Video od Microsoftu, které mělo být oslnivou ukázkou
možností Copilota, je spíš tragikomickou prezentací úpadku
programátorského řemesla.
Mluvím o tomto videu.
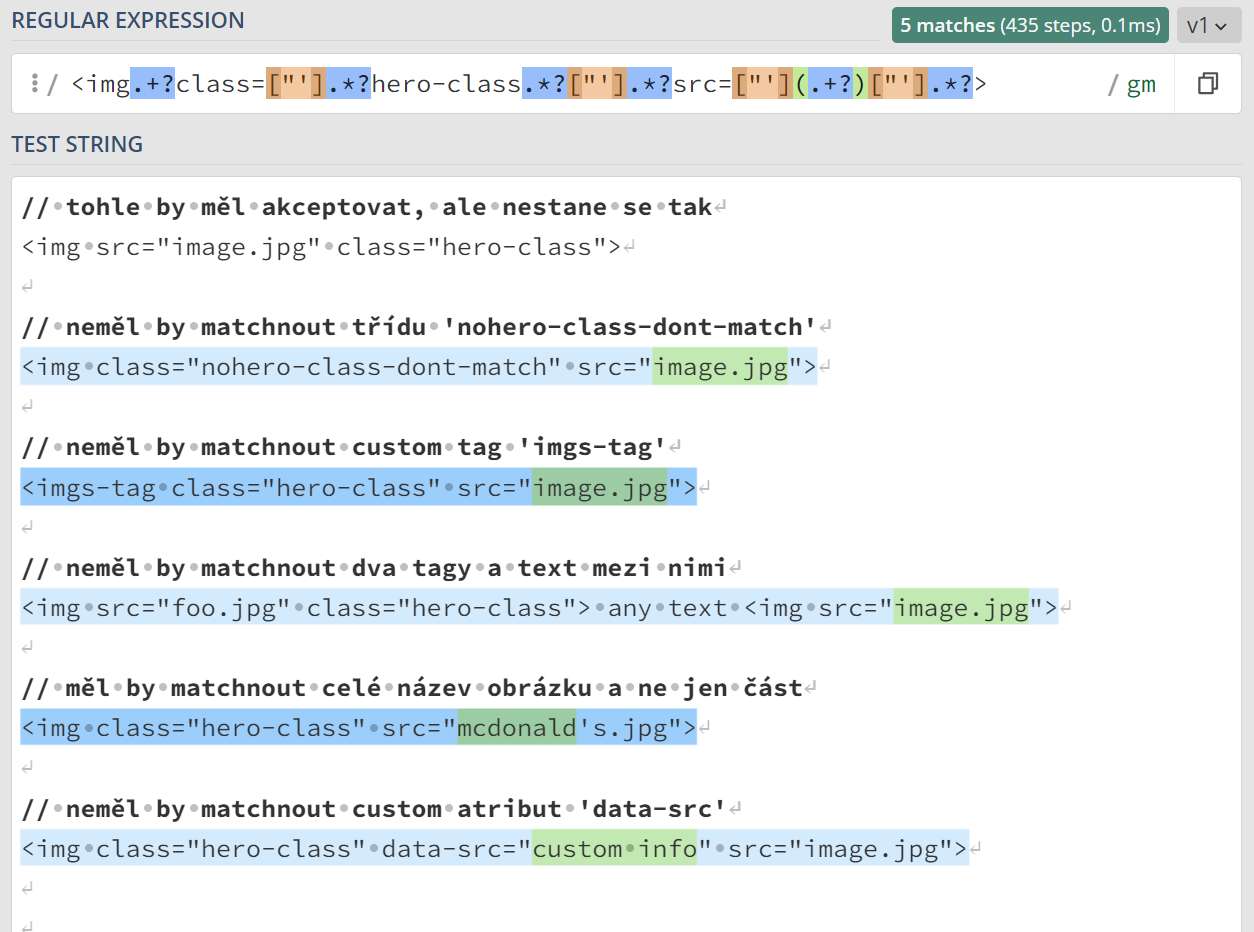
Má demonstrovat možnosti GitHub Copilota, mimo jiné jak pomocí něj napsat
regulární výraz pro vyhledávání značek <img>
s třídou hero-image. Jenže už původní kód, který
upravují, je děravý jako švýcarský sýr, já bych se za něj styděl.
Copilot se nechá strhnout a místo opravy pokračuje ve stejném duchu.
Výsledkem je regulární výraz, který nezamýšleně matchuje i jiné
třídy, jiné značky, jiné atributy a tak dále. Ba co víc, selže, pokud je
atribut src uveden před class.
Píšu o tom, protože tato demonstrace fušeřiny, zejména vzhledem
k oficiální povaze videa, je zarážející. Jak je možné, že si toho
nevšiml ani jeden z prezentujících či jejich kolegů? Nebo si toho všimli
a řekli si, že o nic nejde? To by bylo ještě smutnější. Výuka
programování vyžaduje preciznost a důslednost, bez nichž se snadno mohou
propagovat nesprávné praktiky. Video mělo být oslavou programátorského
umění, ale já v něm vidím ponurou ukázku, jak se úroveň
programátorského řemesla propadá do propasti nedbalosti.
Ale ať nejsem jenom negativní: je tam hezky ukázáno, jak funguje Copilot
a v něm GPT, takže si je určitě pusťte 🙂
Chcete se ponořit do světa objektově orientovaného
programování v PHP, ale nevíte, kde začít? Mám pro vás nového
stručného průvodce OOP, který vás seznámí se všemi těmi pojmy, jako
class, extends, private atd.
Průvodce si neklade za cíl udělat z vás mistry v psaní čistého kódu
nebo podat zcela vyčerpávající informace. Jeho cílem je vás rychle
seznámit se základními koncepty OOP v současném PHP a dát vám fakticky
správné informace. Tedy poskytnout pevný základ, na kterém můžete dále
stavět. Třeba aplikace v Nette.
Jako navazující čtení doporučuji podrobný průvodce
světem správného návrhu kódu. Ten je přínosný i pro všechny, co
PHP a objektově orientované programování ovládají.
Programování v jazyce PHP byla vždycky trošku výzva, ale naštěstí
prošlo mnohými změnami k lepšímu. Pamatujete na časy před verzí PHP 7,
kdy skoro každá chyba znamenala fatal error, což aplikaci okamžitě
ukončilo? V praxi to znamenalo, že jakákoli chyba mohla aplikaci zcela
zastavit, aniž by programátor měl možnost ji zachytit a náležitě na ni
reagovat. Nástroje jako Tracy využívaly magických triků, aby dokázaly
takové chyby vizualizovat a logovat. Naštěstí s příchodem PHP 7 se tohle
změnilo. Chyby nyní vyvolávají výjimky, jako jsou Error, TypeError a
ParseError, které lze snadno zachytávat a ošetřit.
Avšak i v moderním PHP existuje slabé místo, kdy se chová stejně jako
ve své páté verzi. Mluvím o chybách během kompilace. Ty nelze zachytit a
okamžitě vedou k ukončení aplikace. Jedná se o chyby úrovně
E_COMPILE_ERROR. PHP jich generuje na dvě stovky. Vzniká paradoxní situace,
že když v PHP načteme soubor se syntaktickou chybou, což může být třeba
chybějící středník, vyhodí zachytitelnou výjimku ParseError. Ovšem
v případě, že kód je sice syntakticky v pořádku, leč obsahuje chybu
odhalitelnou až při kompilaci (například dvě metody se stejným názvem),
vyústí to ve fatální chybu, kterou zachytit nelze.
Bohužel, kompilační chyby v PHP nemůžeme ověřit interně. Existovala
funkce php_check_syntax(), která navzdory názvu odhalovala
i kompilační chyby. Byla zavedena v PHP 5.0.0, ale záhy odstraněna ve
verzi 5.0.4 a od té doby nikdy nebyla nahrazena. Pro ověření správnosti
kódu se musíme spolehnout na linter z příkazové řádky:
php -l soubor.php
Z prostředí PHP lze ověřit kód uložený v proměnné
$code třeba takto:
Nicméně režie spouštění externího PHP procesu kvůli ověření
jednoho souboru je docela velká. Ale dobrá zpráva přichází s verzí PHP
8.3, která přinese možnost ověřovat více souborů najednou:
Jenže udělal to v době, kdy potřeba používat isset()
značně klesla. Dnes častěji počítáme s tím, že data, ke kterým
přistupujeme, existují. A pokud neexistují, tak se o tom sakra chceme
dozvědět.
Operátor ?? má ale vedlejší efekt a to schopnost detekovat
null. Což je taky nejčastější důvod k jeho užití:
$len = $this->length ?? 'default value'
Bohužel zároveň zatajuje chyby. Zatajuje překlepy:
Bylo by úžasné, kdyby PHP 9.0 mělo odvahu chování operátoru
?? upravit k trošku větší striktnosti. Udělat z „isset
operátoru“ opravdu „null coalesce operator“, jak se mimochodem oficiálně jmenuje.
Chase ve svém příspěvku popisuje zkušenost se zaváděním mezer na
svém pracovišti a negativní dopady, které to mělo na spolupracovníky se
zrakovým postižením.
Jeden z nich byl zvyklý používat šířku tabulátoru 1, aby se vyhnul
velkým odsazením při použití obřího písma. Druhý používá šířku
tabulátoru 8, protože mu nejlépe vyhovuje na ultraširokém monitoru. Pro oba
však představuje kód s mezerami vážný problém, musí je převádět na
tabulátory před čtením a zase zpátky na mezery před komitováním.
Pro nevidomé programátory, kteří používají braillské displeje,
představuje každá mezera jednu braillskou buňkou. Pokud je tedy výchozí
odsazení 4 mezery, odsazení 3. úrovně plýtvá 12 cennými braillskými
buňkami ještě před začátkem kódu. Na 40buňkovém displeji, který se
u notebooků používá nejčastěji, je to více než čtvrtina dostupných
buněk, které jsou promrhány bez jakékoliv informace.
Nám se může přizpůsobení šířky odsazení zdát jako zbytečnost,
jsou ale mezi námi programátoři, pro které je naprosto nezbytné. A to
prostě nemůžeme ignorovat.
Tím, že budeme v našich projektech používat tabulátory, dáváme jim
možnost tohoto přizpůsobení.
Nejdříve
přístupnost, pak osobní preference
Jistě, nejde přesvědčit každého, aby se přiklonil na jednu či druhou
stranu, jde-li o preference. Každý má své. A měli bychom být rádi za
možnost volby.
Zároveň však musíme dbát na to, abychom zohledňovali všechny. Abychom
respektovali odlišnosti a používali přístupné prostředky. Jakým je
například znak tabulátor.
Myslím, že Chase to vystihl dokonale, když ve svém příspěvku uvedl,
že „…neexistuje žádný protiargument, který by se jen blížil k tomu
převážit potřeby přístupnosti našich spolupracovníků“.
Accessible first
Stejně jako při navrhování webů se vžila metodika „mobile first“,
kdy se snažíme zajistit, aby každý, bez ohledu na zařízení, měl
s vaším produktem skvělou user experience – měli bychom usilovat o
„accessible first“ prostředí tím, že zajistíme, aby každý měl
stejnou možnost pracovat s kódem, ať už v zaměstnání nebo na opensource
projektu.
Pokud se tabulátory stanou výchozí volbou pro odsazování, odstraníme
jednu bariéru. Spolupráce pak bude příjemná pro každého, bez ohledu na
jeho schopnosti. Pokud budou mít všichni stejné možnosti, můžeme
maximálně využít společný potenciál ❤️
Knihovna Texy od verze 3.1.6 přidává podporu pro Latte
3 v podobě značky {texy}. Co umí a jak ji nasadit?
Značka {texy} představuje snadný způsob, jak v Latte
šablonách psát přímo v syntaxi Texy:
{texy}
You Already Know the Syntax
----------
No kidding, you know Latte syntax already. **It is the same as PHP syntax.**
{/texy}
Stačí do Latte nainstalovat rozšíření a předat mu objekt Texy
nakonfigurovaný podle potřeby:
$texy = new Texy\Texy;
$latte = new Latte\Engine;
$latte->addExtension(new Texy\Bridges\Latte\TexyExtension($texy));
Pokud je mezi značkami {texy}...{/texy} statický text, tak se
přeloží pomocí Texy už během kompilace šablony a výsledek do ní
uloží. Pokud je obsah dynamický (tj. jsou uvnitř Latte značky),
zpracování pomocí Texy se provádí pokaždé při vykreslování
šablony.
Pokud je žádoucí Latte značky uvnitř vypnout, dá se to
udělat takto:
{texy syntax: off} ... {/texy}
Do rozšíření lze kromě objektu Texy předat také vlastní funkci a tak
umožnit předávat ze šablony parametry. Kupříkladu chceme mít možnost
předávat parametry locale a heading:
$processor = function (string $text, int $heading = 1, string $locale = 'cs'): string {
$texy = new Texy\Texy;
$texy->headingModule->top = $heading;
$texy->typographyModule->locale = $locale;
return $texy->process($text);
};
$latte = new Latte\Engine;
$latte->addExtension(new Texy\Bridges\Latte\TexyExtension($processor));
Parametry v šabloně předáme takto:
{texy locale: en, heading: 3}
...
{/texy}
Pokud chcete pomocí Texy formátovat text uložený v proměnné, můžete
použít filtr:
Prosím o fanfáry, na scénu přichází Latte
3. S kompletně přepsaným kompilátorem. Nová verze představuje
největší vývojový skok, jaký kdy v Nette nastal.
Proč vlastně Latte
Latte má překvapivou historii.
Původně totiž nebylo myšleno vážně. Mělo dokonce demonstrovat, že
žádný šablonovací systém není v PHP potřeba. Bylo pevně spjato
s presentery v Nette, kde však nebylo defaultně zapnuté a programátor jej
musel aktivovat přes tehdejší ošklivý název CurlyBracketsFilter.
Zvrat přišel až s nápadem, že šablonovací systém by mohl HTML
stránce rozumět. Vysvětlím. Pro ostatní šablonovací systémy je text
v okolí značek jen šumem bez jakéhokoliv významu. Je jedno, jestli jde
o HTML stránku, CSS styl nebo třeba text v Markdownu, šablonovací engine
vidí jen shluk bajtů. Latte naopak dokument chápe. Což přináší spoustu
zásadních výhod. Od komfortu v podobě vychytávek jako jsou třeba n:attributy, až po
ultimátní bezpečnost.
Latte tak ví, jakou použít escapovací funkci (což
většina programátorů neví, ale díky Latte to nevadí a nevytvoří
bezpečnostní díru Cross-site
scripting). Zabrání vypsání řetězce, který by v určitém místě byl nebezpečný. Dokonce
dokáže předejít dezinterpretaci mustache
závorek frontendovým frameworkem. A bezpečnostní experti nebudou mít
co žrát :)
Nečekal bych, že tímto nápadem přeběhne Latte ostatní systémy
o 10 let, protože dodneška vím pouze o dvou, co takto fungují. Krom Latte
je to ještě Soy od Google. Latte a Soy jsou jediné opravdu bezpečné
šablonovací systémy pro web. (Byť teda Soy ze zmíněných vychytávek má
pouze to escapování.)
Druhou klíčovou vlastností Latte je, že pro výrazy uvnitř značek
(někdy se říká maker) používá jazyk PHP. Tedy syntaxi programátorovi
důvěrně známou. Vývojář se tak nemusí učit nový jazyk. Nemusí
zkoumat, jak se to či ono v Latte píše. Prostě to napíše tak jak umí.
Naopak třeba populární šablonovací systém Twig používá syntaxi Pythonu,
kde se i zcela základní konstrukce píší odlišně. Například
foreach ($people as $person) se v Pythonu (a tedy i Twigu) píše
jako for person in people, což zcela zbytečně nutí mozek
přepínat mezi dvěma opačnými konvencemi.
Latte tedy má oproti konkurenci natolik podstatnou přidanou hodnotu, že
má smysl investovat úsilí do jeho údržby a vývoje.
Současný kompilátor
Latte a jeho syntax vznikla před 14 lety (rok 2008), současný kompilátor
o tři roky později. Uměl už tehdy vše podstatné, co se dodnes používá,
tedy i bloky, dědičnost, snippety atd.
Kompilátor fungoval jako jednoprůchodový, což znamená, že parsoval
šablonu a rovnou ji přetvářel do PHP kódu, který sestavil do výsledného
souboru. Jazyk PHP používaný ve značkách (tj. v makrech) se tokenizoval a
poté procházel několika procesy, které tokeny upravovaly. Jeden proces
doplňoval řetězcové uvozovky kolem identifikátorů, jiný přidával
syntaktické vychytávky, které PHP tehdy neznalo (například zápis polí
pomocí [] místo array(), nullsafe operátory
?->) nebo které nezná doposud (zkrácený ternární
operátor, filtry ($var|upper|truncate), atd).
Tyto procesy ale nijak nekontrolovaly PHP syntax nebo používané
konstrukce. Což se výrazně změnilo až před dvěma lety (rok 2020)
s příchodem sandbox režimu.
Sandbox hledá v tokenech možné volání funkcí a metod a upravuje je, což
není vůbec jednoduché. Přičemž případné selhání je vlastně
bezpečností chybou.
Nový kompilátor
Za jedenáct let vývoje Latte se našly situace, kdy jednoprůchodový
kompilátor nestačil (třeba při inkludování bloku, který ještě nebyl definován). Všechny
issue šlo sice vyřešit, ale ideální by bylo přejít na dvoukrokovou
kompilaci, tedy nejprve šablonu naparsovat do mezipodoby, do AST stromu, a pak
teprve z něj vygenerovat kód třídy.
Taktéž s postupným vylepšováním PHPlike jazyka používaného
ve značkách přestávala dostačovat reprezentace v tokenech a ideální by
bylo i jej naparsovat do AST stromu. Naprogramovat sandbox nad AST stromem je
výrazně snadnější a dá se garantovat, že bude skutečně
neprůstřelný.
Trvalo mi pět let se do přepsání kompilátoru pustit, protože jsem
věděl, že to bude extrémně náročné. Už samotná tokenizace
šablony představuje výzvu, neboť musí běžet paralelně s parsováním.
Parser totiž musí mít možnost ovlivňovat tokenizaci, když například
narazí na atribut n:syntax=off.
Podporu pro paralelní běh dvou kódů přináší až Fibers v PHP 8.1,
nicméně Latte je zatím nevyužívá, aby mohlo fungovat na PHP 8.0. Místo
toho používá obdobné coroutines (v dokumentaci PHP o nich nic nenajdete,
tak alespoň odkaz na Generator
RFC). Pod kapotou Latte se tedy odehrávají kouzla.
Nicméně jako ještě mnohem náročnější úkol mi připadalo napsat
lexer a parser pro tak komplexní jazyk, jako je dialekt PHP používaný ve
značkách. V podstatě to znamenalo vytvořit něco jako nikic/PHP-Parser pro
Latte. A zároveň i nutnost formalizovat gramatiku tohoto jazyka.
Dnes můžu říct, že se mi povedlo všechno dokončit. Latte má
kompilátor, jaký jsem si dlouhá léta přál. A z toho původního nezbyl
ani jediný řádek kódu 🙂
Před mnoha lety jsem si uvědomil, že když v PHP ve funkci používám
proměnnou obsahující předdefinovanou tabulku dat, tak při každém volání
funkce musí být pole znovu „vytvořené“, což je překvapivě dost
pomalé. Příklad:
Zrychlení, pokud pole bylo trošku větší, se pohybovalo v několika
řádech (jako třeba klidně 500×).
Takže od té doby jsem u konstantních polí vždy používal
static. Je možné, že tento zvyk někdo následoval, a třeba ani
netušil, jaký má skutečný důvod. Ale to nevím.
Před pár týdny jsem psal třídu, která nesla v několika properties
velké tabulky předdefinovaných dat. Uvědomil jsem si, že to bude zpomalovat
vytváření instancí, tedy že operátor new bude pokaždé
„vytvářet“ pole, což jak víme je pomalé. Tudíž musím properties
změnit na statické, nebo možná ještě lépe použít konstanty.
A tehdy jsem si položil otázku: Hele a nejsi jen ve vleku cargo kultu? Opravdu pořád
platí, že bez static je to pomalé?
Těžko říct, PHP prošlo revolučním vývojem a staré pravdy nemusí
být platné. Připravil jsem proto testovací vzorek a udělal pár měření.
Samozřejmě jsem si potvrdil, že v PHP 5 použití static uvnitř funkce
nebo u properties přineslo zrychlení o několik řádů. Ale pozor, v PHP
7.0 už šlo jen o jeden řád. Výborně, projev optimalizací v novém
jádře, ale stále je rozdíl podstatný. Nicméně u dalších verzí PHP
rozdíl dál klesal a až postupně téměř vymizel.
Dokonce jsem zjistil, že použití static uvnitř funkce v PHP 7.1 a
7.2 běh zpomalovalo. Zhruba 1,5–2×, tedy z pohledu řádů, o kterých se
tu celou dobu bavíme, zcela zanedbatelně, ale byl to zajímavý paradox. Od
PHP 7.3 rozdíl zmizel zcela.
Zvyklosti jsou dobrá věc, ale je nutné jejich smysl stále validovat.
Zbytečný static v těle funkcí už používat nebudu. Nicméně u oné
třídy, která držela velké tabulky předdefinovaných dat v properties,
jsem si řekl, že je programátorsky správné konstanty použít. Za chvíli
jsem měl refaktoring hotový, ale už jak vznikal jsem naříkal nad tím, jak
se kód stává ošklivým. Místo $this->ruleToNonTerminal nebo
$this->actionLength se v kódu objevovalo řvoucí
$this::RULE_TO_NON_TERMINAL a $this::ACTION_LENGTH a
vypadalo to fakt hnusně. Zatuchlý závan ze sedmdesátých let.
Až jsem zaváhal, jestli vůbec chci koukat na tak hnusný kód, a jestli
raději nezůstanu u proměnných, případně statických proměnných.
A tehdy mi to došlo: Hele nejsi jen ve vleku cargo kultu?
No jasně že jsem. Proč by měla konstanta řvát? Proč by měla na sebe
upozorňovat v kódu, být vyčnívajícím elementem v toku programu? Fakt,
že struktura slouží jen ke čtení, není důvod PRO ZASEKNUTÝ CAPSLOCK,
AGRESIVNÍ TÓN A HORŠÍ ČITELNOST.
TRADICE VELKÝCH PÍSMEN POCHÁZÍ Z JAZYKA C, KDE SE TAKTO OZNAČOVALY
MAKROKONSTANTY PREPROCESORU. BYLO UŽITEČNÉ NEPŘEHLÉDNUTELNĚ ODLIŠIT KÓD
PRO PARSER OD KÓDU PRO PREPROCESOR. V PHP SE ŽÁDNÉ PREPROCESORY NIKDY
NEPOUŽÍVALY, TAKŽE NENÍ ANI DŮVOD psát konstanty velkými písmeny.
Ještě ten večer jsem je všude zrušil. A stále nemohl pochopil, proč
mě to nenapadlo už před dvaceti lety. Čím větší blbost, tím tužší
má kořínek.
Vždycky mi vadila jakákoliv nadbytečnost nebo duplicita v kódu. Už jsem
o tom psal před mnoha lety. Při
pohledu na tento kód prostě trpím:
interface ContainerAwareInterface
{
/**
* Sets the container.
*/
public function setContainer(ContainerInterface $container = null);
}
Obsahovou zbytečnost komentáře u metody ponechme stranou.
A protentokrát i projev nepochopení dependency injection, pokud knihovna
potřebuje disponovat takovým rozhraním. O tom, že použití slova
Interface v názvu rozhraní je pro změnu projevem nepochopení
objektového programování, chystám samostatný článek. Koneckonců jsem si
tím sám prošel.
Ale proč proboha uvádět viditelnost public? Vždyť je to pleonasmus. Kdyby to nebylo
public, tak to pak není rozhraní, ne? No a ještě někoho napadlo z toho
udělat „standard“ ?♂️
Uff, omlouvám se za dlouhý úvod, to, kam celou dobu směřuju, je zda
psát volitelné nullable typy s otazníkem nebo bez. Tj:
// bez
function setContainer(ContainerInterface $container = null);
// s
function setContainer(?ContainerInterface $container = null);
Osobně jsem se vždycky klonil k první možnosti, protože informace daná
otazníkem je redundantní (ano, oba zápisy znamenají z pohledu jazyka
totéž). Zároveň se tak zapisoval veškerý kód do příchodu PHP 7.1, tedy
verze, která otazník přidala, a musel by být dobrý důvod jej
najednou měnit.
S příchodem PHP 8.0 jsem názor změnil a vysvětlím proč. Otazník
totiž není volitelný v případě properties. Na tomhle PHP zařve:
class Foo
{
private Bar $foo = null;
}
// Fatal error: Default value for property of type Bar may not be null.
// Use the nullable type ?Bar to allow null default value
A dále od PHP 8.0 lze používat promoted
properties, což umožňuje psát takovýto kód:
class Foo
{
public function __construct(
private ?Bar $foo = null,
string $name = null,
) {
// ...
}
}
Zde je vidět nekonzistence. Pokud je v kódu použito ?Bar
(což je nutnost), mělo by o řádek níže následovat ?string.
A pokud v některých případech budu psát otazník, měl bych ho psát
ve všech.
Zůstává otázka, zda není lepší používat místo otazníku přímo
union typ string|null. Pokud bych třeba chtěl zapsat
Stringable|string|null, verze s otazníkem možná
vůbec není.
Aktualizace: vypadá to, že PHP 8.4 bude zápis s otazníkem přímo
vyžadovat.
Zajímalo mě, který PHP framework má nejlepší dokumentaci.
A jak si v žebříčku stojí Nette. Jenže jak to zjistit?
Všichni víme, že nejhorší je žádná dokumentace. Pak následuje
nedostatečná dokumentace. Opakem je obsáhlá dokumentace. Tedy zdá se, že
důležitým vodítkem je samotný objem dokumentace. Pochopitelně obrovskou
roli hraje i její srozumitelnost a aktuálnost, dojem dělá čtivost a
bezchybnost. Tyto faktory se velmi těžko měří. Nicméně sám vím, kolik
částí dokumentace Nette jsem mnohokrát přepsal, aby byly jasnější, kolik
oprav jsem mergoval, a předpokládám, že se tak děje u každého letitého
frameworku. Že tedy postupně všechny dokumentace konvergují k podobné
vysoké kvalitě. Tudíž si jako vodítko dovolím brát čistě objem dat,
byť jde o zjednodušení.
Pochopitelně se objem dokumentace musí dát do poměru s velikostí té
které knihovny. Některé jsou i řádově větší než jiné a pak by měly
mít i řádově větší dokumentaci. Pro jednoduchost budu velikost knihovny
stanovovat podle objemu PHP kódu. S normalizovaným bílým místem, bez
komentářů.
Vytvořil jsem graf poměru anglické dokumentace ku kódu u známých
frameworků CakePHP (4.2), CodeIgniter (3.1), Laravel (8.62), Nette (3.1),
Symfony (5.4), YII (2.0) a Zend Framework (2.x, již nevyvíjený):
Jak z grafu vidíte, obsáhlost dokumentace vůči kódu je u všech
frameworků víceméně podobná.
Vyčnívá CodeIgniter. Smekám před CakePHP a YII, které se snaží
udržovat dokumentaci v celé řadě dalších jazyků. Obsáhlost dokumentace
Nette je nad průměrem. Zároveň Nette je jediný framework, který má 1:1
překlad i v naší mateřštině.
Smyslem grafu NENÍ ukázat, že ten či onen framework má o tolik procent
obsáhlejší dokumentaci než jiný. Na to je metrika příliš primitivní.
Smyslem je naopak ukázat, že obsáhlost dokumentace u jednotlivých
frameworků z velké míry srovnatelná. Vytvořil jsem jej hlavně pro sebe,
abych získal představu, jak je na tom dokumentace Nette ve srovnání
s konkurencí.
Původně vyšlo v srpnu 2019, údaje jsou aktualizované pro
říjen 2021.