http://example.com/deployment.php?afterUpload
; directories to purge after uploading
purge[] = temp/cache
; jobs to run after everything (upload, rename, delete, purge) is done
after[] = remote: unzip api.zip
after[] = remote: chmod 0777 temp/cache ; change permissions
after[] = http://example.com/deployment.php?after
; files to preprocess (defaults to *.js *.css)
preprocess = no
; file which contains hashes of all uploaded files (defaults to .htdeployment)
deploymentFile = .deployment
; default permissions for new files
;filePermissions = 0644
; default permissions for new directories
;dirPermissions = 0755
In test mode (when started with the -t parameter), no file
uploads or deletions occur on the FTP, so you can use it to check if all values
are correctly set.
The ignore item uses the same format as .gitignore:
log – ignores all log files or directories,
even within all subfolders
/log – ignores the log file or directory in the
root directory
app/log – ignores the log file or directory in
the app subfolder of the root directory
data/* – ignores everything inside the data
folder but still creates the folder on FTP
!data/session – excludes the session file or
folder from the previous rule
project.pp[jx] – ignores project.ppj and
project.ppx files or directories
Before starting the upload and after it finishes, you can have scripts called
on your server (see before and after), which can
switch the server into a maintenance mode, sending a 503 header, for
instance.
To ensure synchronization of a large number of files happens (as far as
possible) transactionally, all files are first uploaded with the
.deploytmp extension and then quickly renamed. Additionally, a
.htdeployment file is saved on the server containing MD5 hashes of
all files, and it's used for further web synchronization.
On subsequent runs, it uploads only changed files and deletes removed ones
(unless prevented by the allowdelete directive).
Files can be preprocessed before uploading. By default, all .css
files are compressed using Clean-CSS and .js files using Google
Closure Compiler. Before compression, they first expand basic mod_include
directives from Apache. For instance, you can create a
combined.js file:
You can request Apache on your local server to assemble this by combining the
three mentioned files as follows:
<FilesMatch "combined\.(js|css)$">
Options +Includes
SetOutputFilter INCLUDES
</FilesMatch>
The server will then upload the files in their combined and compressed form.
Your HTML page will save resources by loading just one JavaScript file.
In the deployment.ini configuration file, you can create
multiple sections, or even make one configuration file for data and another for
the application, to make synchronization as fast as possible and not always
calculate the fingerprint of a large number of files.
I created the FTP Deployment tool many years ago and it fully covers my
needs for a deployment tool. However, it's important to emphasize that the FTP
protocol, by transmitting the password in plain text, poses a security risk and
you definitely should not use it, for example, on public Wi-Fi.
Few are as keen to emphasize their perceived superiority as
Rails developers. Don't get me wrong, it's a solid marketing strategy.
What's problematic is when you succumb to it to the extent that you see the
rest of the world as mere copycats without a chance to ever catch up. But the
world isn't like that.
Take Dependency Injection, for example. While people in the PHP and
JavaScript communities discovered DI later, Ruby on Rails remains untouched by
it. I was puzzled why a framework with such a progressive image was lagging
behind, and after some digging, I found an answer from various sources on
Google and karmiq, which
states:
Ruby is such a good language that it doesn't need Dependency Injection.
This fascinating argument, moreover, is self-affirming in an elitist
environment. But is it really true? Or is it just blindness caused by pride, the
same blindness that recently led to much-discussed security vulnerabilities
in Rails?
I wondered if perhaps I knew so little about Ruby that I missed some key
aspect, and that it truly is a language that doesn’t need DI. However, the
primary purpose of Dependency
Injection is to clearly pass dependencies so that the code is
understandable and predictable (and thus better testable). But when I look
at the Rails documentation on the “blog in a few minutes” tutorial, I see
something like:
def index
@posts = Post.all
end
Here, to obtain blog posts, they use the static method Post.all,
which retrieves a list of articles from somewhere (!). From a database? From a
file? Conjured up? I don’t know because DI isn’t used here. Instead,
it’s some kind of static hell. Ruby is undoubtedly a clever language,
but it doesn’t replace DI.
In Ruby, you can override methods at runtime (Monkey patch; similar to
JavaScript), which is a form of Inversion of Control (IoC) that allows for
substituting a different implementation of the static method
Post.all for testing purposes. However, this does not replace DI,
and it certainly doesn't make the code clearer, rather the opposite.
Incidentally, I was also struck by the Post class in that it
represents both a single blog post and functions as a repository (the
all method), which violates the Single
Responsibility Principle to the letter.
The justification often cited for why Ruby doesn't need DI refers to the
article LEGOs,
Play-Doh, and Programming. I read it thoroughly, noting how the author
occasionally confuses “DI” with a “DI framework” (akin to confusing
“Ruby” with “Ruby on Rails”) and ultimately found that it doesn’t
conclude that Ruby doesn’t need Dependency Injection. It says that it
doesn’t need DI frameworks like those known from Java.
One misinterpreted conclusion, if flattering, can completely bewilder a huge
group of intelligent people. After all, the myth that spinach contains an
extraordinary amount of iron has been persistent since 1870.
Ruby is a very interesting language, and like in any other, it pays to use
DI. There are even DI frameworks available for it. Rails is an intriguing
framework that has yet to discover DI. When it does, it will be a major topic
for some of its future versions.
(After attempting to discuss DI with Karmiq, whom I consider the most
intelligent Railist, I am keeping the comments closed, apologies.)
If you think the function returns false because the regular
expression operates in single-line mode and does not allow any characters other
than digits in the string, you are mistaken.
I'll digress slightly. Regular expressions in Ruby have a flaw (inconsistency
with the de facto PERL standard): the ^ and $
characters do not denote the start and end of the string, but only the start and
end of a line within it. Not knowing this fact can cause security
vulnerabilities, as noted in the Rails
documentation. PHP behaves as standard, but few know what exactly that
standard behavior means. The documentation for the meta-character $
is imprecise.
(now corrected)
Correctly, the $ character means the end of the string or a
terminating newline; in multiline mode (modifier m), it means
the end of a line.
The actual end of the string is captured with the sequence \z.
Alternatively, you can use the dollar sign together with the modifier
D.
Large frameworks aren't always and universally suitable for
everyone and everything!
I borrowed the title from the Manifesto of
Miniature PHP, which I would happily sign electronically, if I had a
digital signature. Although the argument about counting lines is unfair and
debatable, I understand what the author was trying to say. On Zdroják,
I wrote a comment that I eventually decided to immortalize here on
the blog:
I often make simple websites, which I write entirely in “notepad”, and
I want the code to have no more lines than is absolutely necessary. Uploading a
several-megabyte framework for a 20kB website, including styles, to a hosting
service is out of the question.
Yet, even in these simple websites, I want to use solutions that are
available in Nette, and I don't want to give up the comfort I'm used to. I am
a lazy programmer. For this reason, the Nette
Framework can be used as a micro-framework.
An example would be appropriate. Just yesterday, I redesigned https://davidgrudl.com and made the source
code available (check the top left corner), purely for inspiration to others on
how I handle such a microsite. The entire PHP code of the website is contained
in a single file, index.php, which is, I believe, understandable, although
perhaps less so for the uninitiated. The rest are templates. And the framework
is uploaded in the minified form of a single file, which, along with the fact
that it's about twice the size of jQuery, overcomes the psychological block of
“not wanting to upload a whole framework.”
Or take the example of a blog found directly in the distribution. Its source
code is also just index.php, with even fewer lines than the previous example.
Everything else is templates, see https://github.com/…ta/templates.
Perhaps I should explain why I actually use a framework on tiny websites.
Mainly, today I cannot imagine programming without Tracy, which then logs errors on the
production server (although they are unlikely with a static website). But
I primarily use the Latte templating
system because, starting from just 2 pages, I want to separate layout and
content, I like Latte’s concise syntax, and I rely on its automatic
escaping. I also use routing, because simply
wanting URLs without .php extensions can only be set up correctly
by God himself.
In the first mentioned website, caching is also used for Twitter
feeds, and on the blog, a database
layer is utilized. And there’s also a Nette SEO trick, which
automatically prevents the known error of moving forwards and backwards through
pagination and landing on the same page, only to have it haunted in the URL by
page=1.
Nette also ensures that if there is an error, no PHP programming error
messages are displayed, but rather a user-understandable page. And also
autoloading – I've come
to take it for granted so much that I would have completely forgotten to
mention it.
Of course, I sometimes add a contact form and have it send emails. Now I realize that
I actually use 90% of the framework.
That's how I create quick'n'dirty websites and that's how I enjoy
it 😉
Dependency
Injection is a technique that solves certain problems but also introduces
new challenges. These challenges are then addressed by a DI (Dependency
Injection) container, which requires you to adopt a new perspective on
object-oriented design.
If the problems that DI solves do not bother you, then you might perceive its
implementation as an unnecessary hassle, particularly because it necessitates
learning a new approach to object-oriented design.
However, it seems that if you are not bothered by the issues DI addresses,
you have a serious problem. Which you will realize once you discover it.
Yes, the nomination
for Texy is a really nice thing. It lets you learn many new and interesting
insights, discuss things with nice people, and as they say, it moves you a bit
forward.
To introduce the unsuspecting reader to the story: Texy is a little tool that I once programmed a
long time ago (those were the days! I was still young and promising) and made
it available for free to ease the blogging and web development for bloggers and
developers. It became quite popular, running on many blogs, and unexpectedly
entered a popularity contest among similar tools called Czech Open Source. This
article is a showcase of the insults I’ve read because of it. I'm not someone
who expects praise (even if it was deserved, bah! 🙂, but such an atmosphere
doesn't really motivate…
Texy is no longer just sexy. František
Brakon found new epithets:
I wonder WHO exactly selected the individual nominations. It must have been
done in some closed group over beers, it’s not possible. How can, for
example, the lame “one-evening” Texy and the global NetBeans be side
by side?
Spalda
proves the worthlessness of Texy using Google and the link operator:
For example, the previously mentioned CMS, if I consult brother Google:
phpRS: 2,190,000 results, United-Nuke: 692,000 results, BlogCMS:
170,000 results
It’s definitely not used by just a handful of people, compared to the
total fluke named Texy
Spalda
continues to be upset that his favorite CMS was not nominated:
Otherwise, I only started promoting these CMS because when a fluke named
Texy is nominated, these CMS rightfully deserve it many times over
The nomination of Texy nicely completes the level/profanation of the jury and
thus the entire poll
Spalda
is seriously troubled that I might even make a slight profit from Texy! (how
could I, how could I?):
And when you brandish that Texy is free (as if everything else wasn’t
free). We both know Texy isn’t so free… it's not much about selfless work
for the community… but only about using the formulas of free software and open
source to promote and sell commercial licenses
Millions of DONATE icons on all open-source project websites should be
ashamed (Texy doesn't have one), let the MySQL
price list blush in shame. Comrades, this is not how we build communism!
But then comes something that Spalda
literally disarmed me with (just to add, I can't be blamed for the nomination,
I don't know anyone from the jury and I certainly don't defend it):
Don’t you find it embarrassing to defend the nomination of something that
took the place of something that deserved it more?
I was gasping for air, and when I finally caught my breath, the
kicker came:
I understand that connections and business do their thing, but at least
don’t smear it so vocally.
František
Brakon reminds of an ugly spit recently left on Texy! by
“someone” (RH):
You are right, Texy! is about an idea. And lo and behold, it could have
occurred to anyone in the world. And indeed it did. Even before Texy saw the
light of day, there was already the formatter Textile. And lo and behold, it has
almost the same not only name but also syntax!
Dgx recently quarreled to the blood with he-who-must-not-be-named, who
accused him of theft. The
discussion concluded that dgx obviously did not steal the source codes, but
was inspired by Textile and achieved a similar result with his own code and
added some extensions. Nonetheless, the brilliant idea of a “nowysiwyg
editor” does not originate from dgx, and even the name could have been less
eye-catching.
Words fail me. Yes, “NOWYSIWG” editors were here before WYSIWYG – they
came with the invention of typewriters. Including all the entrenched
conventions, which today I call Texy syntax. There’s no point in comparing
who was first, but who is better. However, František
Brakon has more serious objections to Texy:
The proposal seems like a hurrah action “I know regular expressions,
let's try to write a parody of lexical syntactic analysis”. The only thing
I can appreciate is the persistent effort for PHP4/5 compatibility.
I appreciate it in the sense of “he sure struggled”, not in the sense of
“that's good”. If you had given up on PHP4, the result would have been
better. And you could have spared the comments and pieces of code php4_sucks.
You probably didn’t want to lose the fame among lamers, dependent on
questionable hostings.
In response to my note that Texy was created in November 2004, while the
first usable version of PHP 5.0.4 dates to 31 May 2005, he
responds
… in the changelog, I see “version 5.0.4 31-Mar-2005”,
that’s 31 March 2005, you’re skewing it by two months. But let's not be
prudish.
Incidentally, I don’t like narrow chests on women at all.
So, um
Thus, the first result of participating in a poll meant to promote
open-source ideas and highlight domestic projects is that I have once again
a huge desire to tell the entire open-source community to go to hell and
never write another line ;)
Added 5 years later: today, I have a much bigger project (again for free), so there are even
more insults 🙂 Personally, I find it rather funny, no kidding. My family
sees it a bit worse. However, the fact remains that in our country, an unusual
number of assholes need to rub against you, so I would recommend to all open
source creators to throw a poop on their homeland, refuse participation in such
dubious competitions, and create only in English, for abroad.