Na zálohování jsem si pořídil úžasný prográmek Drive SnapShot. Umí
zálohovat celé disky, má pouhých
160kB a funguje nejen pod Windows , ale i pod DOS. Což se náramně hodí,
pokud potřebujeme obnovit zhroucené Windows. A hlavně: umí provádět
rozdílové zálohování, archívy šifrovat (AES, 128bit) a poté je mountovat
jako další disk! Vřele doporučuji vyzkoušet.
Tento prográmek (stejně jako jemu podobné: Norton Ghost, Acronis True
Image) dokáže uložit přesný obraz disku, jaký existoval v okamžiku
spuštění. Vždycky mě ale zajímalo, jak zálohování on-fly vlastně
funguje. Vždyť celá operace nějakou chvíli trvá. Od minut až po hodiny.
Přesto program vytvoří přesný obraz disku, ať už s ním během
zálohování dělám cokoliv. Jak je to možné?
Vše se točí kolem vyspělých operačních systémů na bázi NT. Tedy
třeba Windows Vista, nikoliv však zastaralých 95/98. Při spuštění
zálohování přikáže aplikace operačnímu systému, aby uložil všechna
data, která si drží v paměti, na disk. Poté se napojí na diskový
ovladač, aby mohla monitorovat každý přístup na disk. A zahájí
kopírování pěkně sektor za sektorem.
Jakmile se objeví požadavek na zápis na disk, a to v místě, které
ještě nebylo zálohované, tak tento sektor přednostně zazálohuje a pak
teprve zápis povolí.
V tom je celý trik. Jakmile odstartujeme zálohování, můžeme na disku
jakkoliv řádit, instalovat či mazat programy, chytit virus. Záloha bude
vždy obsahovat konzistentní podobu disku v okamžiku spuštění.
Chytré, co?
Řada projektů opouští populární verzovací systém
Subversion a přechází na jiný. Jaké jsou důvody?
K používání Subversion (SVN)
mě přiměl kdosi v počátcích vývoje Texy. Do té doby jsem „verzoval“
archivováním složky s kódem do RARu před každým větším zásahem.
A něco sofistikovanějšího by bodlo. Veřejnému repositáři jsem
odolával, protože mi připadalo, jako by mi někdo koukal při programování
pod prsty. Zkusil jsem proto lokální SVN server s už tehdy skvělým GUI TortoiseSVN a rychle si na nový styl
práce zvykl.
Teprve mnohem později jsem začal používat veřejné SVN. Pokud si
odmyslím nezpochybnitelné komunitní výhody, jako je spolupráce více
vývojářů a přidaný rozměr pro chápání kódu (čas), nepřineslo to
z hlediska jednotlivce nic pozitivního. Nešlo pracovat offline, dříve
okamžité operace trvaly dlouhé sekundy. Jakákoliv chyba byla
navždy zvěčněna v historii repositáře. Zjistil jsem, že během vývoje
dílčích částí zase verzuji RARem a Subversion mi přestal pomáhat.
Oči mi otevřel až Karmi, když mi
ukázal, že kromě centralizovaných repositářů, jako je SVN, existují
i distribuované (DVCS), které všechny
zmíněné problémy řeší. Jsou umístěny lokálně s celou historií,
takže nepotřebují internet a reagují bleskově. Lze v nich zkušebně
rozvíjet několik vývojových cest. Ty slepé smažete, správnou pustíte na
„centrální“ repositář. Úžasné! A tím výčet výhod nekončí.
Přejít na distribuovaný verzovací systém mi vyplynulo jako nutnost.
Jaký distribuovaný systém
zvolit?
Karmi propaguje Git, který
současné úložiště mých projektů Google
Code nepodporuje. Nabízí však alternativu v podobě systému Mercurial (HG).
Kromě těchto dvou je ještě slyšet o Bazaar. Který z nich
zvolit? Jak se liší?
Pustil jsem se do důkladné rešerše a zjistil, že dobrat se odpovědi
není vůbec snadné. Protože Subversion ve prospěch distribuovaných
systémů opouští čím dál více projektů (jen PHP nyní slavně přešlo
na SVN, hehehe), narazil jsem na tyto analýzy:
Z obou je cítit bezradnost a ačkoliv volba padla na Mercurial, důvody
nesouvisí s objektivní kvalitou systémů. Navíc za poslední půl rok se
hodně změnilo a zmíněná absence GUI pro Windows v případě Gitu je dnes
naopak jeho předností (tj. už má skvělé GUI).
Z dalších úvah jsem vyřadil nejmladší a nejméně populární Bazaar a
podíval se zblízka na Git s Mercurialem.
Git
obrovský a komplexní projekt (možná až zmatený a nesrozumitelný)
umožňuje zasahovat do historie, mazat slepé větve
domovem je mu Linux, na Windows to není úplně ono
napsaný v C a shell skriptech
import i export SVN včetně historie
hosting: Github.com (mnohem lepší než
Google Code)
GUI nástroj: TortoiseGit (vypadá přesně
jako TortoiseSVN) a GIT Cheetah
Od začátku mi byl sympatičtější Mercurial, protože mám raději malé,
šikovné a promyšlené věci, než molochy (nejen ve frameworcích). Lépe
funguje na Windows (import SVN repositáře je 70× rychlejší než na Git).
Podporuje jej Google Code.
Jenže svět je složitější. Příklad: Mercurial má srozumitelnější
příkazovou řádku, podobnou té v SVN. Jenže stejně ho budu ovládat
pomocí GUI. Tam naopak (dnes) vede TortoiseGit, který jako by z oka vypadl
TortoiseSVN, zatímco TortoiseHg je hodně jiný a slabší. Ale tím, že je
jiný, umožňuje commitovat tzv. hunks.
Což se mi skutečně často hodí. Nicméně s distribuovaným repositářem
přichází jiný styl práce – budu i poté potřeboval hunks?
Mercurial čísluje revize, Git používá 40 místný hash. Preferuju
samozřejmě číslo, ale není to jen pozůstatek SVN uvažování?
A tak by se dalo pokračovat dále. Nejsem zatím schopen říct, který ze
systémů více vyhovuje mým potřebám. Jediná možnost je oběma věnovat
několik dní času a zkusit s nimi pracovat. Co však můžu říct
s naprostou jistotou je, že SVN chci opustit.
Mladí chlapci se musejí vymezovat proti autoritám. Mají to v popisu
práce. V diskusi neváhají nedostatek zkušeností nahradit sebejistotou a
drzostí. Fakt hloupé to začíná být ve chvíli, kdy vlastně jen
nahrazují.
Marian Koubala alias Emco se poměrně ostře pustil do Jakuba Vrány pod
článkem o bezpečnostním auditu serveru Na volné noze. Na věci je
pikantní, že Marian Koubala je Jakubův konkurent, neboť provozuje službu
komerčně nabízející bezpečnostní audity webových aplikací.
Obdivuju Jakuba, s jakou trpělivostí se nechal penetrovat mladistvým
script
kiddie, já bych ho asi smazal hned v zárodku. Jakub je v tomto směru
až hyperkorektní a jsem přesvědčen, že si tak poškozuje své jméno.
Když totiž diskusi přečte neodborník, nemusí mu být úplně
zřejmé, kdo je tady vlastně za diletanta. Čtenář potřebuje vodítko a
proto vznikl tento článek.
Takže vězte: Marian Koubala alias Emco je úplně mimo. Patří do
sorty tzv. „bezpečnostních odborníků“, kteří tohoto sice hodně
načetli, jenže při čtení vůbec nepřemýšleli. Vědí o spoustě
útoků, ale nemají páru o technickém pozadí a neví, jak jim skutečně
čelit. Na argumenty nejsou schopni reagovat jinak, než odkazováním na (dle
jejich názoru) autoritativní zdroje, tedy v tom lepším případě, v tom
horším se uchylují k osobním útokům. Dokážou však udělat výborný
první dojem a ohromit množstvím znalostí. Že jsou jejich rady
kontraproduktivní, se nemusí hned zjistit.
Emco script
Ale zpět k diskusi. Emco upozorňuje na útok upload null byte, který prý
souvisí s nastavením direktivy magic_quotes_gpc a prý
znemožňuje kontrolu nahraného obrázku na základě jeho přípony. Diskuse
poté kráčí ve výše popsaných šlépějích, takže o upload null byte
útoku nebo direktivě magic_quotes_gpc se od něj nedozvíme
vůbec nic, zato se dočteme, že Jakub je blázen, stahovačný (sic!), líný
hlupák a tak vůbec ;)
V jedné chvíli však Emco neprozřetelně utrousí moudra a podělí se
o kus PHP kódu. Ten by měl demostrovat zmíněný null byte útok, vtipné
však je, že prakticky na každém řádku je nějaká chyba. Od méně
závažných po naprosto fatální bezpečnostní díru:
if (strtolower(substr($HTTP_POST_FILES['obrazek']['name'], -4, 4)) == ".jpg") {
$path= "upload/".urldecode($HTTP_POST_FILES['obrazek']['name']);
if($ufile != none) {
if(move_uploaded_file($HTTP_POST_FILES['obrazek']['tmp_name'], $path))
echo "Obrazek byl uspesne nahran na server";
else
echo "Obrazek se nepodarilo nahrat na server";
}
} else
echo "Neplatny format obrazku";
Jen bodově:
pole $HTTP_POST_FILES bylo zavrženo už v roce 2001,
jeho použití mě docela
překvapilo
neověřuje existenci prvku $HTTP_POST_FILES['obrazek']['name']
a může tak generovat neošetřené E_NOTICE
neověřuje, že prvek $HTTP_POST_FILES['obrazek']['name'] je
řetězec a může tak generovat neošetřené E_NOTICE (viz
<input type="file" name="obrazek[]">)
urldecode() nemá v kódu co dělat. Pokud budete uploadovat
soubor nazvaný třeba 70%absinth.jpg, na straně serveru byste
dostali 70«sinth.jpg
urldecode() je místo, kde se zcela uměle vytváří díra
„upload null byte“
podmínka if($ufile != none) pracuje s nedefinovanou
proměnnou $ufile a nedefinovanou
konstantou none
kód neřeší situaci, kdy $ufile == none, ať už je tím
myšleno cokoliv
ke složce upload přistupuje relativně, takže se může
chovat velmi nepředvídatelně
ale hlavně: dovoluje přepsat jakýkoliv jpg na webovém serveru,
tedy i mimo adresář pro upload! (např. %2e%2e%2fobr.jpg)
kvůli uměle vytvořené „upload null byte“ díře dovoluje přepsat
jakýkoliv soubor na webu (např. .htaccess%00.jpg)
Všechny tři řádky obsahující konstrukci echo se zdají
být bez problému. Gratulujeme!
Na závěr bych Marianovi vzkázal jeho vlastní slova: chtel bych videt
hlupaky, co ti za to tvoje bezpecnostni skoleni plati bezmala 5 000,– Kc.
venuj se dal php a neprodavej lidem falesny pocit bezpeci v podobe amaterskych
bezpecnostnich auditu… A firmám, které uvádí ve svých referencích
doporučuji, aby si nechaly udělat audit také jinde.
Zajímá vás, kolik vývojářů skutečně stojí za
slavými projekty, bez marketingového mlžení? Pokusím se vyvrátit jeden
mýtus, který někdy zaznívá proti Nette
Framework, ale je docela možné, že vás tím připravím o iluze.
Čtěte proto jen na vlastní nebezpečí 🙂
O jaký jde mýtus? Pod Jakubovým
článkem o vývoji open source projektů padl komentář:
Přesně tohle (tj. velmi malý počet vývojářů) je důvod proč
dělám v Zendu a ne v Nette. Nette je skvělé protože ho dělá David.
Jakmile s tím přestane, tak půjde do kytek i kdyby mělo komunitu
sebelepší.
Musím oponovat: projekt může zakladatele přežít vlastně jen tehdy,
pokud sebelepší komunitu má. Nette Framework je svou komunitou už
pověstný. Dovolím si zopakovat slova z minulého článku:
podívejte se na české fórum, kde
jsou desetitisíce příspěvků. Žádný jiný webový framework u nás tak
aktivní a početnou komunitu nemá.
Ale vraťme se k počtu klíčových vývojářů u jednotlivých
projektů. Obvyklá představa, že za každým významným projektem stojí
početný tým vzájemně nahraditelných vývojářů, začala brát za své,
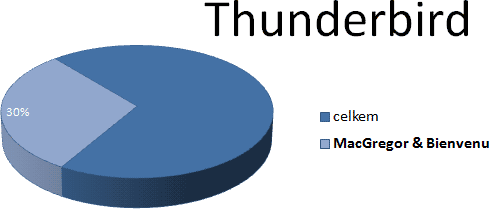
když před dvěma lety vyšla zpráva, že projekt Thunderbird opouštějí
oba
hlavní vývojáři. Ano, zarážející je už to slůvko „oba“. Odchod
pouhých dvou vývojářů Scotta MacGregora a Davida Bienvenu způsobil, že
nad celým projektem se začala stahovat mračna.
Dejme to do souvislosti se zajímavými čísly, které nabízí server
Ohloh. O projektu Thunderbird mi
prozradil, že má úctyhodných 24073 commitů (commit je jeden
příspěvek do kódu od jedné osoby). Přičemž na ty dva zmíněné
vývojáře připadá 30 % commitů:
Opakuji: celých 30 % vývoje Thunderbirdu obstarali dva programátoři,
jejichž odchod může být pro projekt smrtelný.
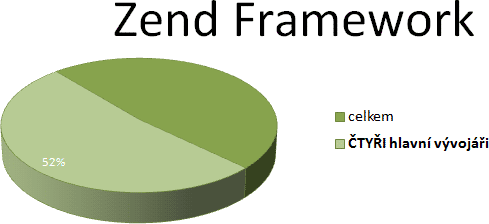
Nebudu chodit kolem horké kaše a podívám se stejnou metodikou na zoubek
Zend Framework. Na obří
framework, či spíše knihovnu, za jehož popularitou stojí jméno
společnosti Zend a pro nějž hovoří „stovky vývojářů“ + několik
„placených“. Nechme promluvit čísla:
Ano, 52 % frameworku je práce čtyř lidí. A pozor: na 2 hlavní
vývojáře připadá 32 % frameworku, tedy situace je ještě malinko
„dramatičtější“ než v případě Thunderbirdu. Přesto nepochybuji,
že pokud ty dva vývojáře srazí tramvaj (nebo šalina), vývoj frameworku by
sice na nějakou dobu ustrnul, ale bude pokračovat dál.
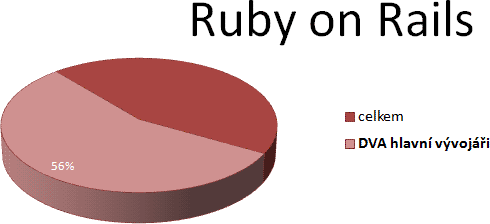
Zend Framework přitom patří ještě mezi ty méně ohrožené projekty. Co
třeba slavné Ruby on Rails? Na
grafu vidíte poměr commitů dvou hlavních vývojářů:
Pouhým dvěma vývojářům patří majorita. A ptám se: je snad Ruby on
Rails odmítané proto, že by mohla Davida Heinemeiera Hanssona srazit šalina?
Nebo naopak se bere jeho vize a pevné uchopení projektu jako výhoda?
A obává se někdo, že ti dva nejsou placení vývojáři?
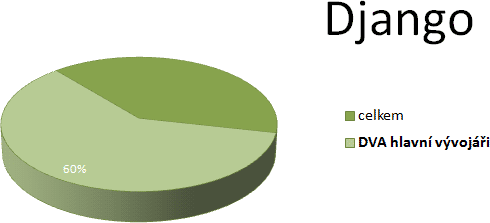
Když už brousíme mimo PHP, podívejme se na nejslavnější framework pro
Python – Django:
O čtyři procenta víc než v předchozím případě. Bez dalšího
komentáře.
Tak zpět do PHP luhů a hájů. Kromě Zend Framework a Nette Framewok se
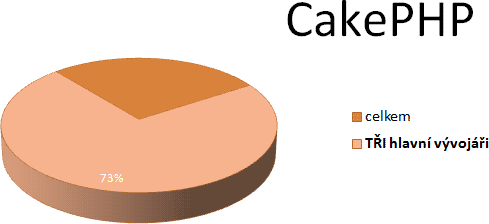
u nás těší největší popularitě asi CakePHP. Podle statistik jde o dílo
tří hlavních vývojářů:
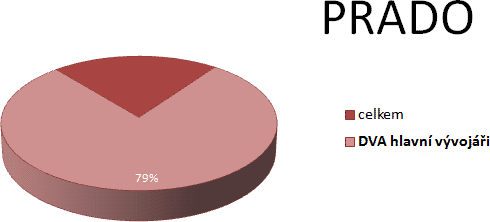
Ještě bych měl zmínit PRADO,
kde téměř kompletní vývoj má pod palcem dvojice programátorů:
Z uvedených příkladů jde rozhodně o nejvyšší hodnoty. V tomto
případě bych si už netroufl paušálně tvrdit, že by projekt pokračoval
navzdory odchodu dvou vývojářů pod tramvaj – musel bych nejprve dobře
znát komunitu kolem PRADO.
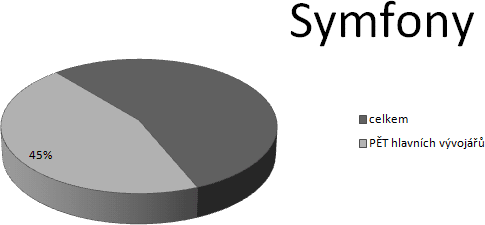
Ale ať skončíme pozitivně. Nakonec jsem si nechal projekt, který
rozložením sil vychází jednoznačně nejlépe a tím je Symfony:
Nicméně i zde existuje dominantní jedinec, vůdce stáda, který
převažuje nad ostatními.
Je vážně tak zle?
Ale vůbec ne! Pochopte prosím, že mým cílem nebylo vás strašit, ale
pouze uvést do reality a demaskovat marketingové pozlátko. Raději
zdůrazním, že
jednotlivá čísla vůbec nic nevypovídají o kvalitách projektů
nelze je použít ani jako vodítko při rozhodování
Naopak je přirozené a logické, že všechny projekty jsou dílem několika
málo osobností. Tak je to na světě zařízené. A naopak, čím více lidí
má právo commitovat, tím více se do kódu dostane
balastu. Jak se dokáže ten který projekt vyrovnat se ztrátou
vůdčích osob je vždycky nejisté. V případě Nette Framework mě těší
vědomí, že konečně po 5 letech vývoje mám naději, že by se vyrovnat
dokázal.
Doplnění: Karmi mi v komentářích připomněl důležitou věc, kterou jsem v článku
opomněl a způsobil tak nedorozumění. Článek odkrývá skutečnost, že za
úspěšnými projekty stojí vždy jen pár nesnadno nahraditelných osobností
(úkolem marketingu je vytvořit opačný dojem). Je ale potřeba dodat, že
u dobře fungujících open source projektů se pozice těchto osobností
v čase mění. Nejprve jsou to výhradní autoři a programátoři, aby se
časem přesunuli do pozice těch, kteří projekt vedou a dávají mu vizi.
A třeba úplně přestanou psát kód.
Články nebývají kontroverzní svým obsahem, ale nevhodnou dobou
zveřejnění. Ještě než padne první věta, že OpenID je uměle
vyhypovaná záležitost, poprosím všechny, kterým to způsobí
rudé vidění nebo přezíravý povzdech, aby se pokusili článek přečíst
se snahou porozumět.
OpenID je
technologickými fandy uměle vyhypovaná záležitost. Připomíná
vzestup Firefoxe, prohlížeče, který běžným uživatelům nechyběl, ale
který jim jejich počítačově zdatné ratolesti instalovaly místo Exploreru,
a to z důvodů, které spíš než v logice měly oporu v přesvědčení.
Abych nebyl špatně pochopen: je moc dobře, že se Firefox dostal tam, kde
nyní je, ale v době vzestupu to nebyla killer application, dokonce
ani lepší volba, pro masového
uživatele to byl jen krapet pomalejší a hardwarově náročnější
prohlížeč, který uměl zobrazit o něco méně stránek.
Co je vlastně OpenID? Je to technologie, která umožňuje lidem
přihlašovat se na různé weby stejným loginem, bez opakovaných
registrací a vymýšlení hesla. Zbavuje návštěvníky neoblíbených
registračních a přihlašovacích formulářů. Hovoří se o ní jako
o univerzální internetové občance. Přesto o ní mluví jen několik
nadšenců a žádná revoluce se nekoná. Proč?
Uživatelská nepřívětivost
Dnešní prohlížeče velice usnadňují vyplňování klasických
přihlašovacích i registračních formulářů. Nenabízejí však žádnou
podporu pro přihlašování přes OpenID.
Registrační formulář představuje notoricky známý vzor, jehož
vyplnění zvládá běžný uživatel jako samozřejmost (byť se mu to snaží
řada webových tvůrců setsakramentsky zkomplikovat). Prohlížeče si hesla
pamatují a celý proces přihlášení redukují na kliknutí na ikonku nebo
tlačítko, neprobíhá-li automaticky zcela.
Vedle toho registrace přes OpenID je krokem do neznáma vyžadující
značné úsilí. Poprvé jsem si to vyzkoušel na blogu asi největšího popularizátora
OpenID u nás, Martina Malého, který běží na Drupalu. Registrace přes
OpenID se skládala z mnohem více kroků, než registrace klasická, na
některé obrazovky jsem nechápavě zíral a snažil se odhadnout, co se po
mně probůh chce.
Čímž pochopitelně nekritizuju Martina, který byl z chování Drupalu
taky nešťastný. Jde jen o ukázku toho, že Drupal vyvíjejí
programátoři, nikoliv experti na použitelnost. Ano, tyto skupiny
vnímám jako protikladné. Ano, sám jsem
výjimka 🙂
Další problém nastává při přihlašování. Prohlížeč nijak
nespolupracuje, magická hůlka v Opeře nefunguje. Je potřeba kliknout na
ovládací prvek přepínače, ručně vyplnit OpenID login, dostat se na
stránky OpenID providera a tam se lze teprve přihlásit s hůlkou. Pokud se
potřebujete přihlásit v okamžiku, kdy se chystáte odeslat komentář (což
je prakticky ve 100% připadů), spáchá na vás Drupal ještě horší
kulišárnu – komentář si musíte uložit do schránky, manuálně se
přihlásit, poté znovu najít místo, na které reagujete a znovu komentář
vložit.
Samozřejmě lituju toho, že jsem se s OpenID vůbec přihlašoval, a
jelikož to nejde zvrátit, přestal jsem psát komentáře – pro Misantropa
má OpenID nečekané pozitivum ;)
Implementace především
Říkáte, že pláču na špatném hrobě, že argumentace se netýká
OpenID ale jedné zmršené implementace? Máte samozřejmě pravdu. Jde však
o výbornou ukázku toho, jak slibná technologie může být zásadním krokem
zpět z pohledu uživatelů.
Jsem přesvědčen o tom, že budoucnost OpenID závisí na podpoře za
strany prohlížečů. Pokud přijdou s vestavěným OpenID
přihlašováním na jeden klik, bude vyhráno. Aby stačilo přímo
v prohlížeči nastavit svou identitu. Aby nedocházelo k žádným
přesměrováním na providera, aby všechno proběhlo v rámci aktuální
stránky, doprovázeno nanejvýš dialogovým oknem prohlížeče.
Podpora prohlížeče je klíčová i pro vývojáře webových aplikací.
OpenID protokol je šíleně složitý, o schopnosti Běžného Programátora
™ napsat přívětivé chování webové aplikace si nedělám iluze. Pokud se
však opráší cca koncept HTTP autentifikace,
šikovně implementovat ho dokáže i začátečník.
Budou to prohlížeče umět? A kdy?
Bezpečnost (ještě víc)
především
Musím zmínit ještě jednu filosofickou stránku. Dosud byla počítačová
veřejnost vychovávána k tomu, aby na každém webu používala jiné heslo.
Sám jsem to zvládl jen díky udělátku a dnes
skutečně mám všude jiné a velmi silné heslo (a jsem tomu rád).
OpenID razí opačnou filosofii – jedno heslo platí všude.
Je potřeba připustit, že to není s pravidlem „jiné heslo pro každý
web“ v rozporu, protože ono jedno heslo se zadává jen u jednoho OpenID
providera. Na druhou stranu, ztráta takového hesla má řadově větší dopad
a s rozmachem OpenID se dá očekávat, že se útočníci na tyto hesla
zaměří.
Sumárum: dovedu si představit budoucnost v OpenID, ale zatím každému
webdeveloperovi radím, ať je na stránkách nepoužívá. Ale oni stejně
nemají zájem. Třeba stran OpenID nepadl pod článkem o Přihlašování
uživatelů v Nette ani jeden dotaz – a že jsem pár
rýpavých očekával ;)
Slovo dalo slovo a s jedním špičkovým programátorem v Zend Frameworku připravujeme školení
frameworků pro PHP programátory. Já si beru na starost školení Nette Framework s dibi (bo sou lepšejší, ni?). Žádné velké
teoretizování, žádné obecné řeči – chceme vás naučit sekat
kvalitní webové aplikace jako Baťa cvičky!
2 termíny, 2 dny,
2 frameworky
Přesný termín a místo ještě není určené, nicméně školení bude
dvoudenní, pro každý framework samozřejmě zvlášť. Uskuteční se
v Praze. Počet účastníků je omezen, proto nabízím možnost se
předběžně registrovat. Předběžně registrovaní účastníci budou
mít přednost před ostatními. Nyní už je vypsán termín a můžete školení objednávat.
Po účastnících je vyžadována dobrá znalost PHP, naopak znalost
frameworku není potřeba. Rád bych oslovil především firmy, které
pochopily, že takové to nimrání se v PHP nemá smysl a je potřeba tvořit
pořádné weby a to navíc rychle. Na závěr školení bude rituálně smazán
framework, který si firma sama vyvinula 🙂
No, a já letím! Sem.
Kdybyste měli cestu, stavte se.
Nerad bych v reakci na článek Jana Korbela Nejsou
redakční systémy škodlivé?
vypadal jako obchodník, co se jen snaží protlačit vlastní produkt, takže
celou problematiku rozeberu co nejpodrobněji. Cca v roce 2003 jsem absolvoval
podobnou úvahu nad CMS jako Jan, nicméně dospěl jsem k jiným
závěrům.
Po pár letech nasazení redakčního systému u několika klientů jsem
dnes přesvědčen, že redakční systémy škodí jak klientům,
tak nám.
Jsem přesvědčen, že redakční systémy pomáhají jak klientům, tak
nám (tj. dodavatelům CMS). Pro klienta mají obrovskou výhodu v tom, že ho
zbavují překážek při aktualizaci webu. Nemusí nikomu platit a nemusí
nikoho otravovat (viz přes web
nebo operátora?). Mnoho firemních stránek je zanedbaných a
neaktuálních právě kvůli zbytečným překážkám. „Jo, dal bych tam
nový ceník, jenže musím kvůli tomu psát do Prahy, ti se na to vykašlou,
nebo to zvořou, už fakt nemám sílu něco řešit.“ (citace kamaráda,
který mi minulý týden vysvětloval, proč chce pro svou pobočnu velké firmy
vyrobit vlastní stránky).
Problém č.1 – HTML. Nechci, aby se moji klienti museli učit HTML a
nevěřím, že se někdy objeví takový WYSIWYG, který by zmíněné
problémy eliminoval.
Zde s Jenem naprosto souhlasím, navíc však mohu vysvětlit, proč se
takový WYSIWYG objevit ani
nemůže.
Když v InDesignu sázím noviny, není důležité, jestli je titulek
logicky spojen s článkem. Musí to tak jen vizuálně vypadat. Noviny se
vytisknou a zdrojový soubor jde do archívu. Když potřebuji do prezentace
vrazit jednoduchý diagram, stačí mi pár čtverečků v Corelu nebo
Illustratoru a propojit je šipkou. Jako výstup chci dostat to, co
vidím na obrazovce – to je doména WYSIWYG.
Když ale modelujete databáze (nebo plošné spoje, …), tak vizuální
podoba je vedlejší. Jde o logickou strukturu. A ta může mít různé
podoby, podle různých
konvencí. Zde se také skvěle uplatní vizuální editor – ale jako
výstup nechci dostat to, co vidím, ale např. SQL příkaz. Takže se
nejedná o WYSIWYG.
Tvorba webových stránek patří do druhé kategorie. Byl jsem mnohokrát
překvapen, jak tvůrčím způsobem lze znásilňovat webové WYSIWYG editory
(třeba centrovat titulek pomocí obrázků nebo zanořeného seznamu), ale
nikdy bych v tom nehledal chybu uživatelů. Jde totiž o chybu
principiální. Uživatelé se snaží v editoru vytvořit vizuální
uspořádání, ze kterého si logickou strukturu odvodí až mozek. Nakonec tak
používají i Word, i když to prý není „správné“. V případě webu
však chceme jít přesně opačnou cestou, chceme zapisovat logickou strukturu,
ze které se teprve pomocí prohlížeče a CSS vytvoří podoba vizuální
(nebo zvuková, textová a podobně).
Problém č. 2 – Typografie. Sekretářka netuší, že ta oranžová tam
sedí asi jako Bobošíková na Hrad.
A nejen oranžová a nejen sekretářka. Pravidla typografie a rozložení
znaků na klávesnici jsou odvěcí nepřátelé. Znalost rozdílů mezi
pomlčkou, spojovníkem, apostrofem, uvozovkou, trojtečkou a třemi tečkami
sama o sobě nestačí, když na to neexistuje na klávesnici tlačítko.
Problém č. 3 – Ztráta kontaktu. Redakčním systémem se okrádáme
o to, že víme, co se u klienta děje.
Ale prosím vás. Stačí se podívat na klientův web a hned vím, co se
u něj děje. Právě proto, že má redakční systém a může o dění
svobodně informovat. A když vidím, že míří směrem, kde by se mu hodila
anketa nebo video, tak mu to mohu nabídnout. Komunikace se tak stane velmi
trefná.
Jaké existuje řešení?
Ale to přece už víte 🙂 Mé úvahy nad redakčními systémy zavdaly
vzniku Texy!. Na počátku Texy syntaxe byla
prosba k přítelkyni, aby v Notepadu psala, co jí budu diktovat. Součástí
diktátu byly nadpisy, odstavce, odrážky, zvýraznění slova. Nejprve marně
hledala formátovací lištu a příslušné ikonky, jenže musela si poradit
bez nich.
Texy je představitelem koncepce logického editoru. Ale nikoliv
nevizuálního! Fandím snahám vytvořit pro něj vizuální
editor, jenže je to dosud příliš složitý oříšek (i když takový
Amy editor má pořádně
našlápnuto). Bylo by fajn, kdyby se daly například skrývat cíle
hypertextových odkazů, kdyby šlo přehledněji zapisovat tabulky nebo
vnořené odrážky.
Dnes se v Texy dají v pohodě psát celé blogy včetně komentářů
(příkladů jsou stovky), e-shopy (rodina Internet Mall, Vitalita, Pala, …),
firemní stránky. Ironií jsou obavy, že se Texy nenaučí sekretářka, když
jde vlastně o převodník „sekretářka → HTML“. V praxi bylo
nesčetněkrát ověřeno, že sekretářka se naučí s Texy vytvářet
kvalitní kód za hodinu, zatímco s WYSIWYG editorem nikdy.
Taky vám vadí odsunutí vyhledávacích záložek do pryč?
Dál už je odsunout nešlo…
Málo se ví, že za tímto antiergonomickým krokem stojí vážné
pochybení konzultantské společnosti H1, která pro Google mezinárodní
uživatelská testování provádí. Nové umístění záložek se zkoušelo
v bulharské Sofii. V závěrečné zprávě Martina Snížka, jenž si
neuvědomil národnostní rozdíly, se můžeme dočíst:
bod 17.3.b Odsunutí záložek do pryč
Všechny testované subjekty změnu souhlasně odkývali. Odsun
schválen
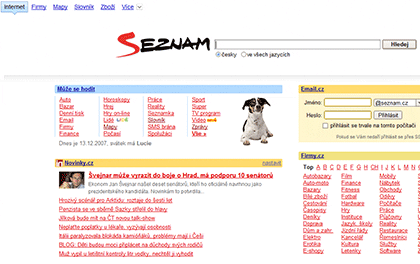
Česká vyhledávací jednička Seznam, známá tím, že jde vždy vlastní
cestou, dnes přivítala uživatele „vylepšeným“ designem:
Seznam.cz implementuje průmyslové standardy
Dvojka Centrum.cz zatím žádnou změnu nechystá. „My kopírujeme Yahoo.
Odsuneme, až odsune Yahoo,“ zabzučel Pavel Mucha, výkonný ředitel
společnosti NetCentrum.
Jak napravit kiks Martina
Snížka?
Uživatelé Firefoxu, máte to jako obvykle celkem snadné. Stáhněte si
rozšíření Stylish, které
umí upravovat styly jednotlivých stránek. Stiskněte tlačítko
Write... a vložte nový styl:
/* Google old-style bar by dgx */
@-moz-document domain(www.google.com), domain(www.google.cz),
domain(images.google.com), domain(images.google.cz){
#gbh {
border-top: white !important ;
}
#gbar {
position: absolute !important;
left: 1% !important;
top: 152px !important;
width: 98% !important;
text-align: center !important;
}
}
@-moz-document url-prefix(http://www.google.com/search?),
url-prefix(http://www.google.cz/search?),
url-prefix(http://images.google.com/images?),
url-prefix(http://images.google.cz/images?) {
#gbar {
position: absolute !important;
left: 165px !important;
top: 35px !important;
width: 40em !important;
text-align: left !important;
}
}
Jak podobnou věc vyřešit
v IE nebo Opeře netuším. Ale od toho tu mám komentátory ;)
Proč bez společné domény? Myšlence společné domény jsem
fandil – více projektů pod jednou střechou působí seriózněji, produkty
jsou marketingově výborně provázané. Jenže to platí pro komerční
software. Open source má jiné zákonitosti. Víte, že Ruby on Rails a jQuery
vytvořil stejný programátor?
Prospěl by jim přesun na společný web?
Ve prospěch samostatných domén rozhodla srozumitelnost URL
(viz dále).
Proč tvar {project}php.com? Protože varianty bez ‚php‘ jsou
obsazené. Vlastně si myslím, že s tím ‚php‘ je to
i výstižnějí.
Proč v názvu není dgx? Je hloupost se při vymýšlení názvu
nechat omezovat něčím, co ve skutečnosti není důležité nebo nemá
žádnou hodnotu. Kombinace písmen dgx vznikla z týchž
důvodů, jako ovx.
Její má-li nějaké přednosti, tak po našroubování do tvaru
dgxphp.com se změní v zápory.
Proč ne nette.dgx.cz? Protože jazykově nezávislý web
je lepší umístit na jazykově nezávislou doménu. Nelíbí se mi
cosi.cz/en/.
Proč ne nette-php.com? Pokud existuje varianta
s pomlčkou (či spíše spojovníkem) i bez, mívám pocit, že ta bez
pomlčky je originál a pomlčková pouze cizopasí. Samozřejmě, že realita
je daleko barevnější. Nejlepší je asi zaregistrovat obě varianty a
přesměrovat na bezpomlčkovou.
Google bere nettephp jako jedno slovo. Ať si
bere 🙂
Proč .com? To je podobná situace jako s pomlčkami.
Sice každá TLD má teoreticky
jiný význam, v praxi se ale vžilo, že .com je „nej“, kdo
ji neukořistí zkusí .org nebo .net, a teprve pak
následují .info nebo podivná .biz. (Samozřejmě
pro české projekty je na prvním místě .cz.)
Proč bez www.? Vždy je lepší varianta s
www, protože v myslích lidí www = internet. Existuje jedna
výjimka: web zaměřený na pokročilé uživatele a webové vývojáře. To je
i můj případ a zvolil jsem variantu o šest vé kratší ;)
Více domén znamená vyšší náklady. Zahraniční domény kupuju
u DomainSite, registrátora, co má
jako favikonku logo Tuzexu. Při ceně $6.99 za rok je doména levnější než
donášková pizza. Asi si jen oběd
odpustím ;)
A co náklady za hosting & pracnější údržba více webů? To
je právě ten fór! Arthur Dent mi doporučil hostmonster.com, což je na
české poměry nesmírně zajímavý hosting. Zaplatíte si jeden tarif,
dostanete 600 GB prostoru a tam si nasměrujete libovolný počet
domén a subdomén. Reálně udržuji a platím jedno úložiště.
Hostmonster je pozoruhodný i po technické stránce. Vlastně ji do teď
pořádně nechápu. PHP se konfiguruje přímo editací php.ini,
lze tam nějak přidávat i vlastní binární rozšíření (třeba Zend
Optimizer), zdá se, že přes FTP si můžete zálohovat datové soubory
s emaily atd. Až bude někdy čas, musím to lépe prozkoumat.
Srozumitelné URL
Zmínil jsem se o srozumitelných URL, takže abych to vysvětlil.
Chápu pod tím něco jiného, než co představují tzv. cool URL.
I když asi původně měl být význam stejný, dnes jsou cool URL synonymem
pro použití textového identifikátoru namísto číselného. Srozumitelnost
nesrozumitelnost. Tragikomickým příkladem urputné snahy o „kůl adresy“
je třeba
https://web.archive.org/web/20071219111553/http://www.certodej.cz:80/view/web-os-dal-bomba-jej.
Srozumitelnost vnímám jinak. Příklad: nejspíš jste asi postřehli, že
se změnou hostingu jsem přesunul tento blog na samostatnou subdoménu
(změňte si prosím odkazy) a upravil URL:
Adresy byly „kůl“ už předtím, ale srozumitelné se staly až po
odstranění zbytečných (item) a matoucích (trine)
segmentů.
Domény běží, co dál?
Open source nemusí mít otevřený jen zdrojový kód, baví mě otevřeně
řešit i věci kolem. Takže další otázkou je, jaký zvolit bugtracking
systém, jaké fórum, kam umístit SVN a jak to všechno provázat.
SVN mám zatím umístěné na svém disku a synchronizuji je s Googlem (https://github.com/dg/texy a https://github.com/dg/dibi). Pro
bugtracking se dá jakžtakž použít i obyčejné fórum, ale raději bych
k tomu určenou aplikaci, nejlépe napsanou v PHP (tedy nikoliv Trac). Stále
je ve hře možnost napsat něco vlastního, třeba jako demonstraci Nette.
Nezdá se mi to složité, jen by to trvalo déle.